
16.2: Multiplex Data Basics
- Page ID
- 7748

Multiplex data are data that describe multiple relations among the same set of actors. The measures of the relations can be directed or not; and the relations can be recorded as binary, multi-valued nominal, or valued (ordinal or interval).
The most common structure for multiplex data is a set of actor-by-actor matrices (or "slices"), one for each relation. Figure 16.1 shows the output of Data>Display for the Knoke social welfare organizations dataset, which contains information on two (binary, directed) relations: information exchange (KNOKI), and money exchange (KNOKM).

Figure 16.1: Data>Display of Knoke multi-relational data structure
The two relations are stored as separate matrices, but within the same file. Many of the analysis tools in UCINET will process each matrix or "slice" of a multiple-matrix data file like the Knoke example. Data>Unpack can be used to remove individual matrices from a multiple matrix file; Data>Join can be used to create a multiple-matrix dataset from separate single-matrix data files.
The multiple-matrix approach is most general, and allows us to record as many different relations as we wish by using separate matrices. Some matrices may be symmetric and others not; some may be binary, and others valued. A number of the tools that we will discuss shortly, however, will require that the data in the multiple matrices be of the same type (symmetric/asymmetric, binary/valued). So, often it will be necessary to do transformations on individual matrices before "reduction" and "combination" strategies can be applied.
A closely related multiplex data structure is the "Cognitive social structure" or CSS. A CSS records the perceptions of a number of actors of the relations among a set of nodes. For example, we might ask each of Bob, Carol, Ted, and Alice to tell us who among them was friends with whom. The result would be four matrices of the same form (4 actors by 4 actors), reporting the same relation (who's friends with whom), but differing according to who is doing the reporting and perceiving.
CSS data have exactly the same form as standard actor-by-actor slices. And some of the tools used for indexing CSS data are the same. Because of the unique nature of CSS data - which focuses on complex perception of a single structure, instead of a single perception of a complex structure - some additional tools may be applied (more, below).
A third, and rather different, data structure is the multi-valued matrix. Suppose that the relations among actors were nominal (that is, qualitative, or "present-absent") but there were multiple kinds of relations each pair of actors might have - forming a nominal polyotomy. That is, each pair of actors had one (and only one) of several kinds of relations. For one example, relations among a set of actors might (in some populations) be coded as either "nuclear family co-member" or "coworkers" or "extended family member" or "co-religionist" or "none". For another example, we could combine multiple relations to create qualitative types: 1 = kin only, 2 = coworker only, 3 = both kin and coworker, and 4 = neither kin nor coworker.
Nominal, but multi-valued, data combine information about multiplex relations into a single matrix. The values, however, don't represent strength, cost, or probability of a tie, but rather distinguish the qualitative type of tie that exists between each pair of actors. Recording data this way is efficient, and some algorithms in UCINET (e.g. Categorical REGE) can work directly with it. Often, though, data about multiplex relations that has been stored in a single multi-valued matrix will need to be transformed before we can perform many network operations on it.
Visualizing Multiplex Relations
For relatively small networks, drawing graphs is the best way of "seeing" structure. The only new problem is how to represent multiple relations among actors. One approach is to use multiple lines (with different colors or styles) and overlay one relation on another. Alternatively, one can "bundle" the relations into qualitative types and represent them with a single graph using lines of different colors or styles (e.g. kin tie = red; work tie = blue; kin and work tie = green).
Netdraw has some useful tools for visualizing multiple relations among the same set of actors. If the data have been stored as multiple matrices within the same file, when that file is opened (Netdraw>File>Open>UCINET dataset>Network) a Ties dialog box will allow you to select which matrix to view (as well as to set cut-off values for visualizing valued data). This is useful for flipping back and forth between relations, with the nodes remaining in the same locations. Suppose, for example, we had stored ten matrices in a file, reflecting snapshots of relations in a network as it evolved over some period of time. Using the Ties dialog, we can "flip the pages" to see the network evolve.
An even more useful tool is found in Netdraw>Properties>Lines>Multi-relation Selection. A drawing of the Knoke network with this dialog box visible is shown in Figure 16.2.
