
16.3: Simulating Dynamics of Networks
- Page ID
- 7866

Dynamics of networks models capture completely different kinds of network dynamics, i.e., changes in network topologies. This includes the addition and removal of nodes and edges over time. As discussed in the previous chapter, such dynamic changes of the system’s topology itself are quite unusual from a traditional dynamical systems viewpoint, because they would make it impossible to assume a well-defined static phase space of the system. But permitting such topological changes opens up a whole new set of possibilities to model various natural and social phenomena that were hard to capture in conventional dynamical systems frameworks, such as:
- Evolutionary changes of gene regulatory and metabolic networks
- Self-organization and adaptation of food webs
- Social network formation and evolution
- Growth of infrastructure networks (e.g., traffic networks, power grids, the Internet, WWW)
- Growth of scientific citation networks
As seen above, growth and evolution of networks in society are particularly well studied using dynamics of network models. This is partly because their temporal changes take place much faster than other natural networks that change at ecological/evolutionary time scales, and thus researchers can compile a large amount of temporal network data relatively easily.
One iconic problem that has been discussed about social networks is this: Why is our world so “small” even though there are millions of people in it? This was called the “small world” problem by social psychologist Stanley Milgram, who experimentally demonstrated this through his famous “six degrees of separation” experiment in the 1960s [71]. This empirical fact, that any pair of human individuals in our society is likely to be connected through a path made of only a small number of socialties, has been puzzling many people, including researchers. This problem doesn’t sound trivial, because we usually have only the information about local social connections around ourselves, without knowing much about how each one of our acquaintances is connected to the rest of the world. But it is probably true that you are connected to, say, the President of the United States by fewer than ten social links.
This small-world problem already had a classic mathematical explanation. If the network is purely random, then the average distance between pairs of nodes are extremely small. In this sense, Erdős–Rényi random graph models were already able to explain the small-world problem beautifully. However, there is an issue with this explanation: How come a person who has local information only can get connected to individuals randomly chosen from the entire society, who might be living on the opposite side of the globe? This is a legitimate concern because, after all, most of our social connections are within a close circle of people around us. Most social connections are very local in both geographical and social senses, and there is no way we can create a truly random network in the real world. Therefore, we need different kinds of mechanisms by which social networks change their topologies to acquire the “small-world” property.
In the following, we will discuss two dynamics of networks models that can nicely explain the small-world problem in more realistic scenarios. Interestingly, these models were published at about the same time, in the late 1990s, and both contributed greatly to the establishment of the new field of network science.
Small-world networks by Random edge rewiring
In 1998, Duncan Watts and Steven Strogatz addressed this paradox, that social networks are “small” yet highly clustered locally, by introducing the small-world network model [56]. The Watts-Strogatz model is based on a random edge rewiring procedure to gradually modify network topology from a completely regular, local, clustered topology to a completely random, global, unclustered one. In the middle of this random rewiring process, they found networks that had the “small-world” property yet still maintained locally clustered topologies. They named these networks “small-world” networks. Note that having the “small-world” property is not a sufficient condition for a network to be called “small-world” in Watts-Strogatz sense. The network should also have high local clustering.
Watts and Strogatz didn’t propose their random edge rewiring procedure as a dynamical process over time, but we can still simulate it as a dynamics on networks model. Here are their original model assumptions:
- The initial network topology is a ring-shaped network made of n nodes. Each node is connected to \(k\) nearest neighbors (i.e., \(k/2\) nearest neighbors clockwise and \(k/2\) nearest neighbors counterclockwise) by undirected edges.
- Each edge is subject to random rewiring with probability \(p\). If selected for random rewiring, one of the two ends of the edge is reconnected to a node that is randomly chosen from the whole network. If this rewiring causes duplicate edges, the rewiring is canceled.
Watts and Strogatz’s original model did the random edge rewiring (step 2 above) by sequentially visiting each node clockwise. But here, we can make a minor revision to the model so that the edge rewiring represents a more realistic social event, such as a random encounter at the airport of two individuals who live far apart from each other, etc. Here are the new, revised model assumptions:
- The initial network topology is the same as described above.
