
3.8: Inverses and Radical Functions
- Page ID
- 31091

\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)Skills to Develop
In this section, you will:
- Find the inverse of an invertible polynomial function.
- Restrict the domain to find the inverse of a polynomial function.
A mound of gravel is in the shape of a cone with the height equal to twice the radius.

Figure \(\PageIndex{1}\)
The volume is found using a formula from elementary geometry.
\[ \begin{align*} V&=\dfrac{1}{3}\pi r^2h \\[5pt] &=\dfrac{1}{3}\pi r^2(2r)\\[5pt] &=\dfrac{2}{3}\pi r^3 \end{align*}\]
We have written the volume \(V\) in terms of the radius \(r\). However, in some cases, we may start out with the volume and want to find the radius. For example: A customer purchases 100 cubic feet of gravel to construct a cone shape mound with a height twice the radius. What are the radius and height of the new cone? To answer this question, we use the formula
\[r=\sqrt[3]{\dfrac{3V}{2\pi}} \nonumber\]
This function is the inverse of the formula for \(V\) in terms of \(r\).
In this section, we will explore the inverses of polynomial and rational functions, and the radical functions we encounter in the process.
Finding the Inverse of a Polynomial Function
Two functions \(f\) and \(g\) are inverse functions if for every coordinate pair \((a,b)\) in \(f\), there exists a corresponding coordinate pair \((b, a)\) in the inverse function, \(g\). In other words, the coordinate pairs of the inverse functions have the input and output interchanged. Only one-to-one functions have inverses. Recall that a one-to-one function has a unique output value for each input value and passes the horizontal line test.
For example, suppose a water runoff collector is built in the shape of a parabolic trough as shown in Figure \(\PageIndex{2}\). We can use the information in the figure to find the surface area of the water in the trough as a function of the depth of the water.

Figure \(\PageIndex{2}\)
Because it will be helpful to have an equation for the parabolic cross-sectional shape, we will impose a coordinate system at the cross section, with \(x\) measured horizontally and \(y\) measured vertically, with the origin at the vertex of the parabola (Figure \(\PageIndex{3}\)).

Figure \(\PageIndex{3}\)
From this we find an equation for the parabolic shape. We placed the origin at the vertex of the parabola, so we know the equation will have form \(y(x)=ax^2\). Our equation will need to pass through the point \((6, 18)\), from which we can solve for the stretch factor \(a\).
\[ \begin{align*} 18&=a6^2 \\[5pt] a &=\dfrac{18}{36} \\[5pt] &=\dfrac{1}{2} \end{align*}\]
Our parabolic cross section has the equation
\(y(x)=\dfrac{1}{2}x^2\)
We are interested in the surface area of the water, so we must determine the width at the top of the water as a function of the water depth. For any depth \(y\), the width will be given by \(2x\), so we need to solve the equation above for \(x\) and find the inverse function. However, notice that the original function is not one-to-one, and indeed, given any output there are two inputs that produce the same output, one positive and one negative.
To find an inverse, we can restrict our original function to a limited domain on which it is one-to-one. In this case, it makes sense to restrict ourselves to positive \(x\) values. On this domain, we can find an inverse by solving for the input variable:
\(y=\dfrac{1}{2}x^2\)
\(2y=x^2\)
\(x=\pm \sqrt{2y}\)
This is not a function as written. We are limiting ourselves to positive \(x\) values, so we eliminate the negative solution, giving us the inverse function we’re looking for.
\(y=\dfrac{x^2}{2}\), \(x>0\)
Because \(x\) is the distance from the center of the parabola to either side, the entire width of the water at the top will be \(2x\). The trough is 3 feet (36 inches) long, so the surface area will then be:
\({Area}=l⋅w\)
\(=36⋅2x\)
\(=72x\)
\(=72\sqrt{2y}\)
This example illustrates two important points:
- When finding the inverse of a quadratic, we have to limit ourselves to a domain on which the function is one-to-one.
- The inverse of a quadratic function is a square root function. Both are toolkit functions and different types of power functions.
