
17.3: Centralities and Coreness
- Page ID
- 7873

\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\dsum}{\displaystyle\sum\limits} \)
\( \newcommand{\dint}{\displaystyle\int\limits} \)
\( \newcommand{\dlim}{\displaystyle\lim\limits} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\(\newcommand{\longvect}{\overrightarrow}\)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)The eccentricity of nodes discussed above can be used to detect which nodes are most central in a network. This can be useful because, for example, if you send out a message from one of the center nodes with minimal eccentricity, the message will reach every single node in the network in the shortest period of time.
In the meantime, there are several other more statistically based measurements of node centralities, each of which has some benefits, depending on the question you want to study. Here is a summary of some of those centrality measures:
Degree centrality
\[c_{D}(i) = \frac{deg(i)}{n-1} \label{(17.19)} \]
Degree centrality is simply a normalized node degree, i.e., the actual degree divided by the maximal degree possible \((n−1)\). For directed networks, you can define in-degree centrality and out-degree centrality separately.
Betweenness centrality
\[c_{B}(i) =\frac{1}{(n-1)(n-2)} \sum_{j\neq{i}, k \neq{i}, j \neq{k}}{\frac{N_{sp}(j \rightarrow^{i}{k})}{N_{sp}(j \rightarrow {k})}} \label{(17.20)} \]
where \(N_{sp}(j → k)\) is the number of shortest paths from node \(j\) to node \(k\), and \(N_{sp}(j →^{i}− k)\) is the number of the shortest paths from node \(j\) to node \(k\) that go through node \(i\). Betweenness centrality of a node is the probability for the shortest path between two randomly chosen nodes to go through that node. This metric can also be defined for edges in a similar way, which is called edge betweenness.
Closeness centrality
\[C_{c}(i) =( \frac{\sum_{j}{d(i \rightarrow{j})}}{n-1})^{-1} \label{(17.21)} \]
This is an inverse of the average distance from node \(i\) to all other nodes. If \(c_{C}(i) = 1\), that means you can reach any other node from node \(i\) in just one step. For directed networks, you can also define another closeness centrality by swapping \(i\) and \(j\) in the formula above to measure how accessible node \(i\) is from other nodes.
Eigenvector centrality
\[c_{E}(i) =v_{i} \qquad{(i-th \ element \ of \ the \ dominant \ eigenvector \ v \ of \ the \ network’s \ adjacency \ matrix)} \label{(17.22)} \]
Eigenvector centrality measures the “importance” of each node by considering each incoming edge to the node an “endorsement” from its neighbor. This differs from degree centrality because, in the calculation of eigenvector centrality, endorsements coming from more important nodes count as more. Another completely different, but mathematically equivalent, interpretation of eigenvector centrality is that it counts the number of walks from any node in the network that reach node \(i\) in \(t\) steps, with \(t\) taken to infinity. Eigenvector \(v\) is usually chosen to be a non-negative unit vector \((v_{i} ≥ 0,|v| = 1)\).
PageRank
\[c_{P}(i) =v_{i} \qquad{(i-th \ element \ of \ the \ dominant \ eigenvector \ v \ of \ the \ following \ transition \ probability \ matrix)} \label{(17.23)} \]
\[T =\alpha{AD}^{-1} + (1 -\alpha) \frac{J}{n} \label{(17.24)} \]
where \(A\) is the adjacency matrix of the network, \(D^{−1}\) is a diagonal matrix whose \(i\)-th diagonal component is \(1/deg(i)\), \(J\) is an \(n×n\) all-one matrix, and \(α\) is the damping parameter (\(α = 0.85\) is commonly used by default).
PageRank is a variation of eigenvector centrality that was originally developed by Larry Page and Sergey Brin, the founders of Google, in the late 1990s [74, 75] to rank web pages. PageRank measures the asymptotic probability for a random walker on the network to be standing on node \(i\), assuming that the walker moves to a randomly chosen neighbor with probability \(α\), or jumps to any node in the network with probability \(1−α\), in each time step. Eigenvector v is usually chosen to be a probability distribution, i.e., \( \sum_{i} {v_{i}} = 1\).
