
2.4: Fitting Linear Models to Data
- Page ID
- 13415

Learning Objectives
- Draw and interpret scatter diagrams.
- Use a graphing utility to find the line of best fit.
- Distinguish between linear and nonlinear relations.
- Fit a regression line to a set of data and use the linear model to make predictions.
A professor is attempting to identify trends among final exam scores. His class has a mixture of students, so he wonders if there is any relationship between age and final exam scores. One way for him to analyze the scores is by creating a diagram that relates the age of each student to the exam score received. In this section, we will examine one such diagram known as a scatter plot.
Drawing and Interpreting Scatter Plots
A scatter plot is a graph of plotted points that may show a relationship between two sets of data. If the relationship is from a linear model, or a model that is nearly linear, the professor can draw conclusions using his knowledge of linear functions. Figure \(\PageIndex{1}\) shows a sample scatter plot.
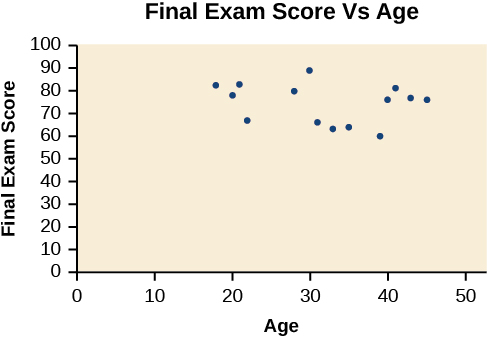
Notice this scatter plot does not indicate a linear relationship. The points do not appear to follow a trend. In other words, there does not appear to be a relationship between the age of the student and the score on the final exam.
Example \(\PageIndex{1}\): Using a Scatter Plot to Investigate Cricket Chirps
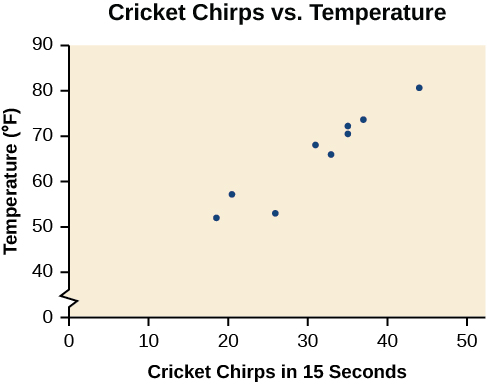
Table shows the number of cricket chirps in 15 seconds, for several different air temperatures, in degrees Fahrenheit[1]. Plot this data, and determine whether the data appears to be linearly related.
| Chirps | 44 | 35 | 20.4 | 33 | 31 | 35 | 18.5 | 37 | 26 |
| Temperature | 80.5 | 70.5 | 57 | 66 | 68 | 72 | 52 | 73.5 | 53 |
Solution
Plotting this data, as depicted in Figure \(\PageIndex{2}\) suggests that there may be a trend. We can see from the trend in the data that the number of chirps increases as the temperature increases. The trend appears to be roughly linear, though certainly not perfectly so.
Finding the Line of Best Fit
Once we recognize a need for a linear function to model that data, the natural follow-up question is “what is that linear function?” One way to approximate our linear function is to sketch the line that seems to best fit the data. Then we can extend the line until we can verify the y-intercept. We can approximate the slope of the line by extending it until we can estimate the \(\frac{\text{rise}}{\text{run}}\).
Example \(\PageIndex{2}\): Finding a Line of Best Fit
Find a linear function that fits the data in Table \(\PageIndex{1}\) by “eyeballing” a line that seems to fit.
Solution
On a graph, we could try sketching a line.
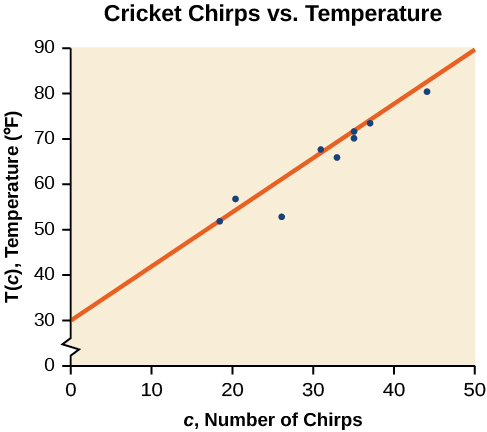
Using the starting and ending points of our hand drawn line, points \((0, 30)\) and \((50, 90)\), this graph has a slope of
\[m=\dfrac{60}{50}=1.2\]
and a y-intercept at 30. This gives an equation of
\[T(c)=1.2c+30\]
where \(c\) is the number of chirps in 15 seconds, and \(T(c)\) is the temperature in degrees Fahrenheit. The resulting equation is represented in Figure \(\PageIndex{3}\).
