
11.1: Introduction to Cliques and Sub-groups

( \newcommand{\kernel}{\mathrm{null}\,}\)
One of the most common interests of structural analysts is in the "sub-structures" that may be present in a network. The dyads, triads, and ego-centered neighborhoods that we examined earlier can all be though of as sub-structures. In this chapter, we'll consider some approaches to identifying larger groupings.
Many of the approaches to understanding the structure of a network emphasize how dense connections are built-up from simpler dyads and triads to more extended dense clusters such as "cliques". This view of social structure focuses attention on how solidarity and connection of large social structures can be built up out of small and tight components: a sort of "bottom up" approach. Network analysts have developed a number of useful definitions and algorithms that identify how larger structures are compounded from smaller ones: cliques, n-cliques, n-clans, and k-plexes all look at networks in this way.
Divisions of actors into groups and sub-structures can be a very important aspect of social structure. It can be important in understanding how the network as a whole is likely to behave. Suppose the actors in one network form two non-overlapping groups; and, suppose that the actors in another network also form two groups, but that the memberships overlap (some people are members of both groups). Where the groups overlap, we might expect that conflict between them is less likely that when the groups don't overlap. Where the groups overlap, mobilization and diffusion may spread rapidly across the entire network; where the groups don't overlap, traits may occur in one group and not diffuse to the other.
Knowing how an individual is embedded in the structure of groups within a net may also be critical to understanding his/her behavior. For example, some people may act as "bridges" between groups (cosmopolitans, boundary spanners, or "brokers" that we examined earlier). Others may have all of their relationships within a single group (locals or insiders). Some actors may be part of a tightly connected and closed elite, while others are completely isolated from this group. Such differences in the ways that individuals are embedded in the structure of groups within a network can have profound consequences for the ways that these actors see their "society", and the behaviors that they are likely to practice.
We can also look for sub-structure from the "top-down". Looking at the whole network, we can think of sub-structures as areas of the graph that seem to be locally dense, but separated to some degree, from the rest of the graph. This idea has been applied in a number of ways: components, blocks/cutpoints, K-cores, Lambda sets and bridges, factions, and f-groups will be discussed here.
The idea that some regions of a graph may be less connected to the whole than others may lead to insights into lines of cleavage and division. Weaker parts in the "social fabric" also create opportunities for brokerage and less constrained action. So, the numbers and sizes of regions, and their "connection topology" may be consequential for predicting both the opportunities and constraints facing groups and actors, as well as predicting the evolution of the graph itself.
Most computer algorithms for locating sub-structures operate on binary symmetric data. We will use the Knoke information exchange data for most of the illustrations again in this chapter. Where algorithms allow it, the directed form of the data will be used. Where symmetric data are called for, we will analyze "strong ties". That is, we will symmetrize the data by insisting that ties must be reciprocated in order to count; that is, a tie only exists if xy and yx are both present.
The resulting reciprocity-symmetric data matrix is shown in Figure 11.1.
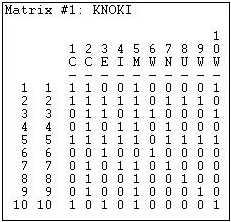
Figure 11.1: Knoke information network symmetrized with reciprocated ties
Insisting that information move in both directions between the parties in order for the two parties to be regarded as "close" makes theoretical sense, and substantially lessens the density of the matrix. Matrices that have very high density, almost by definition, are likely to have few distinctive sub-groups or cliques. It might help to graph these data as in Figure 11.2.

Figure 11.2: Graph of Knoke information strong symmetric ties
The diagram suggests a number of things. Actors #5 and #2 appear to be in the middle of the action - in the sense that they are members of many of the groupings, and serve to connect them, by co-membership. The connection of sub-graphs by actors can be an important feature. We can also see that there is one case (#6) that is not a member of any sub-group (other than a dyad). If you look closely, you will see that dyads and triads are the most common sub-graphs here - and despite the substantial connectivity of the graph, tight groupings larger than this seem to be few. It is also apparent from visual inspection that most of the sub-groupings are connected - that groups overlap.
Answers to the main questions about a graph, in terms of its sub-structures, may be apparent from inspection:
- How separate are the sub-graphs? Do they overlap and share members, or do they divide or factionalize the network?
- How large are the connected sub-graphs? Are there a few big groups, or a larger number of small groups?
- Are there particular actors that appear to play network roles? For example, act as nodes that connect the graph, or who are isolated from groups?
The formal tools and concepts of sub-graph structure help to more rigorously define ideas like this. Various algorithms can then be applied to locate, list, and study sub-graph features. Obviously, there are a number of possible groupings and positions in sub-structures, depending on our definitions. In this chapter, we will look at the most common of these ideas.