Functions involving roots are often called radical functions. While it is not possible to find an inverse of most polynomial functions, some basic polynomials do have inverses. Such functions are called invertible functions, and we use the notation \(f^{−1}(x)\).
Warning: \(f^{−1}(x)\) is not the same as the reciprocal of the function \(f(x)\). This use of “–1” is reserved to denote inverse functions. To denote the reciprocal of a function \(f(x)\), we would need to write \({(f(x))}^{−1}=\frac{1}{f(x)}\).
An important relationship between a function and its inverse is that they “undo” each other. If \(f^{−1}\) is the inverse of a function \(f\), then \(f\) is the inverse of the function \(f^{−1}\). In other words, whatever the function \(f\) does to \(x\), \(f^{−1}\) undoes it—and vice-versa.
\(f^{−1}(f(x))=x\), for all \(x\) in the domain of \(f\)
and
\(f(f^{−1}(x))=x\), for all \(x\) in the domain of \(f^{−1}\)
Note that the inverse switches the domain and range of the original function.
VERIFYING TWO FUNCTIONS ARE INVERSES OF ONE ANOTHER
Two functions, \(f\) and \(g\), are inverses of one another if for all \(x\) in the domain of \(f\) and \(g\),
\(g(f(x))=f(g(x))=x\)
![]() Given a polynomial function, find the inverse of the function by restricting the domain in such a way that the new function is one-to-one
Given a polynomial function, find the inverse of the function by restricting the domain in such a way that the new function is one-to-one
- Replace \(f(x)\) with \(y\).
- Interchange \(x\) and \(y\).
- Solve for \(y\), and rename the function \(f^{−1}(x)\).
Example \(\PageIndex{1}\): Verifying Inverse Functions
Show that \(f(x)=\frac{1}{x+1}\) and \(f^{−1}(x)=\frac{1}{x}−1\) are inverses, for \(x≠0,−1\).
Solution
We must show that \(f^{−1}(f(x))=x\) and \(f(f^{−1}(x))=x\).
\(f^{−1}(f(x))=f^{−1}(\dfrac{1}{x+1})\)
\(=\dfrac{1}{\dfrac{1}{x+1}}−1\)
\(=(x+1)−1\)
\(=x\)
\(f(f^{−1}(x))=f(\dfrac{1}{x−1})\)
\(=\dfrac{1}{(\dfrac{1}{x−1})+1}\)
\(=\dfrac{1}{\dfrac{1}{x}}\)
\(=x\)
Therefore, \(f(x)=\dfrac{1}{x+1}\) and \(f^{−1}(x)=\dfrac{1}{x}−1\) are inverses.
![]() \(\PageIndex{1}\): Show that \(f(x)=\frac{x+5}{3}\) and \(f^{−1}(x)=3x−5\) are inverses.
\(\PageIndex{1}\): Show that \(f(x)=\frac{x+5}{3}\) and \(f^{−1}(x)=3x−5\) are inverses.
- Answer
-
\(f^{−1}(f(x))=f^{−1}(\frac{x+5}{3})=3(\frac{x+5}{3})−5=(x−5)+5=x\)
\(f(f^{−1}(x))=f(3x−5)=\frac{(3x−5)+5}{3}=\frac{3x}{3}=x\)
Example \(\PageIndex{2}\): Finding the Inverse of a Cubic Function
Find the inverse of the function \(f(x)=5x^3+1\).
Solution
This is a transformation of the basic cubic toolkit function, and based on our knowledge of that function, we know it is one-to-one. Solve for the inverse by interchanging \(x\) and \(y\) and solving for \(y\).
\(y=5x^3+1\)
\(x=5y^3+1\)
\(x−1=5y^3\)
\(\dfrac{x−1}{5}=y^3\)
\(f^{−1}(x)=\sqrt[3]{\dfrac{x−1}{5}}\)
Analysis
Look at the graph of \(f\) and \(f^{–1}\). Notice that one graph is the reflection of the other about the line \(y=x\). This is always the case when graphing a function and its inverse function.
