
A.1: Vectors, Mappings, and Matrices
- Page ID
- 73035
In real life, there is most often more than one variable. We wish to organize dealing with multiple variables in a consistent manner, and in particular organize dealing with linear equations and linear mappings, as those are both rather useful and rather easy to handle. Mathematicians joke that And well, they (the engineers) are not wrong. Quite often, solving an engineering problem is figuring out the right finite-dimensional linear problem to solve, which is then solved with some matrix manipulation. Most importantly, linear problems are the ones that we know how to solve, and we have many tools to solve them. For engineers, mathematicians, physicists, and anybody else in a technical field, it is absolutely vital to learn linear algebra.
As motivation, suppose we wish to solve \[\begin{align}\begin{aligned} & x-y = 2 , \\ & 2x+y = 4 , \end{aligned}\end{align} \nonumber \] for \(x\) and \(y\). That is, we desire numbers \(x\) and \(y\) such that the two equations are satisfied. Let us perhaps start by adding the equations together to find \[x+2x-y+y = 2+4, \qquad \text{or} \qquad 3x = 6 . \nonumber \]
In other words, \(x=2\). Once we have that, we plug \(x=2\) into the first equation to find \(2-y=2\), so \(y=0\). OK, that was easy. What is all this fuss about linear equations. Well, try doing this if you have \(5000\) unknowns\(^{1}\). Also, we may have such equations not just of numbers, but of functions and derivatives of functions in differential equations. Clearly we need a systematic way of doing things. A nice consequence of making things systematic and simpler to write down is that it becomes easier to have computers do the work for us. Computers are rather stupid, they do not think, but are very good at doing lots of repetitive tasks precisely, as long as we figure out a systematic way for them to perform the tasks.
Vectors and operations on Vectors
Consider \(n\) real numbers as an \(n\)-tuple: \[(x_1,x_2,\ldots,x_n). \nonumber \] The set of such \(n\)-tuples is the so-called \(n\)-dimensional space, often denoted by \({\mathbb R}^n\). Sometimes we call this the \(n\)-dimensional euclidean space\(^{2}\). In two dimensions, \({\mathbb R}^2\) is called the cartesian plane\(^{3}\). Each such \(n\)-tuple represents a point in the \(n\)-dimensional space. For example, the point \((1,2)\) in the plane \({\mathbb R}^2\) is one unit to the right and two units up from the origin.
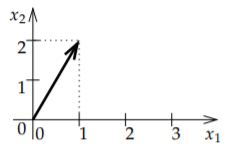
When we do algebra with these \(n\)-tuples of numbers we call them vectors\(^{4}\). Mathematicians are keen on separating what is a vector and what is a point of the space or in the plane, and it turns out to be an important distinction, however, for the purposes of linear algebra we can think of everything being represented by a vector. A way to think of a vector, which is especially useful in calculus and differential equations, is an arrow. It is an object that has a direction and a magnitude. For instance, the vector \((1,2)\) is the arrow from the origin to the point \((1,2)\) in the plane. The magnitude is the length of the arrow. See Figure \(\PageIndex{1}\). If we think of vectors as arrows, the arrow doesn’t always have to start at the origin. If we do move it around, however, it should always keep the same direction and the same magnitude.
As vectors are arrows, when we want to give a name to a vector, we draw a little arrow above it: \[\vec{x} \nonumber \]
Another popular notation is \(\mathbf{x}\), although we will use the little arrows. It may be easy to write a bold letter in a book, but it is not so easy to write it by hand on paper or on the board. Mathematicians often don’t even write the arrows. A mathematician would write \(x\) and just remember that \(x\) is a vector and not a number. Just like you remember that Jose is your uncle, and you don’t have to keep repeating and you can just say In this book, however, we will call Jose and write vectors with the little arrows.