- In each edge rewiring event, a node is randomly selected from the whole network. The node drops one of its edges randomly, and then creates a new edge to a new node that is randomly chosen from the whole network (excluding those to which the node is already connected).
This model captures essentially the same procedure as Watts and Strogatz’s, but the rewiring probability \(p\) is now represented implicitly by the length of the simulation. If the simulation continues indefinitely, then the network will eventually become completely random. Such a dynamical process can be interpreted as a model of social evolution in which an initially locally clustered society gradually accumulates more and more global connections that are caused by rare, random long-range encounters among people.
Let’s simulate this model using Python. When you simulate the dynamics of networks, one practical challenge is how to visualize topological changes of the network. Unlike node states that can be easily visualized using colors, network topology is the shape of the network itself, and if the shape of the network is changing dynamically, we also need to simulate the physical movement of nodes in the visualization space as well. This is just for aesthetic visualization only, which has nothing to do with the real science going on in the network. But an effective visualization often helps us better understand what is going on in the simulation, so let’s try some fancy animation here. Fortunately, NetworkX’s spring_layout function can be used to update the current node positions slightly. For example:

This code calculates a new set of node positions by using g.pos as the initial positions and by applying the Fruchterman-Reingold force-directed algorithm to them for just five steps. This will effectively simulate a slight movement of the nodes from their current positions, which can be utilized to animate the topological changes smoothly.
Here is an example of the completed simulation code for the small-world network formation by random edge rewiring:




The initialize function creates a ring-shaped network topology by connecting each node to its k nearest neighbors (\(j ∈ {1,...,k/2}\)). “% n” is used to confine the names of nodes to the domain \([0,n−1]\) with periodic boundary conditions. An additional attribute g.count is also created in order to count time steps between events of topological changes. In the update function, g.count is incremented by one, and the random edge rewiring is simulated in every 20 steps as follows: First, node i is randomly chosen, and then one of its connections is removed. Then node i itself and its neighbors are removed from the candidate node list. A new edge is then created between i and a node randomly chosen from the remaining candidate nodes. Finally, regardless of whether a random edge rewiring occurred or not, node movement is simulated using the spring_layout function.
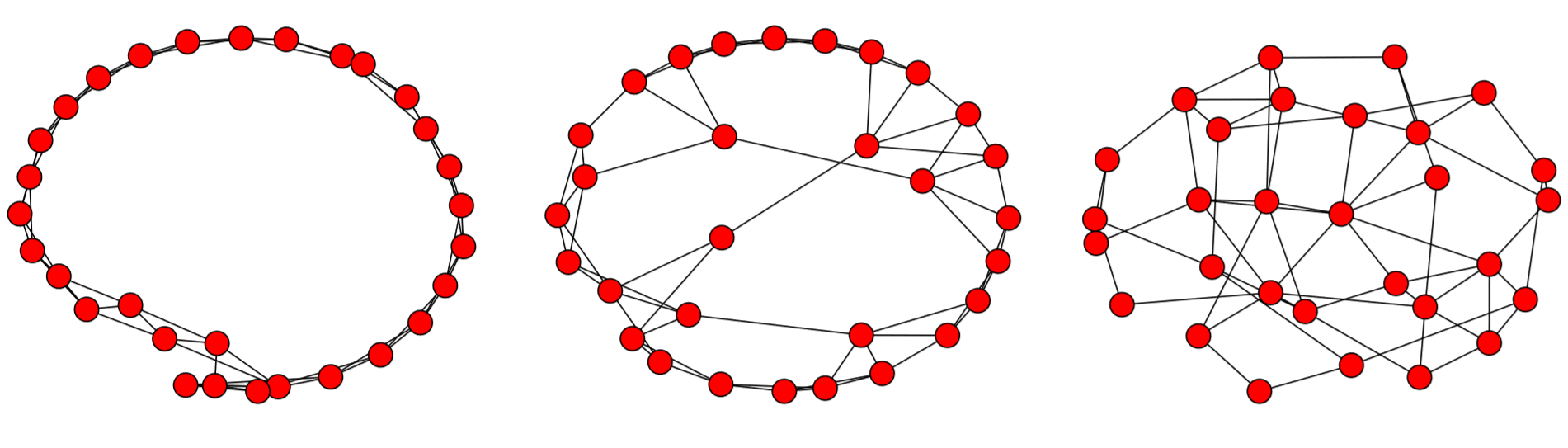
Running this code will give you an animated process of random edge rewiring, which gradually turns a regular, local, clustered network to a random, global, unclustered one (Fig. 16.3.1). Somewhere in this network dynamics, you will see the Watts-Strogatz smallworld network arise, but just temporarily (which will be discussed further in the next chapter).N
Revise the small-world network formation model above so that the network is initially at two-dimensional grid in which each node is connected to its four neighbors (north, south, east, and west; except for those on the boundaries of the space). Then run the simulations, and see how random edge rewiring changes the topology of the network.