Analysis
This linear equation can then be used to approximate answers to various questions we might ask about the trend.
Recognizing Interpolation or Extrapolation
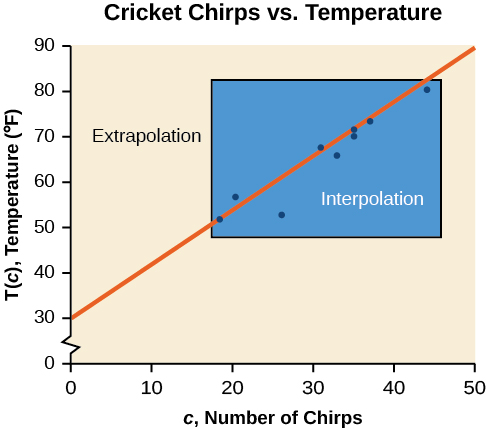
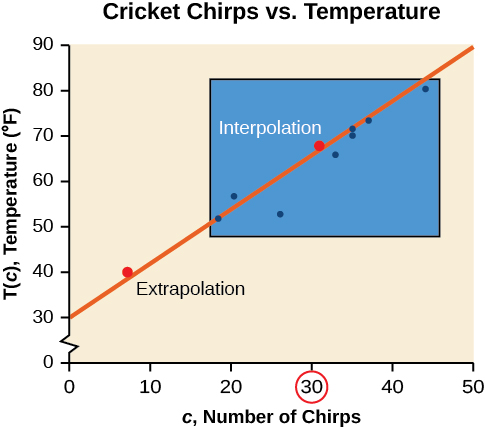
While the data for most examples does not fall perfectly on the line, the equation is our best guess as to how the relationship will behave outside of the values for which we have data. We use a process known as interpolation when we predict a value inside the domain and range of the data. The process of extrapolation is used when we predict a value outside the domain and range of the data.
Figure \(\PageIndex{4}\) compares the two processes for the cricket-chirp data addressed in Example \(\PageIndex{2}\). We can see that interpolation would occur if we used our model to predict temperature when the values for chirps are between 18.5 and 44. Extrapolation would occur if we used our model to predict temperature when the values for chirps are less than 18.5 or greater than 44.
There is a difference between making predictions inside the domain and range of values for which we have data and outside that domain and range. Predicting a value outside of the domain and range has its limitations. When our model no longer applies after a certain point, it is sometimes called model breakdown. For example, predicting a cost function for a period of two years may involve examining the data where the input is the time in years and the output is the cost. But if we try to extrapolate a cost when \(x=50\), that is in 50 years, the model would not apply because we could not account for factors fifty years in the future.
Interpolation and Extrapolation
Different methods of making predictions are used to analyze data.
- The method of extrapolation involves predicting a value outside the domain and/or range of the data.
- Model breakdown occurs at the point when the model no longer applies.
Example \(\PageIndex{3}\): Understanding Interpolation and Extrapolation
Use the cricket data from Table \(\PageIndex{1}\) to answer the following questions:
- Would predicting the temperature when crickets are chirping 30 times in 15 seconds be interpolation or extrapolation? Make the prediction, and discuss whether it is reasonable.
- Would predicting the number of chirps crickets will make at 40 degrees be interpolation or extrapolation? Make the prediction, and discuss whether it is reasonable.
Solution
a. The number of chirps in the data provided varied from 18.5 to 44. A prediction at 30 chirps per 15 seconds is inside the domain of our data, so would be interpolation. Using our model:
\[\begin{align} T(30)&=30+1.2(30) \\ &=66 \text{ degrees} \end{align}\]
Based on the data we have, this value seems reasonable.
b. The temperature values varied from 52 to 80.5. Predicting the number of chirps at 40 degrees is extrapolation because 40 is outside the range of our data. Using our model:
\[\begin{align} 40&=30+1.2c \\ 10&=1.2c \\ c&\approx8.33 \end{align}\]
We can compare the regions of interpolation and extrapolation using Figure \(\PageIndex{5}\).
Analysis
Our model predicts the crickets would chirp 8.33 times in 15 seconds. While this might be possible, we have no reason to believe our model is valid outside the domain and range. In fact, generally crickets stop chirping altogether below around 50 degrees.