Also, since the method involved interchanging \(x\) and \(y\), notice corresponding points. If \((a,b)\) is on the graph of \(f\),then \((b,a)\) is on the graph of \(f^{–1}\). Since \((0,1)\) is on the graph of \(f\), then \((1,0)\) is on the graph of \(f^{–1}\). Similarly, since \((1,6)\) is on the graph of \(f\),then \((6,1)\) is on the graph of \(f^{–1}\) (Figure \(\PageIndex{4}\)).
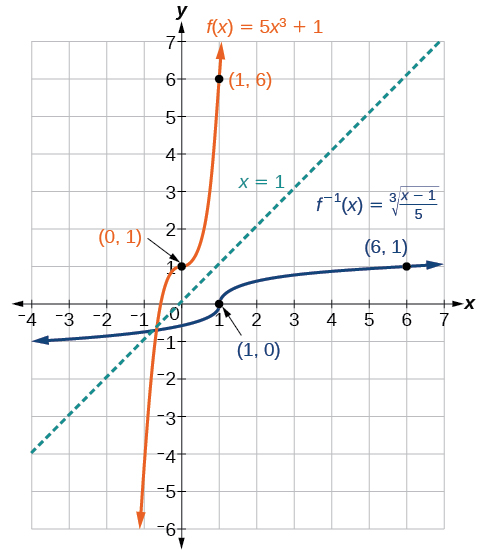
Figure \(\PageIndex{4}\)
![]() \(\PageIndex{2}\): Find the inverse function of \(f(x)=\sqrt[3]{x+4}\).
\(\PageIndex{2}\): Find the inverse function of \(f(x)=\sqrt[3]{x+4}\).
- Answer
-
\(f^{−1}(x)=x^3−4\)
Restricting the Domain to Find the Inverse of a Polynomial Function
So far, we have been able to find the inverse functions of cubic functions without having to restrict their domains. However, as we know, not all cubic polynomials are one-to-one. Some functions that are not one-to-one may have their domain restricted so that they are one-to-one, but only over that domain. The function over the restricted domain would then have an inverse function. Since quadratic functions are not one-to-one, we must restrict their domain in order to find their inverses.
RESTRICTING THE DOMAIN
If a function is not one-to-one, it cannot have an inverse. If we restrict the domain of the function so that it becomes one-to-one, thus creating a new function, this new function will have an inverse.
![]() Given a polynomial function, restrict the domain of a function that is not one-to-one and then find the inverse
Given a polynomial function, restrict the domain of a function that is not one-to-one and then find the inverse
- Restrict the domain by determining a smaller domain on which the original function is one-to-one.
- Replace \(f(x)\) with \(y\).
- Interchange \(x\) and \(y\).
- Solve for \(y\), and rename the function \(f^{−1}(x)\).
- Revise the formula for \(f^{−1}(x)\) by ensuring that the outputs of the inverse function correspond to the restricted domain of the original function.
Example \(\PageIndex{3}\): Restricting the Domain to Find the Inverse of a Polynomial Function
Find the inverse function of \(f\), for the following functions:
- \(f(x)={(x−4)}^2\), \(x≥4\)
- \(f(x)={(x−4)}^2\), \(x≤4\)
Note: Although the formula is the same in each case, these two functions are not considered the same, because their domains are different.
Solution
The original function \(f(x)={(x−4)}^2\) is not one-to-one, but the function is restricted to a domain of \(x≥4\) (for the first case) or \(x≤4\) (for the second case) on which it is one-to-one (Figure \(\PageIndex{5}\)).

Figure \(\PageIndex{5}\)
To find the inverse, start by replacing \(f(x)\) with the variable \(y\).
\(y={(x−4)}^2\) Interchange \(x\) and \(y\).
\(x={(y−4)}^2\) Take the square root.
\(\pm \sqrt{x}=y−4\) Add \(4\) to both sides.
\(4\pm \sqrt{x} =y\)
This is not a function as written. We need to examine the restrictions on the domain of the original function to determine the inverse.