The magnitude can be computed using the Pythagorean theorem. The vector \((1,2)\) drawn in the figure has magnitude \(\sqrt{1^2+2^2} = \sqrt{5}\). The magnitude is denoted by \(\lVert \vec{x} \rVert\), and, in any number of dimensions, it can be computed in the same way: \[\lVert \vec{x} \rVert = \lVert (x_1,x_2,\ldots,x_n) \rVert = \sqrt{x_1^2+x_2^2+\cdots+x_n^2} . \nonumber \]
For reasons that will become clear in the next section, we often write vectors as so-called column vectors: \[\vec{x} = \begin{bmatrix} x_{1} \\ x_2 \\ \vdots \\ x_n \end{bmatrix} . \nonumber \]
Don’t worry. It is just a different way of writing the same thing, and it will be useful later. For example, the vector \((1,2)\) can be written as \[\begin{bmatrix} 1 \\ 2 \end{bmatrix} . \nonumber \]
The fact that we write arrows above vectors allows us to write several vectors \(\vec{x}_1\), \(\vec{x}_2\), etc., without confusing these with the components of some other vector \(\vec{x}\).
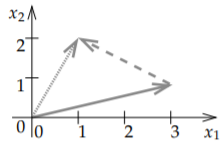
So where is the algebra from linear algebra? Well, arrows can be added, subtracted, and multiplied by numbers. First we consider addition. If we have two arrows, we simply move along one, and then along the other. See Figure \(\PageIndex{2}\).

It is rather easy to see what it does to the numbers that represent the vectors. Suppose we want to add \((1,2)\) to \((2,-3)\) as in the figure. We travel along \((1,2)\) and then we travel along \((2,-3)\). What we did was travel one unit right, two units up, and then we travelled two units right, and three units down (the negative three). That means that we ended up at \(\bigl(1+2,2+(-3)\bigr) = (3,-1)\). And that’s how addition always works: \[\begin{bmatrix} x_{1} \\ x_2 \\ \vdots \\ x_n \end{bmatrix} + \begin{bmatrix} y_{1} \\ y_2 \\ \vdots \\ y_n \end{bmatrix} = \begin{bmatrix} x_1 + y_{1} \\ x_2+ y_2 \\ \vdots \\ x_n + y_n \end{bmatrix} . \nonumber \]
Subtracting is similar. What \(\vec{x}- \vec{y}\) means visually is that we first travel along \(\vec{x}\), and then we travel backwards along \(\vec{y}\). See Figure \(\PageIndex{3}\). It is like adding \(\vec{x}+ (- \vec{y})\) where \(-\vec{y}\) is the arrow we obtain by erasing the arrow head from one side and drawing it on the other side, that is, we reverse the direction. In terms of the numbers, we simply go backwards both horizontally and vertically, so we negate both numbers. For instance, if \(\vec{y}\) is \((-2,1)\), then \(-\vec{y}\) is \((2,-1)\).
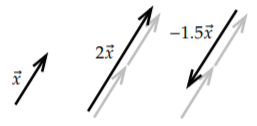
Another intuitive thing to do to a vector is to scale it. We represent this by multiplication of a number with a vector. Because of this, when we wish to distinguish between vectors and numbers, we call the numbers scalars. For example, suppose we want to travel three times further. If the vector is \((1,2)\), traveling 3 times further means going 3 units to the right and 6 units up, so we get the vector \((3,6)\). We just multiply each number in the vector by 3. If \(\alpha\) is a number, then \[\alpha \begin{bmatrix} x_{1} \\ x_2 \\ \vdots \\ x_n \end{bmatrix} = \begin{bmatrix} \alpha x_{1} \\ \alpha x_2 \\ \vdots \\ \alpha x_n \end{bmatrix} . \nonumber \] Scaling (by a positive number) multiplies the magnitude and leaves direction untouched. The magnitude of \((1,2)\) is \(\sqrt{5}\). The magnitude of 3 times \((1,2)\), that is, \((3,6)\), is \(3\sqrt{5}\).
When the scalar is negative, then when we multiply a vector by it, the vector is not only scaled, but it also switches direction. Multiplying \((1,2)\) by \(-3\) means we should go 3 times further but in the opposite direction, so 3 units to the left and 6 units down, or in other words, \((-3,-6)\). As we mentioned above, \(-\vec{y}\) is a reverse of \(\vec{y}\), and this is the same as \((-1)\vec{y}\).
