
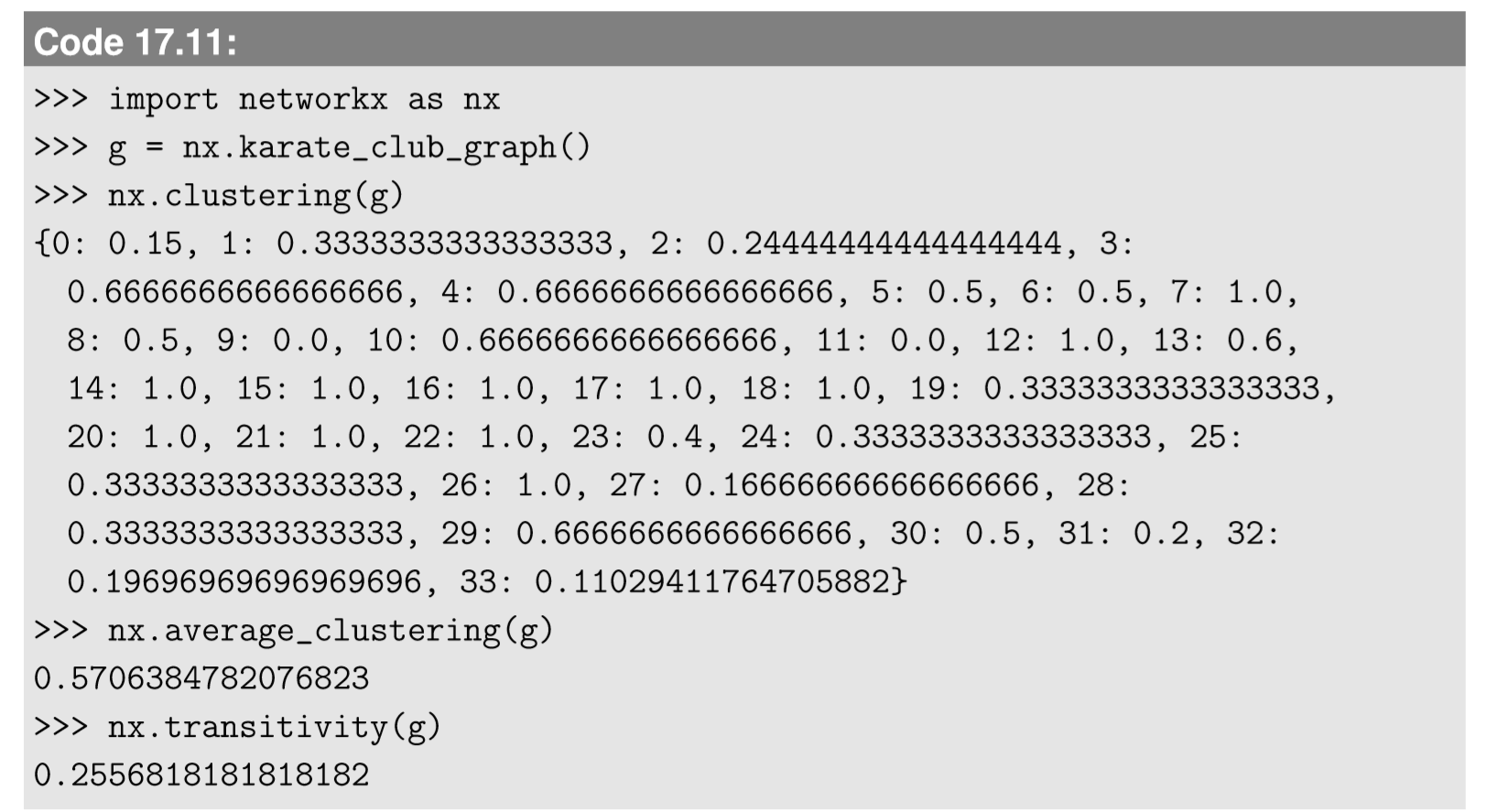
17.4: Clustering
- Page ID
- 7874

Eccentricity, centralities, and coreness introduced above all depend on the whole network topology (except for degree centrality). In this sense, they capture some macroscopic aspects of the network, even though we are calculating those metrics for each node. In contrast, there are other kinds of metrics that only capture local topological properties. This includes metrics of clustering, i.e., how densely connected the nodes are to each other in a localized area in a network. There are two widely used metrics for this:
Clustering coefficient
\[C(i) = \frac{| \begin{Bmatrix} \begin{Bmatrix} j,k \end{Bmatrix}| d(i,j) =d(i,k) = d(j,k) =1 \end{Bmatrix} |}{ deg(i) (deg(i)-1)/2 } \label{(17.25)} \]
The denominator is the total number of possible node pairs within node \(i\)’s neighborhood, while the numerator is the number of actually connected node pairs among them. Therefore, the clustering coefficient of node \(i\) calculates the probability for its neighbors to be each other’s neighbors as well. Note that this metric assumes that the network is undirected. The following average clustering coefficient is often used to measure the level of clustering in the entire network:
\[C =\frac{\sum_{i} {C(i)}}{n} \label{(17.26)} \]
Transitivity
\[C_{T} =\frac{| \begin{Bmatrix} (i,j,k)| d(i,j) =d(i,k) =d(j,k) =1 \end {Bmatrix}|}{ | \begin{Bmatrix} (i,j,k )| d(i,j) =d(i,k) =1| \end{Bmatrix} }\label{(17.27)} \]