- The domain of the original function was restricted to \(x≥4\), so the outputs of the inverse need to be the same, \(f^{-1}(x)≥4\), and we must use the + case:
\(f^{−1}(x)=4+\sqrt{x}\)
- The domain of the original function was restricted to \(x≤4\), so the outputs of the inverse need to be the same, \(f^{-1}(x)≤4\), and we must use the – case:
\(f^{−1}(x)=4−\sqrt{x}\)
Note: for both of the restrictions (case 1 and case 2) of the original function, the range is the same, \([0, \infty)\). Thus, the domain for the inverse in the first case is the same as the domain for the inverse in the second case: \(D = [0, \infty)\).
Analysis
On the graphs in Figure \(\PageIndex{6}\), we see the original function graphed on the same set of axes as its inverse function. Notice that together the graphs show symmetry about the line \(y=x\). The coordinate pair \((4,0)\) is on the graph off f and the coordinate pair \((0, 4)\) is on the graph of \(f^{−1}\). For any coordinate pair, if \((a, b)\) is on the graph of \(f\), then \((b, a)\) is on the graph of \(f^{−1}\). Finally, observe that the graph of \(f\) intersects the graph of \(f^{−1}\) on the line \(y=x\). Points of intersection for the graphs of \(f\) and \(f^{−1}\) will always lie on the line \(y=x\).

Figure \(\PageIndex{6}\)
Example \(\PageIndex{4}\): Finding the Inverse of a Quadratic Function When the Restriction Is Not Specified
Restrict the domain and then find the inverse of
\(f(x)={(x−2)}^2−3\).
Solution:
We can see this is a parabola with vertex at \((2,–3)\) that opens upward. Because the graph will be decreasing on one side of the vertex and increasing on the other side, we can restrict this function to a domain on which it will be one-to-one by limiting the domain to \(x≥2\).
To find the inverse, we will use the vertex form of the quadratic. We start by replacing \(f(x)\) with the variable, \(y\), then solve for \(x\).
\(y={(x−2)}^2−3\) Interchange \(x\) and \(y\).
\(x={(y−2)}^2−3\) Add 3 to both sides.
\(x+3={(y−2)}^2\) Take the square root.
\(\pm \sqrt{x+3}=y−2\) Add 2 to both sides.
\(2\pm \sqrt{x+3}=y\) Rename the function.
\(f^{−1}(x)=2\pm \sqrt{x+3}\)
Now we need to determine which case to use. Because we restricted our original function to a domain of \(x≥2\), the range (outputs) of the inverse should be the same, telling us to utilize the + case
\(f^{−1}(x)=2+\sqrt{x+3}\)
If the quadratic had not been given in vertex form, rewriting it into vertex form would be the first step. This way we may easily observe the coordinates of the vertex to help us restrict the domain.
Analysis
Notice that we arbitrarily decided to restrict the domain on \(x≥2\). We could just as easily have opted to restrict the domain to \(x≤2\), in which case \(f^{−1}(x)=2−\sqrt{x+3}\). Observe the original function graphed on the same set of axes as its inverse function in Figure \(\PageIndex{7}\). Notice that both graphs show symmetry about the line \(y=x\). The coordinate pair \((2, −3)\) is on the graph of \(f\) and the coordinate pair \((−3, 2)\) is on the graph of \(f^{−1}\). Observe from the graph of both functions on the same set of axes that
domain of \(f=\) range of \(f^{–1}=[2,\infty)\)
and
domain of \(f^{–1}=\) range of \(f=[–3,\infty)\).
Finally, observe that the graph of \(f\) intersects the graph of \(f^{−1}\) along the line \(y=x\).

Figure \(\PageIndex{7}\)
![]() \(\PageIndex{4}\): Find the inverse of the function \(f(x)=x^2+1\), on the domain \(x≥0\).
\(\PageIndex{4}\): Find the inverse of the function \(f(x)=x^2+1\), on the domain \(x≥0\).