In Figure \(\PageIndex{4}\), you can see a couple of examples of what scaling a vector means visually.
We put all of these operations together to work out more complicated expressions. Let us compute a small example: \[3 \begin{bmatrix} 1 \\ 2 \end{bmatrix} + 2 \begin{bmatrix} -4 \\ -1 \end{bmatrix} - 3 \begin{bmatrix} -2 \\ 2 \end{bmatrix} = \begin{bmatrix} 3(1)+2(-4)-3(-2) \\ 3(2)+2(-1)-3(2) \end{bmatrix} = \begin{bmatrix} 1 \\ -2 \end{bmatrix} . \nonumber \]
As we said a vector is a direction and a magnitude. Magnitude is easy to represent, it is just a number. The direction is usually given by a vector with magnitude one. We call such a vector a unit vector. That is, \(\vec{u}\) is a unit vector when \(\lVert \vec{u} \rVert = 1\). For instance, the vectors \((1,0)\), \((\frac{1}{\sqrt{2}},\frac{1}{\sqrt{2}})\), and \((0,-1)\) are all unit vectors.
To represent the direction of a vector \(\vec{x}\), we need to find the unit vector in the same direction. To do so, we simply rescale \(\vec{x}\) by the reciprocal of the magnitude, that is \(\frac{1}{\lVert \vec{x} \rVert} \vec{x}\), or more concisely \(\frac{\vec{x}}{\lVert \vec{x} \rVert}\).
As an example, the unit vector in the direction of \((1,2)\) is the vector \[\frac{1}{\sqrt{1^2+2^2}} (1,2) = \left( \frac{1}{\sqrt{5}}, \frac{2}{\sqrt{5}} \right) . \nonumber \]
Linear Mappings and Matrices
A vector-valued function \(F\) is a rule that takes a vector \(\vec{x}\) and returns another vector \(\vec{y}\). For example, \(F\) could be a scaling that doubles the size of vectors: \[F(\vec{x}) = 2 \vec{x} . \nonumber \] Applied to say \((1,3)\) we get \[F \left( \begin{bmatrix} 1 \\ 3 \end{bmatrix} \right) = 2 \begin{bmatrix} 1 \\ 3 \end{bmatrix} = \begin{bmatrix} 2 \\ 6 \end{bmatrix} . \nonumber \] If \(F\) is a mapping that takes vectors in \({\mathbb R}^2\) to \({\mathbb R}^2\) (such as the above), we write \[F \colon {\mathbb R}^2 \to {\mathbb R}^2 . \nonumber \]
The words function and mapping are used rather interchangeably, although more often than not, mapping is used when talking about a vector-valued function, and the word function is often used when the function is scalar-valued.
A beginning student of mathematics (and many a seasoned mathematician), that sees an expression such as \[f(3x+8y) \nonumber \] yearns to write \[3f(x)+8f(y) . \nonumber \]
After all, who hasn’t wanted to write \(\sqrt{x+y} = \sqrt{x} + \sqrt{y}\) or something like that at some point in their mathematical lives. Wouldn’t life be simple if we could do that? Of course we can’t always do that (for example, not with the square roots!) But there are many other functions where we can do exactly the above. Such functions are called linear.
A mapping \(F \colon {\mathbb R}^n \to {\mathbb R}^m\) is called linear if \[F(\vec{x}+\vec{y}) = F(\vec{x})+F(\vec{y}), \nonumber \] for any vectors \(\vec{x}\) and \(\vec{y}\), and also \[F(\alpha \vec{x}) = \alpha F(\vec{x}) , \nonumber \] for any scalar \(\alpha\). The \(F\) we defined above that doubles the size of all vectors is linear. Let us check: \[F(\vec{x}+\vec{y}) = 2(\vec{x}+\vec{y}) = 2\vec{x}+2\vec{y} = F(\vec{x})+F(\vec{y}) , \nonumber \] and also \[F(\alpha \vec{x}) = 2 \alpha \vec{x} = \alpha 2 \vec{x} = \alpha F(\vec{x}) . \nonumber \]
We also call a linear function a linear transformation. If you want to be really fancy and impress your friends, you can call it a linear operator. When a mapping is linear we often do not write the parentheses. We write simply \[F \vec{x} \nonumber \] instead of \(F(\vec{x})\). We do this because linearity means that the mapping \(F\) behaves like multiplying \(\vec{x}\) by That something is a matrix.