Note that all of these centrality measures give a normalized value between 0 and 1, where 1 means perfectly central while 0 means completely peripheral. In most cases, the values are somewhere in between. Functions to calculate these centrality measures are also available in NetworkX (outputs are omitted in the code below to save space):

While those centrality measures are often correlated, they capture different properties of each node. Which centrality should be used depends on the problem you are addressing. For example, if you just want to find the most popular person in a social network, you can just use degree centrality. But if you want to find the most efficient person to disseminate a rumor to the entire network, closeness centrality would probably be a more appropriate metric to use. Or, if you want to find the most effective person to monitor and manipulate information flowing within the network, betweenness centrality would be more appropriate, assuming that information travels through the shortest paths between people. Eigenvector centrality and PageRank are useful for generating a reasonable ranking of nodes in a complex network made of directed edges.
Visualize the Karate Club graph using each of the above centrality measures to color the nodes, and then compare the visualizations to see how those centralities are correlated.
Generate (1) an Erd˝os-R´enyi random network, (2) a Watts-Strogat zmall-world network, and (3) a Barab´asi-Albert scale-free network of comparable size and density, and obtain the distribution of node centralities of your choice for each network. Then compare those centrality distributions to find which one is most/least heterogeneous.
Prove that PageRank with \(α = 1\) is essentially the same as the degree centrality for undirected networks.
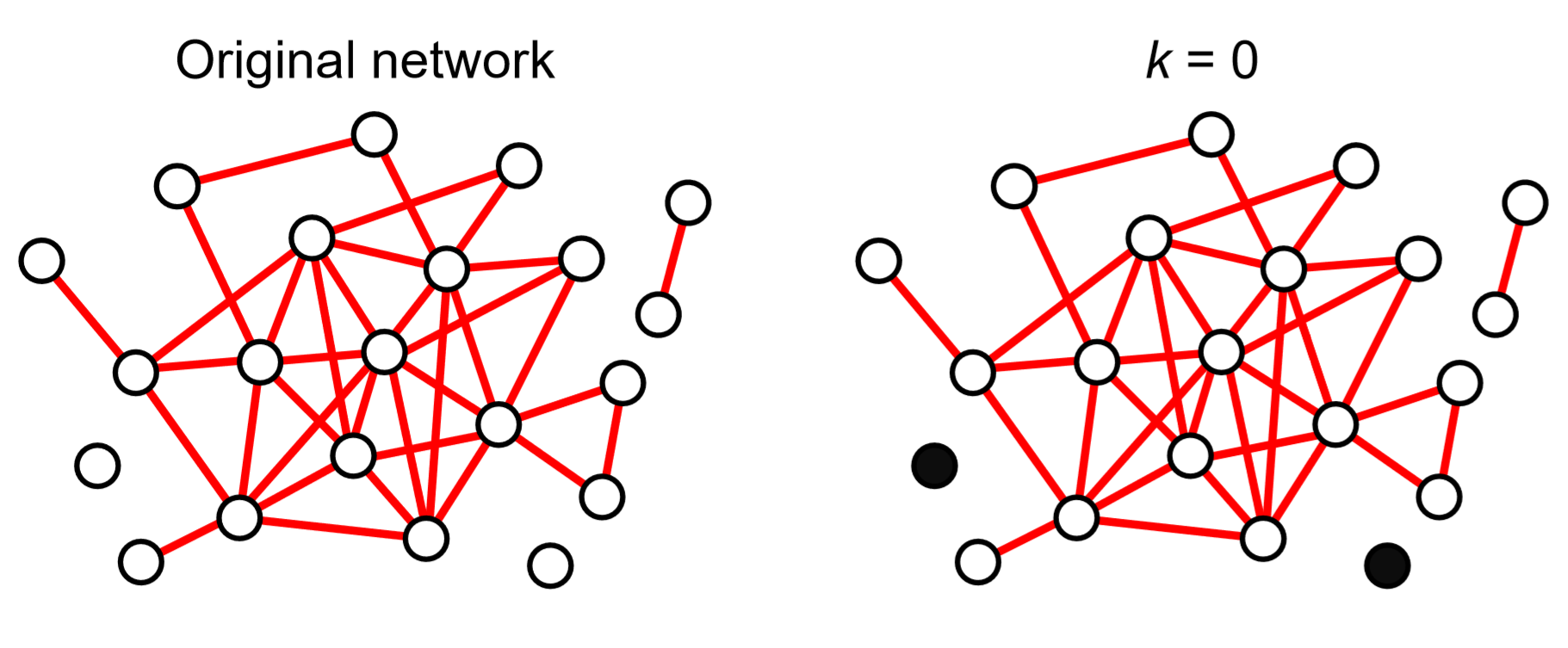
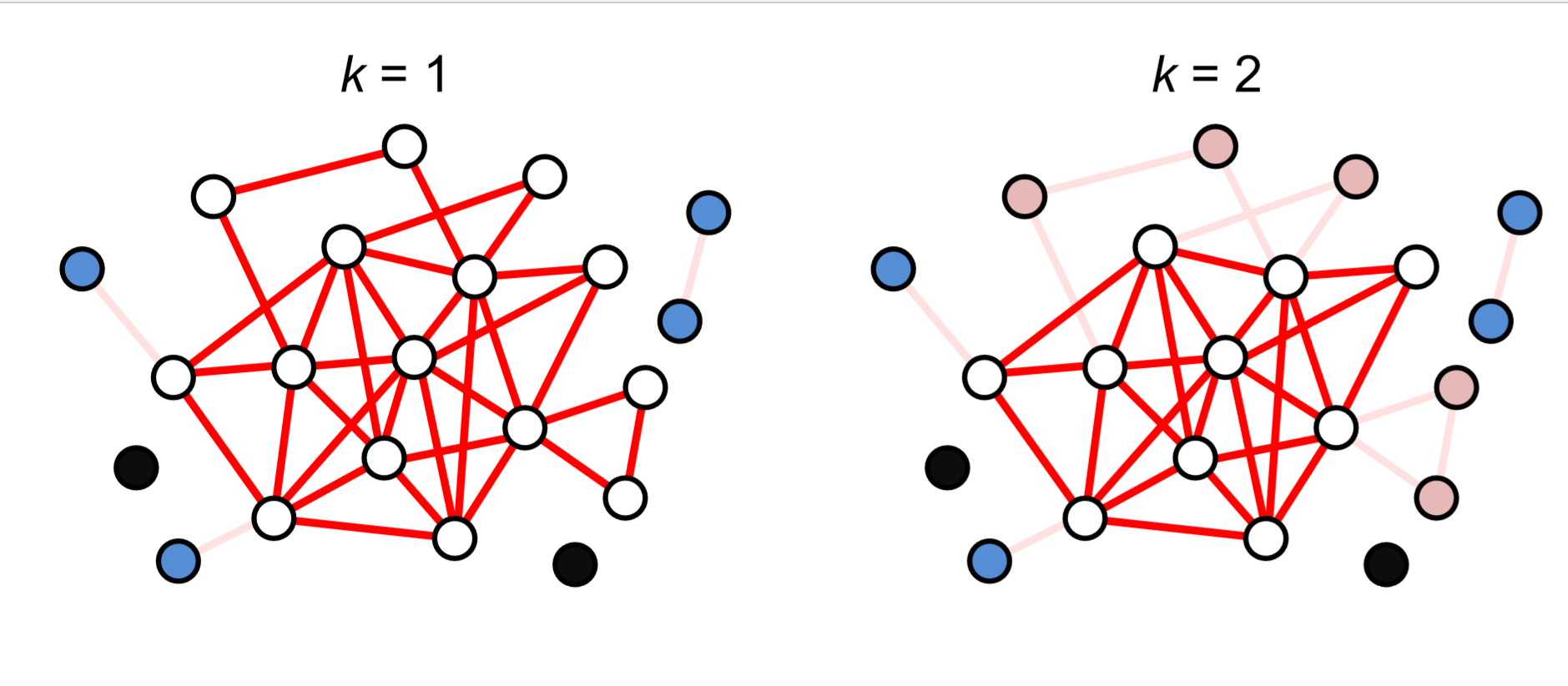
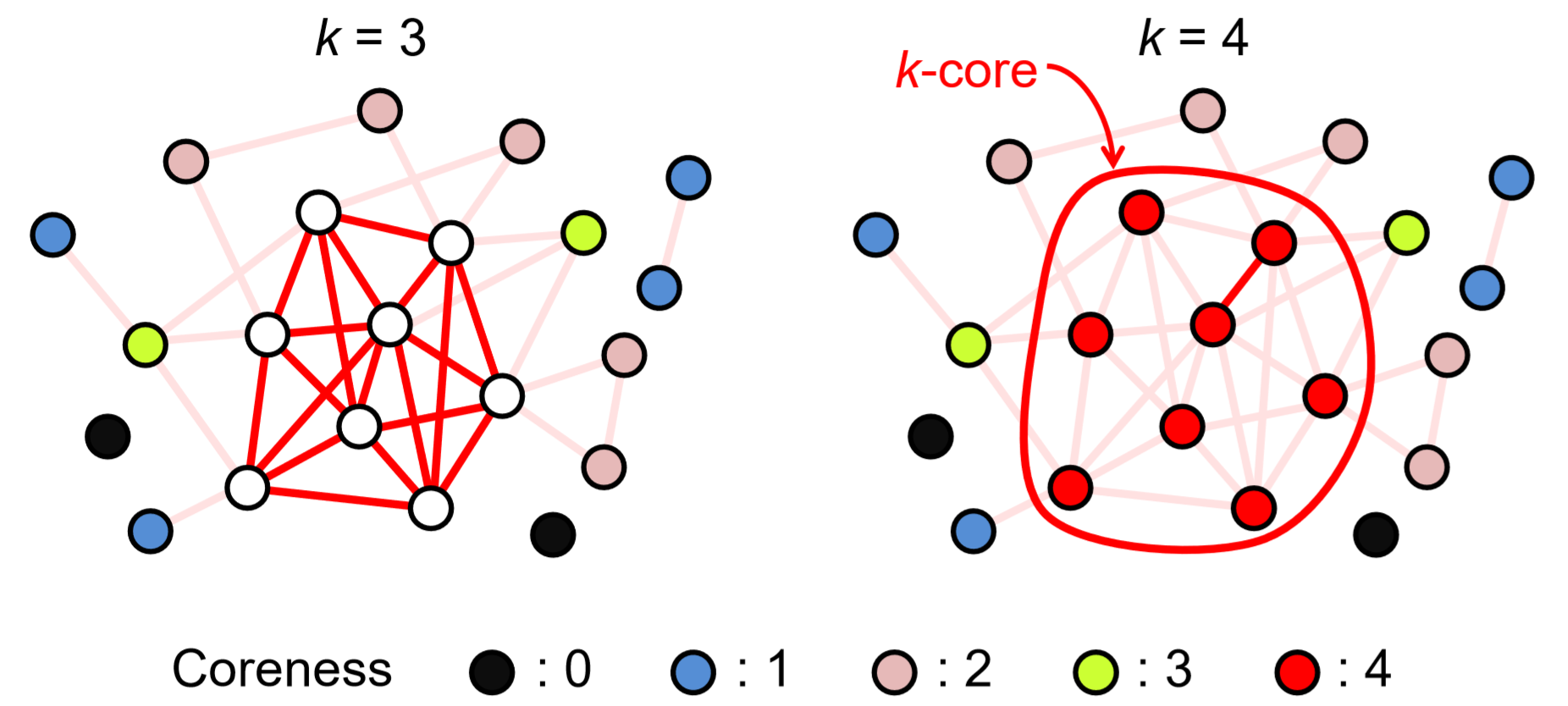
A little different approach to characterize the centrality of nodes is to calculate their coreness. This can be achieved by the following simple algorithm:
1. Let \(k = 0\).
2. Repeatedly delete all nodes whose degree is \(k\) or less, until no such nodes exist. Those removed nodes are given a coreness \(k\).