This is very similar to clustering coefficients, but it is defined by counting connected node triplets over the entire network. The denominator is the number of connected node triplets (i.e., a node, \(i\), and two of its neighbors, \(j\) and \(k\)), while the numerator is the number of such triplets where \(j\) is also connected to \(k\). This essentially captures the same aspect of the network as the average clustering coefficient, i.e., how locally clustered the network is, but the transitivity can be calculated on directed networks too. It also treats each triangle more evenly, unlike the average clustering coefficient that tends to underestimate the contribution of triplets that involve highly connected nodes.
Again, calculating these clustering metrics is very easy in NetworkX:
Generate (1) an Erd˝os-R´enyi random network, (2) a WattsStrogatz small-world network, and(3) a Barab´asi-Albert scale-free network of comparable size and density, and compare them with regard to how locally clustered they are.
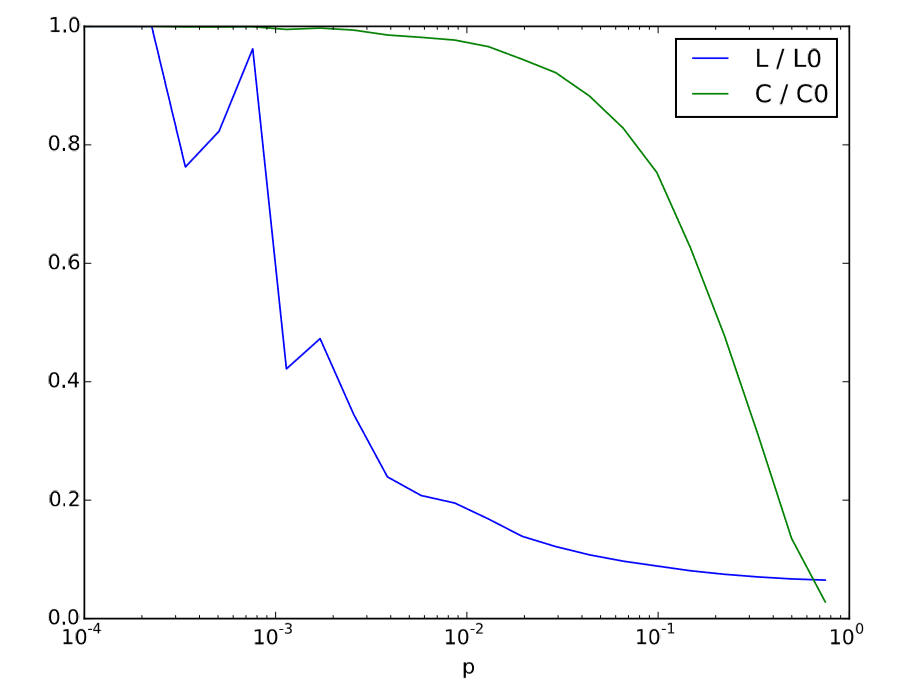
The clustering coefficient was first introduced by Watts and Strogatz [56], where they showed that their small-world networks tend to have very high clustering compared to their random counterparts. The following code replicates their computational experiment, varying the rewiring probability \(p\):



The result is shown in Fig. 17.4.1, where the characteristic path length (L) and the average clustering coefficient (C) are plotted as their fractions to the baseline values (L0, C0) obtained from a purely regular network g0. As you can see in the figure, the network becomes very small (low L) yet remains highly clustered (high C) at the intermediate value of p around \(10^{−2}\). This is the parameter regime where the Watts-Strogatz small-world networks arise
{kind=link}
Figure \(\PageIndex{1}\): Visual output of Code 17.12.