A matrix is an \(m \times n\) array of numbers (\(m\) rows and \(n\) columns). A \(3 \times 5\) matrix is \[A = \begin{bmatrix} a_{11} & a_{12} & a_{13} & a_{14} & a_{15} \\ a_{21} & a_{22} & a_{23} & a_{24} & a_{25} \\ a_{31} & a_{32} & a_{33} & a_{34} & a_{35} \end{bmatrix} . \nonumber \] The numbers \(a_{ij}\) are called elements or entries.
A column vector is simply an \(m \times 1\) matrix. Similarly to a column vector there is also a row vector, which is a \(1 \times n\) matrix. If we have an \(n \times n\) matrix, then we say that it is a square matrix.
Now how does a matrix \(A\) relate to a linear mapping? Well a matrix tells you where certain special vectors go. Let’s give a name to those certain vectors. The standard basis of vectors of \({\mathbb R}^n\) are \[\vec{e}_1 = \begin{bmatrix} 1 \\ 0 \\ 0 \\ \vdots \\ 0 \end{bmatrix} , \qquad \vec{e}_2 = \begin{bmatrix} 0 \\ 1 \\ 0 \\ \vdots \\ 0 \end{bmatrix} , \qquad \vec{e}_3 = \begin{bmatrix} 0 \\ 0 \\ 1 \\ \vdots \\ 0 \end{bmatrix} , \qquad \cdots , \qquad \vec{e}_n = \begin{bmatrix} 0 \\ 0 \\ 0 \\ \vdots \\ 1 \end{bmatrix} . \nonumber \] In \({\mathbb R}^3\) these vectors are \[\vec{e}_1 = \begin{bmatrix} 1 \\ 0 \\ 0 \end{bmatrix} , \qquad \vec{e}_2 = \begin{bmatrix} 0 \\ 1 \\ 0 \end{bmatrix} , \qquad \vec{e}_3 = \begin{bmatrix} 0 \\ 0 \\ 1 \end{bmatrix} . \nonumber \] You may recall from calculus of several variables that these are sometimes called \(\vec{\imath}\), \(\vec{\jmath}\), \(\vec{k}\).
The reason these are called a basis is that every other vector can be written as a linear combination of them. For example, in \({\mathbb R}^3\) the vector \((4,5,6)\) can be written as \[4 \vec{e}_1 + 5 \vec{e}_2 + 6 \vec{e}_3 = 4 \begin{bmatrix} 1 \\ 0 \\ 0 \end{bmatrix} + 5 \begin{bmatrix} 0 \\ 1 \\ 0 \end{bmatrix} + 6 \begin{bmatrix} 0 \\ 0 \\ 1 \end{bmatrix} = \begin{bmatrix} 4 \\ 5 \\ 6 \end{bmatrix} . \nonumber \]
So how does a matrix represent a linear mapping? Well, the columns of the matrix are the vectors where \(A\) as a linear mapping takes \(\vec{e}_1\), \(\vec{e}_2\), etc. For instance, consider \[M = \begin{bmatrix} 1 & 2 \\ 3 & 4 \end{bmatrix} . \nonumber \]