For your information, NetworkX already has a built-in graph generator function for Watts-Strogatz small-world networks, watts_strogatz_graph(n, k, p). Here, n is the number of nodes, k is the degree of each node, and p is the edge rewiring probability. If you don’t need to simulate the formation of small-world networks iteratively, you should just use this function instead.
Scale-free networks by preferential attachment
The Watts-Strogatz small-world network model brought about a major breakthrough in explaining properties of real-world networks using abstract network models. But of course, it was not free from limitations. First, their model required a “Goldilocks” rewiring probability \(p\) (or such a simulation length in our revised model) in order to obtain a small-world network. This means that their model couldn’t explain how such an appropriate \(p\) would be maintained in real social networks. Second, the small-world networks generated by their model didn’t capture one important aspect of real-world networks: heterogeneity of connectivities. In every level of society,we often find a few very popular people as well as many other less-popular, “ordinary” people. In other words, there is always great variation in node degrees. However, since the Watts-Strogatz model modifies an initially regular graph by a series of random rewirings, the resulting networks are still quite close to regular, where each node has more or less the same number of connections. This is quite different from what we usually see in reality.
Just one year after the publication of Watts and Strogatz’s paper, Albert-L´aszl´o Barab´asi and R´eka Albert published another very influential paper [57] about a new model that could explain both the small-world property and large variations of node degrees in a network. The Barab´asi-Albert model described self-organization of networks over time caused by a series of network growth events with preferential attachment. Their model assumptions were as follows:
1. The initial network topology is an arbitrary graph made of \(m_0\) nodes. There is no specific requirement for its shape, as long as each node has at least one connection (so its degree is positive).
2. In each network growth event, a newcomer node is attached to the network by \(m\) edges \((m ≤ m_0)\). The destination of each edge is selected from the network of existing nodes using the following selection probabilities:
\[p(i)= \frac{\deg{(1)}}{\sum{\deg(j)}_{j}} \label{(16.16)} \]
This preferential attachment mechanism captures “the rich get richer” effect in the growth of systems, which is often seen in many socio-economical, ecological, and physical processes. Such cumulative advantage is also called the “Matthew effect” in sociology. What Barab´asi and Albert found was that the network growing with this simple dynamical rule will eventually form a certain type of topology in which the distribution of the node degrees follows a power law
\[P(k) \approx{k}^{-\gamma}, \label{(16.17)} \]
where \(P(k)\) is the probability for a node to have degree \(k\), and \(−γ \) is the scaling exponent (\(γ = 3\) in the Barab´asi-Albert model). Since the exponent is negative, this distribution means that most nodes have very small \(k\), while only a few nodes have large \(k\) (Fig. 16.10). But the key implication is that such super-popular “hub” nodes do exist in this distribution, which wouldn’t be possible if the distribution was a normal distribution, for example. This is because a power law distribution has a long tail (also called a fat tail, heavy tail, etc.), in which the probability goes down much more slowly than in the tail of a normal distribution as \(k\) gets larger. Barab´asi and Albert called networks whose degree distributions follow a power law scale-free networks, because there is no characteristic “scale” that stands out in their degree distributions.