Exercise \(\PageIndex{1}\)
According to the data from Table \(\PageIndex{1}\), what temperature can we predict it is if we counted 20 chirps in 15 seconds?
Solution
54°F
Finding the Line of Best Fit Using a Graphing Utility
While eyeballing a line works reasonably well, there are statistical techniques for fitting a line to data that minimize the differences between the line and data values[2]. One such technique is called least squares regression and can be computed by many graphing calculators, spreadsheet software, statistical software, and many web-based calculators[3]. Least squares regression is one means to determine the line that best fits the data, and here we will refer to this method as linear regression.
![]() Given data of input and corresponding outputs from a linear function, find the best fit line using linear regression.
Given data of input and corresponding outputs from a linear function, find the best fit line using linear regression.
- Enter the input in List 1 (L1).
- Enter the output in List 2 (L2).
- On a graphing utility, select Linear Regression (LinReg).
Example \(\PageIndex{4}\): Finding a Least Squares Regression Line
Find the least squares regression line using the cricket-chirp data in Table \(\PageIndex{1}\).
Solution
Enter the input (chirps) in List 1 (L1).
Enter the output (temperature) in List 2 (L2). See Table \(\PageIndex{2}\).
| L1 | 44 | 35 | 20.4 | 33 | 31 | 35 | 18.5 | 37 | 26 |
| L2 | 80.5 | 70.5 | 57 | 66 | 68 | 72 | 52 | 73.5 | 53 |
On a graphing utility, select Linear Regression (LinReg). Using the cricket chirp data from earlier, with technology we obtain the equation:
\[T(c)=30.281+1.143c\]
Analysis
Notice that this line is quite similar to the equation we “eyeballed” but should fit the data better. Notice also that using this equation would change our prediction for the temperature when hearing 30 chirps in 15 seconds from 66 degrees to:
\[\begin{align} T(30)&=30.281+1.143(30) \\ &=64.571 \\ &\approx 64.6 \text{ degrees} \end{align}\]
The graph of the scatter plot with the least squares regression line is shown in Figure \(\PageIndex{6}\).
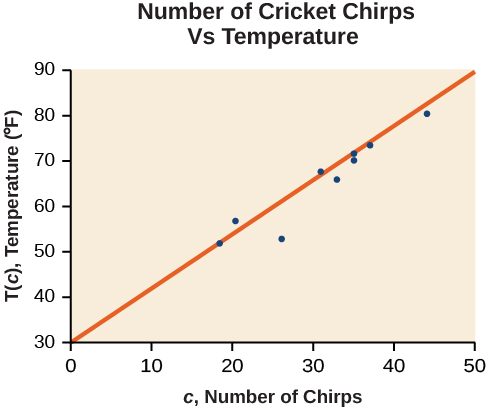
![]() Will there ever be a case where two different lines will serve as the best fit for the data?
Will there ever be a case where two different lines will serve as the best fit for the data?
No. There is only one best fit line.
Distinguishing Between Linear and Non-Linear Models
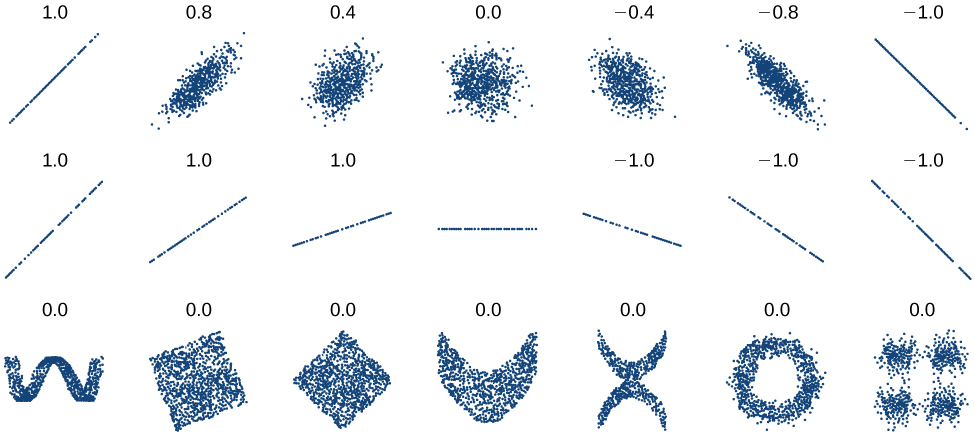
As we saw above with the cricket-chirp model, some data exhibit strong linear trends, but other data, like the final exam scores plotted by age, are clearly nonlinear. Most calculators and computer software can also provide us with the correlation coefficient, which is a measure of how closely the line fits the data. Many graphing calculators require the user to turn a ”diagnostic on” selection to find the correlation coefficient, which mathematicians label as \(r\). The correlation coefficient provides an easy way to get an idea of how close to a line the data falls.