As a linear mapping \(M \colon {\mathbb R}^2 \to {\mathbb R}^2\) takes \(\vec{e}_1 = \left[ \begin{smallmatrix} 1 \\ 0 \end{smallmatrix} \right]\) to \(\left[ \begin{smallmatrix} 1 \\ 3 \end{smallmatrix} \right]\) and \(\vec{e}_2 = \left[ \begin{smallmatrix} 0 \\ 1 \end{smallmatrix} \right]\) to \(\left[ \begin{smallmatrix} 2 \\ 4 \end{smallmatrix} \right]\). In other words, \[M \vec{e}_1 = \begin{bmatrix} 1 & 2 \\ 3 & 4 \end{bmatrix} \begin{bmatrix} 1 \\ 0 \end{bmatrix} = \begin{bmatrix} 1 \\ 3 \end{bmatrix}, \qquad \text{and} \qquad M \vec{e}_2 = \begin{bmatrix} 1 & 2 \\ 3 & 4 \end{bmatrix} \begin{bmatrix} 0 \\ 1 \end{bmatrix} = \begin{bmatrix} 2 \\ 4 \end{bmatrix}. \nonumber \]
More generally, if we have an \(n \times m\) matrix \(A\), that is, we have \(n\) rows and \(m\) columns, then the mapping \(A \colon {\mathbb R}^m \to {\mathbb R}^n\) takes \(\vec{e}_j\) to the \(j^{\text{th}}\) column of \(A\). For example, \[A = \begin{bmatrix} a_{11} & a_{12} & a_{13} & a_{14} & a_{15} \\ a_{21} & a_{22} & a_{23} & a_{24} & a_{25} \\ a_{31} & a_{32} & a_{33} & a_{34} & a_{35} \end{bmatrix} \nonumber \] represents a mapping from \({\mathbb R}^5\) to \({\mathbb R}^3\) that does \[A \vec{e}_1 = \begin{bmatrix} a_{11} \\ a_{21} \\ a_{31} \end{bmatrix} , \qquad A \vec{e}_2 = \begin{bmatrix} a_{12} \\ a_{22} \\ a_{32} \end{bmatrix} , \qquad A \vec{e}_3 = \begin{bmatrix} a_{13} \\ a_{23} \\ a_{33} \end{bmatrix} , \qquad A \vec{e}_4 = \begin{bmatrix} a_{14} \\ a_{24} \\ a_{34} \end{bmatrix} , \qquad A \vec{e}_5 = \begin{bmatrix} a_{15} \\ a_{25} \\ a_{35} \end{bmatrix} . \nonumber \]
What about another vector \(\vec{x}\), which isn’t in the standard basis? Where does it go? We use linearity. First, we write the vector as a linear combination of the standard basis vectors: \[\vec{x} = \begin{bmatrix} x_1 \\ x_2 \\ x_3 \\ x_4 \\ x_5 \end{bmatrix} = x_1 \begin{bmatrix} 1 \\ 0 \\ 0 \\ 0 \\ 0 \end{bmatrix} + x_2 \begin{bmatrix} 0 \\ 1 \\ 0 \\ 0 \\ 0 \end{bmatrix} + x_3 \begin{bmatrix} 0 \\ 0 \\ 1 \\ 0 \\ 0 \end{bmatrix} + x_4 \begin{bmatrix} 0 \\ 0 \\ 0 \\ 1 \\ 0 \end{bmatrix} + x_5 \begin{bmatrix} 0 \\ 0 \\ 0 \\ 0 \\ 1 \end{bmatrix} = x_1 \vec{e}_1 + x_2 \vec{e}_2 + x_3 \vec{e}_3 + x_4 \vec{e}_4 + x_5 \vec{e}_5 . \nonumber \]
Then \[A \vec{x} = A ( x_1 \vec{e}_1 + x_2 \vec{e}_2 + x_3 \vec{e}_3 + x_4 \vec{e}_4 + x_5 \vec{e}_5 ) = x_1 A\vec{e}_1 + x_2 A\vec{e}_2 + x_3 A\vec{e}_3 + x_4 A\vec{e}_4 + x_5 A\vec{e}_5 . \nonumber \] If we know where \(A\) takes all the basis vectors, we know where it takes all vectors.