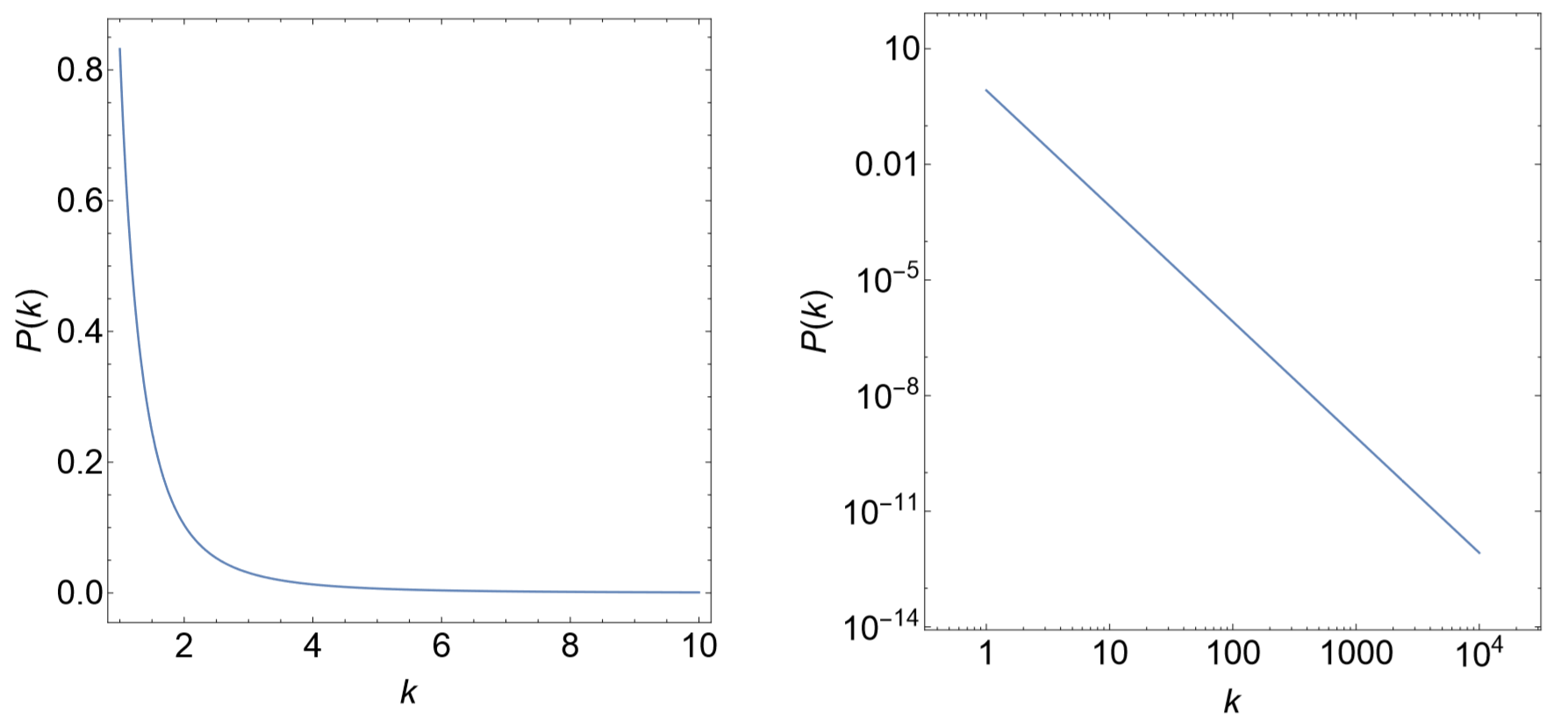 Figure \(\PageIndex{2}\):Plots of the power law distribution \(P(k) ∼ k^{γ}\) with \(γ = 3\). Left: In linear scales. Right: In log-log scales.
Figure \(\PageIndex{2}\):Plots of the power law distribution \(P(k) ∼ k^{γ}\) with \(γ = 3\). Left: In linear scales. Right: In log-log scales.