We should compute the correlation coefficient only for data that follows a linear pattern or to determine the degree to which a data set is linear. If the data exhibits a nonlinear pattern, the correlation coefficient for a linear regression is meaningless. To get a sense for the relationship between the value of \(r\) and the graph of the data, Figure \(\PageIndex{7}\) shows some large data sets with their correlation coefficients. Remember, for all plots, the horizontal axis shows the input and the vertical axis shows the output.
Correlation Coefficient
The correlation coefficient is a value, \(r\), between –1 and 1.
- \(r>0\) suggests a positive (increasing) relationship
- \(r<0\) suggests a negative (decreasing) relationship
- The closer the value is to 0, the more scattered the data.
- The closer the value is to 1 or –1, the less scattered the data is.
Example \(\PageIndex{5}\): Finding a Correlation Coefficient
Calculate the correlation coefficient for cricket-chirp data in Table \(\PageIndex{1}\).
Solution
Because the data appear to follow a linear pattern, we can use technology to calculate \(r\). Enter the inputs and corresponding outputs and select the Linear Regression. The calculator will also provide you with the correlation coefficient, \(r=0.9509\). This value is very close to 1, which suggests a strong increasing linear relationship.
Note: For some calculators, the Diagnostics must be turned "on" in order to get the correlation coefficient when linear regression is performed: [2nd]>[0]>[alpha][x–1], then scroll to DIAGNOSTICSON.
Predicting with a Regression Line
Once we determine that a set of data is linear using the correlation coefficient, we can use the regression line to make predictions. As we learned above, a regression line is a line that is closest to the data in the scatter plot, which means that only one such line is a best fit for the data.
Example \(\PageIndex{6}\): Using a Regression Line to Make Predictions
Gasoline consumption in the United States has been steadily increasing. Consumption data from 1994 to 2004 is shown in Table \(\PageIndex{3}\). Determine whether the trend is linear, and if so, find a model for the data. Use the model to predict the consumption in 2008.
| Year | '94 | '95 | '96 | '97 | '98 | '99 | '00 | '01 | '02 | '03 | '04 |
| Consumption (billions of gallons) | 113 | 116 | 118 | 119 | 123 | 125 | 126 | 128 | 131 | 133 | 136 |
The scatter plot of the data, including the least squares regression line, is shown in Figure \(\PageIndex{8}\).
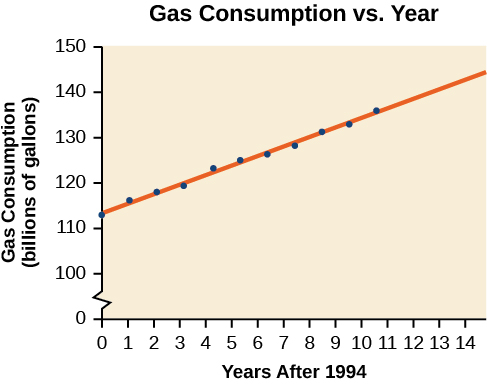
We can introduce new input variable, \(t\),representing years since 1994.
The least squares regression equation is:
\[C(t)=113.318+2.209t\]
Using technology, the correlation coefficient was calculated to be 0.9965, suggesting a very strong increasing linear trend.
Using this to predict consumption in 2008 \((t=14)\),
\[\begin{align} C(14)&=113.318+2.209(14) \\ &=144.244 \end{align}\]
The model predicts 144.244 billion gallons of gasoline consumption in 2008.
Exercise \(\PageIndex{1}\)
Use the model we created using technology in Example \(\PageIndex{6}\) to predict the gas consumption in 2011. Is this an interpolation or an extrapolation?
- Answer
-
150.871 billion gallons; extrapolation
Key Concepts
- Scatter plots show the relationship between two sets of data.
- Scatter plots may represent linear or non-linear models.
- The line of best fit may be estimated or calculated, using a calculator or statistical software.
- Interpolation can be used to predict values inside the domain and range of the data, whereas extrapolation can be used to predict values outside the domain and range of the data.
- The correlation coefficient, \(r\), indicates the degree of linear relationship between data.
- A regression line best fits the data.
- The least squares regression line is found by minimizing the squares of the distances of points from a line passing through the data and may be used to make predictions regarding either of the variables.