- Answer
-
\(f^{−1}(x)=\sqrt{x−1}\)
Finding Inverses of Radical Functions
Notice that the functions from previous examples were all polynomials, and their inverses were radical functions. If we want to find the inverse of a radical function, we will need to restrict the domain of the answer because the range of the original function is limited.
![]() Given a radical function, find the inverse
Given a radical function, find the inverse
- Determine the range of the original function.
- Replace \(f(x)\) with \(y\), then solve for \(x\).
- If necessary, restrict the domain of the inverse function to the range of the original function.
Example \(\PageIndex{5}\): Finding the Inverse of a Radical Function
Find the inverse of the function \(f(x)=\sqrt{x−4}\) and then restrict its domain to the range of the original function.
Solution
Note that the original function has range \(f(x)≥0\). Replace \(f(x)\) with \(y\):
\[y=\sqrt{x−4}\]
Interchange \(x\) and \(y\):
\[x=\sqrt{y−4}\]
Square each side:\[x^2=y−4\]
Add 4:
\[x^2+4=y\]
Rename the function \(f^{−1}(x)\):
\[f^{−1}(x)=x^2+4\]
Recall that the domain of this function must be limited to the range of the original function.
\(f^{−1}(x)=x^2+4\), \(x≥0\)
Analysis
Notice in Figure \(\PageIndex{8}\) that the inverse is a reflection of the original function over the line \(y=x\). Because the original function has only nonnegative outputs, the inverse function has only nonnegative inputs.

Figure \(\PageIndex{8}\)
![]() \(\PageIndex{5}\): Restrict the domain and then find the inverse of the function \(f(x)=\sqrt{2x+3}\).
\(\PageIndex{5}\): Restrict the domain and then find the inverse of the function \(f(x)=\sqrt{2x+3}\).
- Answer
-
\(f^{−1}(x)=\frac{x^2−3}{2}\), \(x≥0\)
Solving Applications of Radical Functions
Radical functions are common in physical models, as we saw in the section opener. We now have enough tools to be able to solve the problem posed at the start of the section.
Example \(\PageIndex{6}\): Solving an Application with a Cubic Function
A mound of gravel is in the shape of a cone with the height equal to twice the radius. The volume of the cone in terms of the radius is given by
\[V=\dfrac{2}{3}\pi r^3 \nonumber\]
Find the inverse of the function \(V=\frac{2}{3}\pi r^3\) that determines the volume \(V\) of a cone and is a function of the radius \(r\). Then use the inverse function to calculate the radius of such a mound of gravel measuring 100.00 cubic feet. Use \(\pi=3.1416\).
Solution:
Start with the given function for \(V\). Notice that the meaningful domain for the function is \(r>0\) since negative radii would not make sense in this context nor would a radius of \(0\). Also note the range of the function (hence, the domain of the inverse function) is \(V>0\). Solve for \(r\) in terms of \(V\), using the method outlined previously. Note that in real-world applications, we do not swap the variables when finding inverses. Instead, we change which variable is considered to be the independent variable.
\[ V =\dfrac{2}{3}\pi r^3\nonumber \]
Solve for \(r^3\):
\[r^3 =\dfrac{3V}{2\pi} \nonumber\]
Solve for \(r\):
\[ r=\sqrt[3]{\dfrac{3V}{2\pi}} \nonumber \]
This is the result stated in the section opener. Now evaluate this for \(V=100.00\) and \(\pi=3.1416\).
\[ \begin{align*} r&=\sqrt[3]{\dfrac{3V}{2\pi}} \\[5pt] &=\sqrt[3]{\dfrac{3⋅100.00}{2⋅3.1416}} \\[5pt] &≈\sqrt[3]{47.7707} \\[5pt] &≈3.63 \end{align*}\]
Therefore, the radius is about 3.63 ft. (Anybody who is a science major knows how many significant figures we should be using in the answer. Your professor guesses 3. If you can write down the rules for significant figures in calculated quantities, give them to your professor and make her give you extra credit.)
Determining the Domain of a Radical Function Composed with Other Functions
When radical functions are composed with other functions, determining domain can become more complicated.