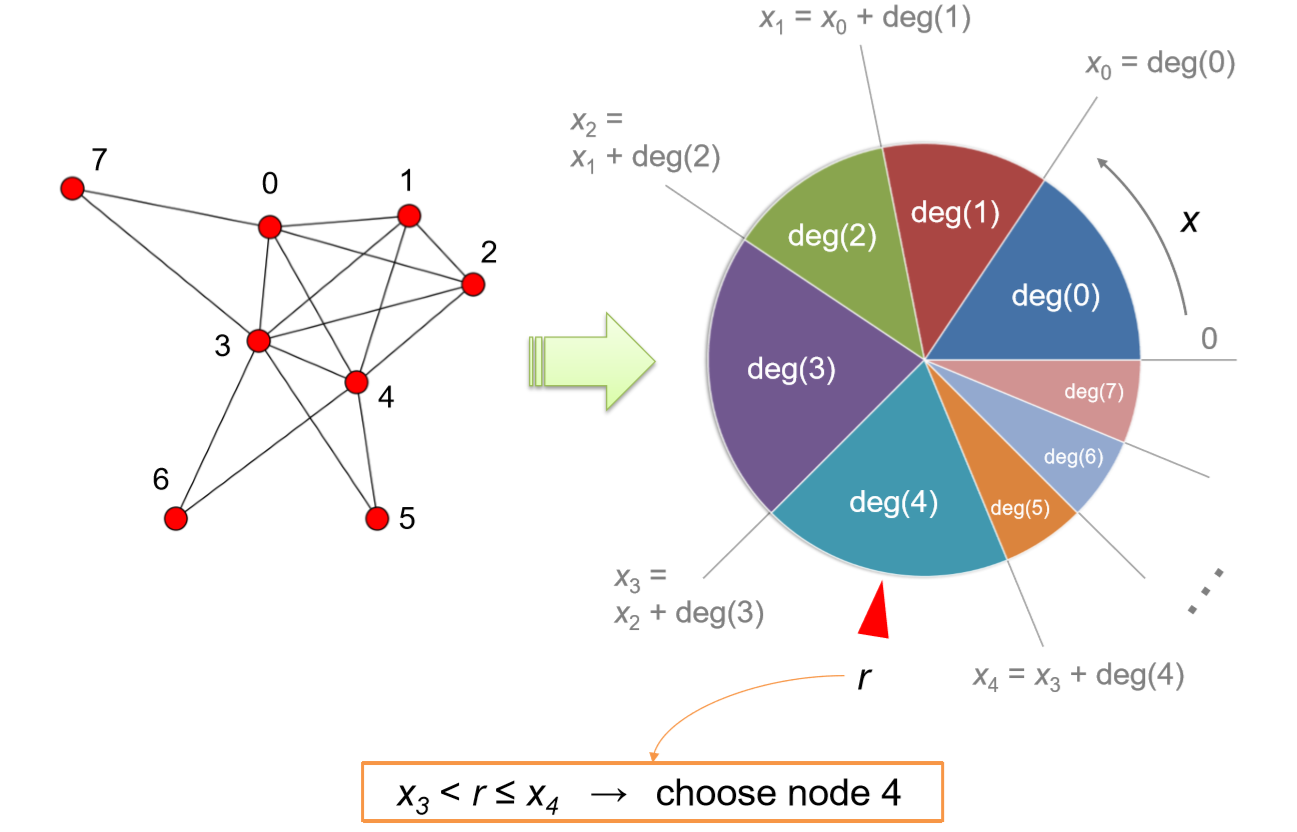
The network growth with preferential attachments is an interesting, fun process to simulate. We can reuse most of Code 16.10 for this purpose as well. One critical component we will need to newly define is the preferential node selection function that randomly chooses a node based on node degrees. This can be accomplished by roulette selection, i.e., creating a “roulette” from the node degrees and then deciding which bin in the roulette a randomly generated number falls into. In Python, this preferential node selection function can be written as follows:


With this preferential node selection function, the completed simulation code looks like this:

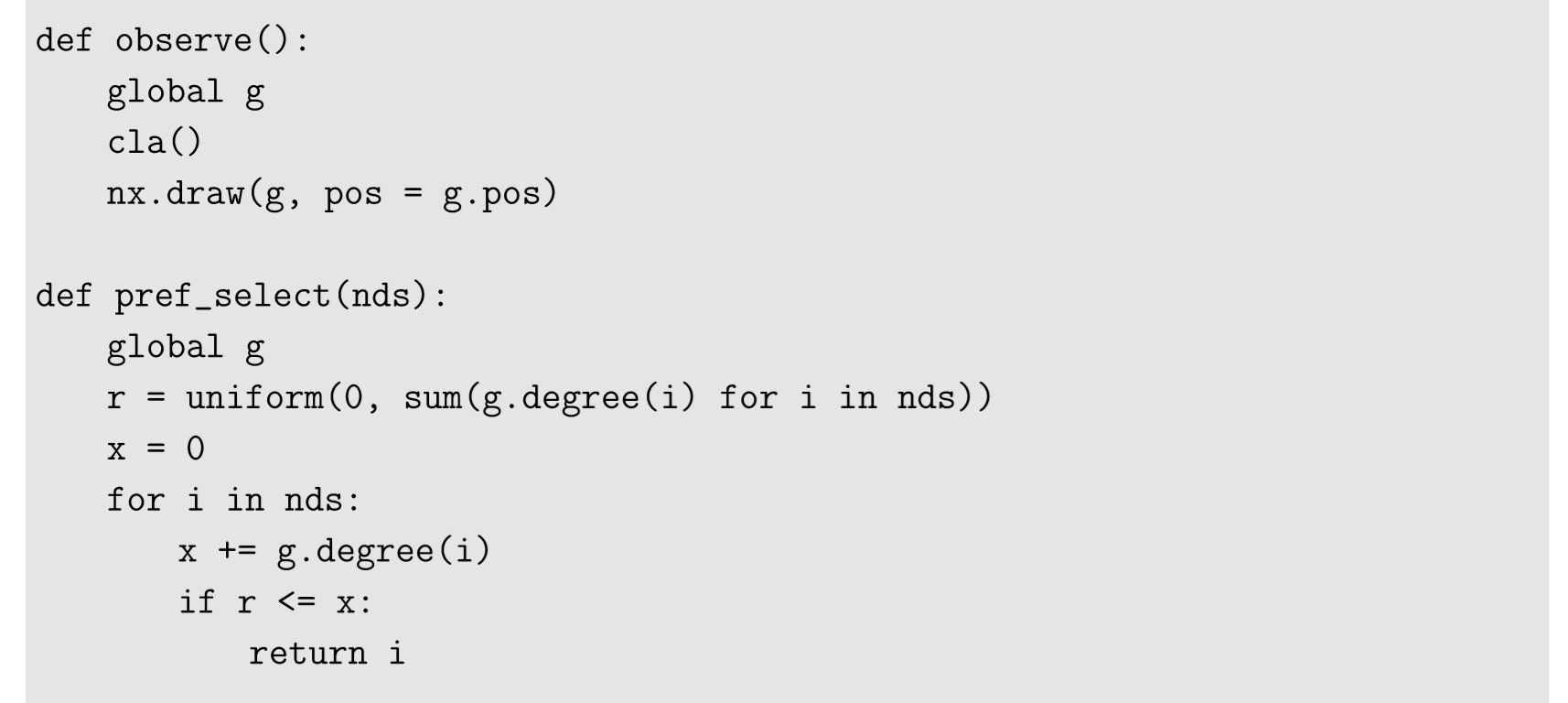



In this sample code, the network growth starts with a five-node complete graph. Each time a newcomer node is added to the network, two new edges are established. Note that every time an edge is created between the newcomer and an existing node j, node j is removed from the candidate list nds so that no duplicate edges will be created. Finally, a new position (0, 0) for the newcomer is added to g.pos. Since g.pos is a Python dictionary, a new entry can be inserted just by using newcomer as a key.
Figure 16.12 shows a typical simulation result in which you see highly connected hub nodes spontaneously arise. When you continue this simulation long enough, the resulting distribution of node degrees comes closer to a power law distribution with γ = 3.