3. If there are still nodes remaining in the network, increase \(k\) by 1, and then go back to the previous step.
Figure 17.3.1 shows an example of this calculation. At the very end of the process, we see a cluster of nodes whose degrees are at least the final value of \(k\). This cluster is called a \(k\)-core, which can be considered the central part of the network.
In NetworkX, you can calculate the corenesses of nodes using the core_number function. Also, the \(k\)-core of the network can be obtained by using the k_core function. Here is an example:

The resulting \(k\)-core of the Karate Club graph is shown in Fig. 17.3.2.
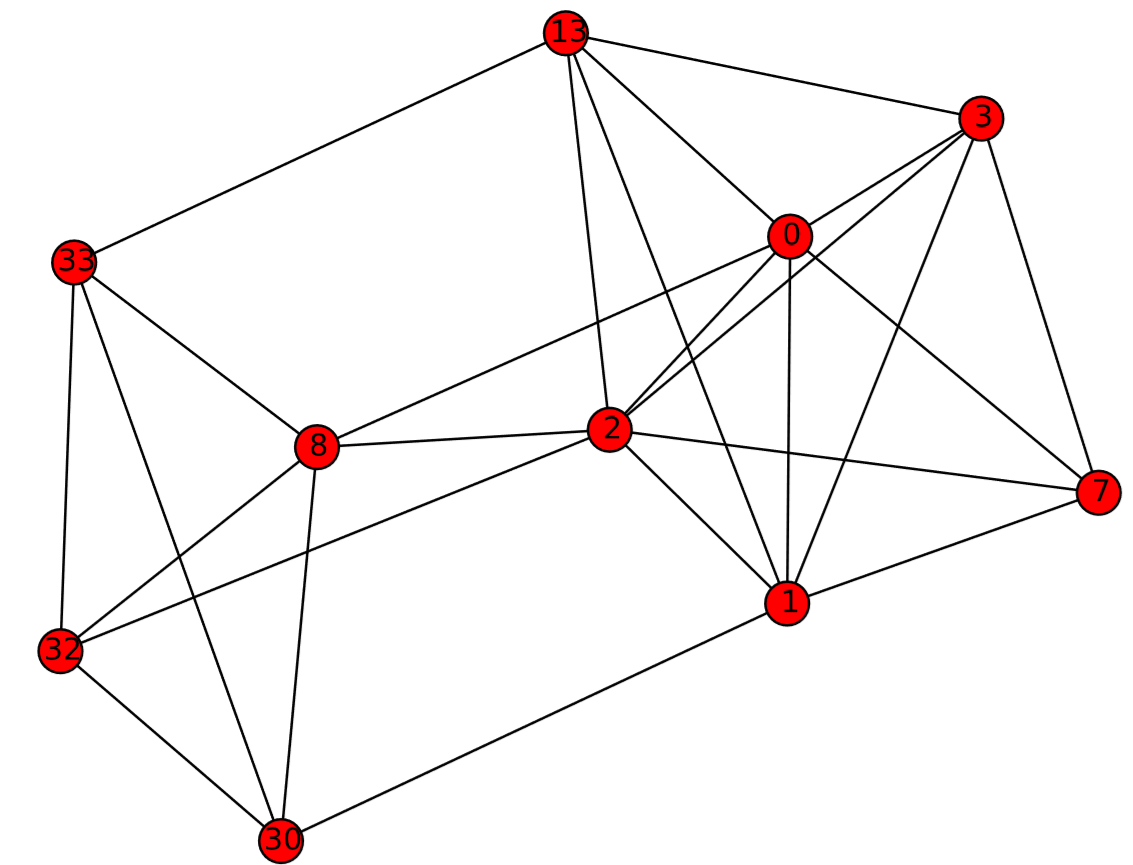
One advantage of using coreness over other centrality measures is its scalability. Because the algorithm to compute it is so simple, the calculation of coreness of nodes in a very large network is much faster than other centrality measures (except for degree centrality, which is obviously very fast too).
Import a large network data set of your choice from Mark Newman’s Network Data website: http://www-personal.umich.edu/~mejn/netdata/
Calculate the coreness of all of its nodes and draw their histogram. Compare the speed of calculation with, say, the calculation of betweenness centrality. Also visualize the \(k\)-core of the network.