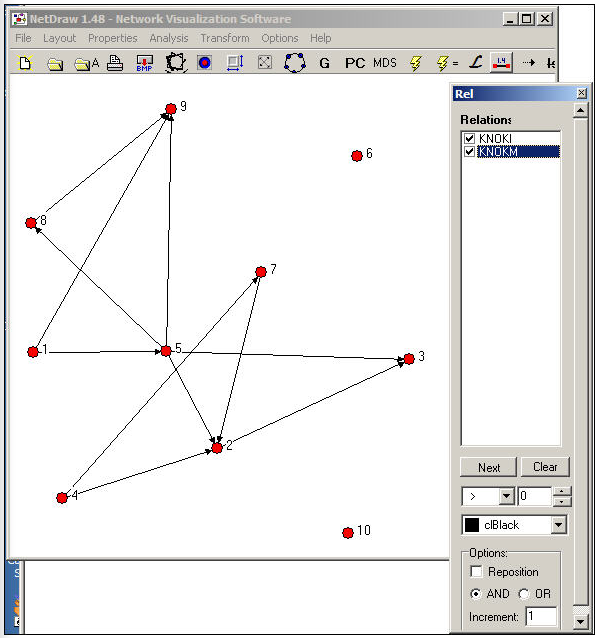
Figure 16.2: NetDraw graph of Knoke information and money exchange networks
The Relations dialog box allows you to select which relations you would like to view, and whether to view the union ("or") or intersection ("and") of the ties. In our example, we've asked to see the pattern of ties among organizations that send both information and money to others.
Combining Multiple Relations
For most analyses, the information about the multiple relations among actors will need to be combined into a single summary measure. One common approach is to combine the multiple relations into an index that reflects the quality (or type) of multiplex relation.
Transform>Multiplex can be used to summarize multiple relations among actors into a qualitative multi-valued index. Suppose that we had measured two relations among Bob, Carol, Ted, and Alice. The first is a directed friendship nomination, and the second is an undirected spousal relation. These two four-by-four binary matrices have been packed into a single data file called BCTAjoin. The dialog for Transform>Multiplex is shown as Figure 16.3.
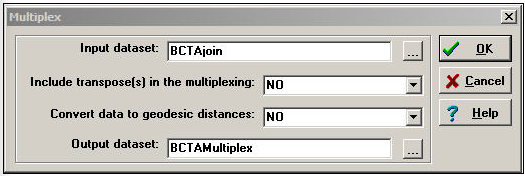
Figure 16.3: Transform>Multiplex dialog
There are two choices here. Convert data to geodesic distances allows us to first convert each relation into a valued metric from the binary. We've chosen not to do this. Another choice is whether or not to Include transpose(s) in the multiplexing. For asymmetric data, selecting yes will cause the rows and the columns of the input matrix to be treated as separate relations in forming the qualitative combinations. Again, we've chosen not to do this (though it is a reasonable idea in many real cases).
Figure 16.4 shows the input file, which is composed of two "stacked" or "sliced" matrices representing friendship and spousal ties.

Figure 16.4: Transform>Multiplex input
Figure 16.5 shows the resulting "typology" of kinds of relations among the actors, which has been generated as a multi-valued nominal index.
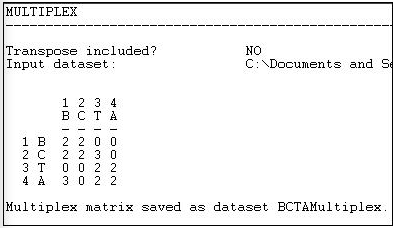
Figure 16.5: Transform>Multiplex output
Where there is no tie in either matrix, the type "0" has been assigned. Where there is both a friendship and a spousal tie, the number "2" has been assigned; where there is a friendship tie, but no spousal tie, the number "3" has been assigned. There could have been an additional type (spousal tie, but no friendship) which would have been assigned a different number.
Combining multiple relations in this way yields a qualitative typology of the kinds of relations that exist among actors. An index of this type might be of considerable interest in describing the prevalence of the types in a population, and in selecting sub-graphs for closer analysis.
The operation Transform>Multigraph does the reverse of what Transform>Multiplex does. That is, if we begin with a multi-valued single matrix (as in Figure 16.5), this operation will split the data and create a multiple matrix data file with one matrix for each "type" of relation. In the case of our example, Transform>Multigraph would generate two new matrices (one describing the "2" relation, and one describing the "3" relation).
In dealing with multiple relations among actors, we might also want to create a quantitative index that combines the relations. For example, we might suppose that if actors are tied by 4 different relations they share a "stronger" tie than if they share only 3 relations. But, there are many possible ways of creating indexes that capture different aspects or dimensions of the multiple relations among actors. Two tool-kits in UCINET support combining multiple matrices with a wide variety of built-in functions for capturing different aspect of the multi-relational data.
Transform>Matrix Operations>Matrix Operations>Between Datasets>Statistical Summaries provides some basic tools for creating a single valued matrix from multiple matrices. Figure 16.6 shows the dialog for this tool.

Figure 16.6: Dialog for between dataset matrix operations - statistical summaries
In the example, we've selected the two separate single-relation matrices for Bob, Carol, Ted, and Alice, and asked to create a new (single matrix) dataset called bda-Minimum. By selecting the Minimum function, we've chosen a rule that says: look at relations across the matrices, and summarize each pair-wise relation as the weakest one. For binary data, this is the same as the logical operation "and".