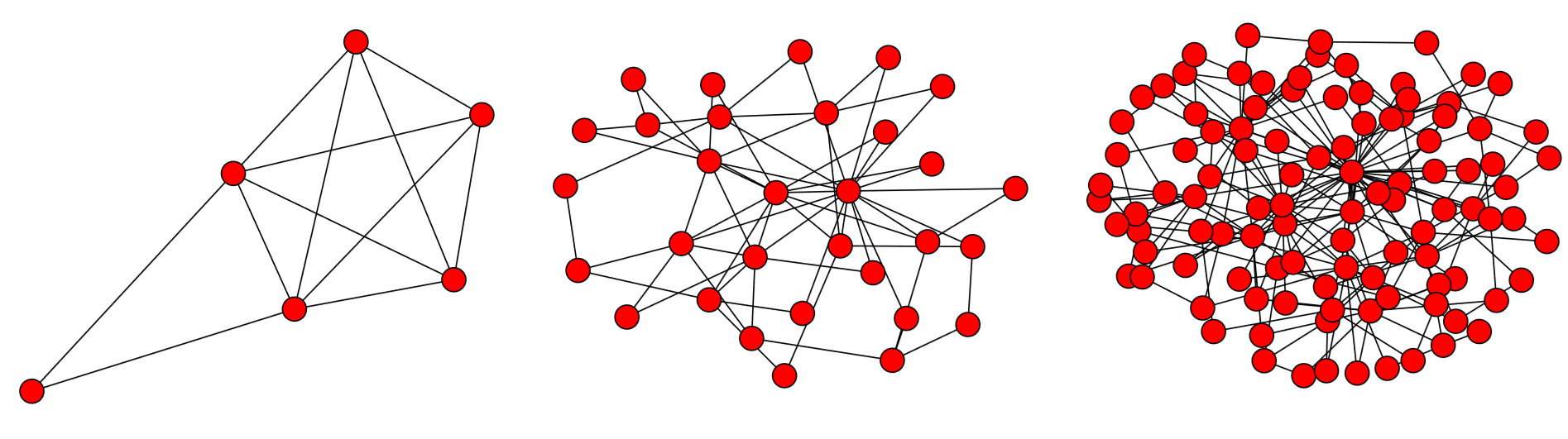
Simulate the Barab´asi-Albert network growth model with \(m = 1\), \(m = 3\), and \(m = 5\), and see how the growth process may be affected by the variation of this parameter.
Modify the preferential node selection function so that the node selection probability \(p(i)\) is each of the following:
- independent of the node degree (random attachment)
- proportional to the square of the node degree(strong preferential attachment)
- inversely proportional to the node degree (negative preferential attachment) Conduct simulations for these cases and compare the resulting network topologies.
Note that NetworkX has a built-in graph generator function for the Barab´asi-Albert scale-free networks too, called barabasi_albert_graph(n, m). Here, n is the number of nodes, and m the number of edges by which each newcomer node is connected to the network.
Here are some more exercises of dynamics of networks models, for your further exploration:
This example is a somewhat reversed version of the Watts-Strogatz small-world network model. Instead of making a local, clustered network to a global, unclustered network, we can consider a dynamical process that makes an unclustered network more clustered over time. Here are the rules:
- The network is initially random, e.g., an Erd˝os-R´enyi random graph.
- In each iteration, a two-edge path (A-B-C) is randomly selected from the network.
- If there is no edge between A and C, one of them loses one of its edges (but not the one that connects to B), and A and C are connected to each other instead.
This is an edge rewiring process that closes a triangle among A, B, and C, promoting what is called a triadic closure in sociology. Implement this edge rewiring model, conduct simulations, and see what kind of network topology results from this triadic closure rule. You can also combine this rule with the random edge rewiring used in the Watts-Strogatz model, to explore various balances between these two competing rules (globalization and localization) that shape the self-organization of the network topology.
We can consider a modification of the Barab´asi-Albert model where each node has a capacity limit in terms of the number of connections it can hold. Assume that if a node’s degree exceeds its predefined capacity, the node splits into two, and each node inherits about half of the connections the original node had. This kind of node division can be considered a representation of a split-up of a company or an organization, or the evolution of different specialized genes from a single gene that had many functions. Implement this modified network growth model, conduct simulations, and see how the node division influences the resulting network topology.