Example \(\PageIndex{7}\): Finding the Domain of a Radical Function Composed with a Rational Function
Find the domain of the function:
\[f(x)=\sqrt{\frac{(x+2)(x−3)}{(x−1)}}. \nonumber\]
Solution
Because a square root is only defined when the quantity under the radical is non-negative, we need to determine where
\[\frac{(x+2)(x−3)}{(x−1)}≥0. \nonumber\]
The output of a rational function can change signs (change from positive to negative or vice versa) at x-intercepts and at vertical asymptotes. For this equation, the graph could change signs at \(x=–2\), \(1\), and \(3\).
To determine the intervals on which the rational expression is positive, we could test some values in the expression or sketch a graph. While both approaches work equally well, for this example we will use a graph as shown in Figure \(\PageIndex{9}\).

Figure \(\PageIndex{9}\)
This function has two x-intercepts, both of which exhibit linear behavior near the x-intercepts. There is one vertical asymptote, corresponding to a linear factor; this behavior is similar to the basic reciprocal toolkit function, and there is no horizontal asymptote because the degree of the numerator is larger than the degree of the denominator. There is a y-intercept at \((0,\sqrt{6})\).
From the y-intercept and x-intercept at \(x=−2\), we can sketch the left side of the graph. From the behavior at the asymptote, we can sketch the right side of the graph.
From the graph, we can now tell on which intervals the outputs will be non-negative, so that we can be sure that the original function \(f(x)\) will be defined. \(f(x)\) has domain \(−2≤x<1\) or \(x≥3\), or in interval notation, \([−2,1)∪[3,\infty)\).
Finding Inverses of Rational Functions
As with finding inverses of quadratic functions, it is sometimes desirable to find the inverse of a rational function, particularly of rational functions that are the ratio of linear functions, such as in concentration applications.
Example \(\PageIndex{8}\): Finding the Inverse of a Rational Function
The function
\[\displaystyle C=\frac{20+0.4n}{100+n}\]
represents the concentration \(C\) of an acid solution after \(n\) mL of 40% solution has been added to 100 mL of a 20% solution. First, find the inverse of the function; that is, find an expression for \(n\) in terms of \(C\). Then use your result to determine how much of the 40% solution should be added so that the final mixture is a 35% solution.
Solution
We first want the inverse of the function in order to determine how many mL we need for a given concentration. We will solve for \(n\) in terms of \(C\).
\[ \begin{align*} C&=\dfrac{20+0.4n}{100+n} \\[5pt] C(100+n)&=20+0.4n\\[5pt] 100C+Cn&=20+0.4n\\[5pt] 100C−20&=0.4n−Cn\\[5pt] 100C−20&=(0.4−C)n\\[5pt] n&=\dfrac{100C−20}{0.4−C}\end{align*}\]
Now evaluate this function at 35%, which is \(C=0.35\).
\[ \begin{align*} n&=\dfrac{100(0.35)−20}{0.4−0.35}\\[5pt] &=\dfrac{15}{0.05}\\[5pt] &=300\end{align*}\]
We can conclude that 300 mL of the 40% solution should be added.
![]() \(\PageIndex{8}\): Find the inverse of the function \(f(x)=\frac{x+3}{x−2}\).
\(\PageIndex{8}\): Find the inverse of the function \(f(x)=\frac{x+3}{x−2}\).
- Answer
-
\(f^{−1}(x)=\frac{2x+3}{x−1}\)
Media
Access these online resources for additional instruction and practice with inverses and radical functions.
Key Concepts
- The inverse of a quadratic function is a square root function.
- If \(f^{−1}\) is the inverse of a function \(f\), then \(f\) is the inverse of the function \(f^{−1}\).
- While it is not possible to find an inverse of most polynomial functions, some basic polynomials are invertible.
- To find the inverse of certain functions, we must restrict the function to a domain on which it will be one-to-one.
- When finding the inverse of a radical function, we need a restriction on the domain of the answer.
- Inverse and radical and functions can be used to solve application problems.