Also available in this dialog are Sum (which adds the values, element-wise, across matrices); Average (which computes the mean, element-wise across matrices); Maximum (which selects the largest value, element-wise); and Element-wise Multiplication (which multiplies the elements across matrices). This is a pretty useful tool kit, and captures most of the ways in which quantitative indexes might be created (weakest tie, strongest tie, average tie, interaction of ties).
We might want to combine the information on multiple relations into a quantitative index by using logical operations instead of numeric. Figure 16.7 shows the dialog for Transform>Matrix Operations>Matrix Operations>Between Datasets>Boolean Combinations.
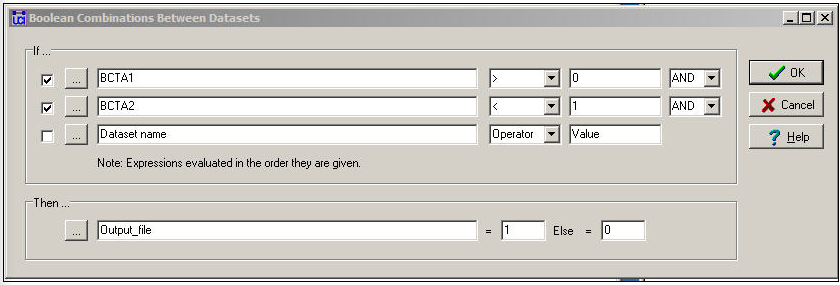
Figure 16.7: Dialog for between dataset matrix operations - Boolean combinations
In this dialog, we've said: if there is a friendship tie and there is no spousal tie, then code the output relation as "1". Otherwise, code the output relation as "0". This is not a very sensible thing to do, but it illustrates the point that this tool can be used to perform basic logical operations to create valued (or binary) indexes that combine the information on multiple relations.
Combining Multiple Views
Suppose that I asked every member of the faculty of my department to fill out a questionnaire reporting on their perceptions of who likes whom among the faculty. We would be collecting "cognitive social structure" data; that is, reports from actors embedded in a network about the whole network. There is a very interesting research literature that explores the relationship between actor's positions in networks, and their perceptions of the network. For example, do actors have a bias toward perceiving their own positions as more "central" than other actors' perceptions of their centrality?
A cognitive social structure (CSS) dataset contains multiple actor-by-actor matrices. Each matrix reports on the full set of a single relation among all the actors, as perceived by a particular respondent. While we could use many of the tools discussed in the previous section to combine or reduce data like these into indexes, there are some special tools that apply to cognitive data. Figure 16.8 shows the dialog of Data>CSS, which provides access to some specialized tools for cognitive network research.
Figure 16.8: Dialog for Data>CSS
The key element here is the choice of Method for pooling graphs. In creating a single summary of the relations, we could select the perceptions of a single actor; or, we might want to focus on the perceptions of the pair of actors involved in each particular relationship; or we might want to combine the information of all of the actors in the network.
Slice selects the perception of one particular actor to represent the network (the dialog then asks, "which informant?"). If we had a particular expert informant we might choose his/her view of the network as a summary. Or, we could extract multiple different actors into different files. We might also extract actors based on some attribute (e.g. gender) and extract their graphs, then pool them by some other method.
Row LAS uses the data from each actor's row to be the row entry in the output matrix. That is, actor A's perceptions of his/her row values are used for row A in the output matrix; actor B's perceptions of his/her row values are used for row B in the output matrix. This uses each actor as the "informant" about their own out-ties.
Column LAS uses each actor's column to be the column entry in the output matrix. That is, each actor is being used as the "informant" regarding their own in-ties.
Intersection LAS constructs the output matrix by examining the entries of the particular pair of actors involved. For example, in the output matrix we would have an element that described the relation between Bob and Ted. We have data on how Bob, Ted, Carol, and Alice each perceive the relation of Bob and Ted. The LAS method focuses on only the two involved nodes (Bob and Ted) and ignores the others. The intersection method gives a "1" to the tie if both Bob and Ted say there is a tie, and a "0" otherwise.
Union LAS assigns a "1" to the pair-wise relation if either actor (i.e. either Bob or Ted) says there is a tie.
Median LAS selects the median of the two values for the B,T relation that are reported by B and by T. This is useful if the relation being examined is valued, rather than binary.
Consensus uses the perceptions of all actors to create the summary index. The perceptions of Bob, Carol, Ted, and Alice are summed, and if the sum is greater than a user-specified cut-off value, "1" is assigned, else "0".
Average calculates the numerical average of all actors' perceptions of each pair-wise tie.
Sum calculates the sum of all actors' perceptions for each pair-wise tie.
The range of choices here suggests a fertile research area in how actors embedded in relations perceive those relations. The variety of indexing methods also suggests a number of interesting questions about, and methods for dealing with, the reliability of network data when it is collected from embedded respondents.