Suppose \(M\) is the \(2 \times 2\) matrix from above, then \[M \begin{bmatrix} -2 \\ 0.1 \end{bmatrix} = \begin{bmatrix} 1 & 2 \\ 3 & 4 \end{bmatrix} \begin{bmatrix} -2 \\ 0.1 \end{bmatrix} = -2 \begin{bmatrix} 1 \\ 3 \end{bmatrix} + 0.1 \begin{bmatrix} 2 \\ 4 \end{bmatrix} = \begin{bmatrix} -1.8 \\ -5.6 \end{bmatrix} . \nonumber \]
Every linear mapping from \({\mathbb R}^m\) to \({\mathbb R}^n\) can be represented by an \(n \times m\) matrix. You just figure out where it takes the standard basis vectors. Conversely, every \(n \times m\) matrix represents a linear mapping. Hence, we may think of matrices being linear mappings, and linear mappings being matrices.
Or can we? In this book we study mostly linear differential operators, and linear differential operators are linear mappings, although they are not acting on \({\mathbb R}^n\), but on an infinite-dimensional space of functions: \[L f = g . \nonumber \] For a function \(f\) we get a function \(g\), and \(L\) is linear in the sense that \[L ( f + h) = Lf + Lh, \qquad \text{and} \qquad L (\alpha f) = \alpha Lf . \nonumber \] for any number (scalar) \(\alpha\) and all functions \(f\) and \(h\).
So the answer is not really. But if we consider vectors in finite-dimensional spaces \({\mathbb R}^n\) then yes, every linear mapping is a matrix. We have mentioned at the beginning of this section, that we can That’s not strictly true, but it is true approximately. Those spaces of functions can be approximated by a finite-dimensional space, and then linear operators are just matrices. So approximately, this is true. And as far as actual computations that we can do on a computer, we can work only with finitely many dimensions anyway. If you ask a computer or your calculator to plot a function, it samples the function at finitely many points and then connects the dots\(^{5}\). It does not actually give you infinitely many values. The way that you have been using the computer or your calculator so far has already been a certain approximation of the space of functions by a finite-dimensional space.
To end the section, we notice how \(A \vec{x}\) can be written more succintly. Suppose \[A = \begin{bmatrix} a_{11} & a_{12} & a_{13} \\ a_{21} & a_{22} & a_{23} \end{bmatrix} \qquad \text{and} \qquad \vec{x} = \begin{bmatrix} x_1 \\ x_2 \\ x_3 \end{bmatrix} . \nonumber \]
Then \[A \vec{x} = \begin{bmatrix} a_{11} & a_{12} & a_{13} \\ a_{21} & a_{22} & a_{23} \end{bmatrix} \begin{bmatrix} x_1 \\ x_2 \\ x_3 \end{bmatrix} = \begin{bmatrix} a_{11} x_1 + a_{12} x_2 + a_{13} x_3 \\ a_{21} x_1 + a_{22} x_2 + a_{23} x_3 \end{bmatrix} . \nonumber \]
For example, \[\begin{bmatrix} 1 & 2 \\ 3 & 4 \end{bmatrix} \begin{bmatrix} 2 \\ -1 \end{bmatrix} = \begin{bmatrix} 1 \cdot 2 + 2 \cdot (-1) \\ 3 \cdot 2 + 4 \cdot (-1) \end{bmatrix} = \begin{bmatrix} 0 \\ 2 \end{bmatrix} . \nonumber \] That is, you take the entries in a row of the matrix, you multiply them by the entries in your vector, you add things up, and that’s the corresponding entry in the resulting vector.
Footnotes
[1] One of the downsides of making everything look like a linear problem is that the number of variables tends to become huge.
[2] Named after the ancient Greek mathematician Euclid of Alexandria (around 300 BC), possibly the most famous of mathematicians; even small towns often have Euclid Street or Euclid Avenue.
[3] Named after the French mathematician René Descartes (1596–1650). It is as his name in Latin is Renatus Cartesius.
[4] A common notation to distinguish vectors from points is to write \((1,2)\) for the point and \(\langle 1,2 \rangle\) for the vector. We write both as \((1,2)\).
[5] If you have ever used Matlab, you may have noticed that to plot a function, we take a vector of inputs, ask Matlab to compute the corresponding vector of values of the function, and then we ask it to plot the result.