
22.7: J1.07- Section 2 Example 6
( \newcommand{\kernel}{\mathrm{null}\,}\)
Example 6: Comparing different models of sales-data history (when both fit the data)
The dataset below of total retail sales in the United States from 1992 to 1999 looks as if it could be fit pretty closely by a linear model, in which sales increase by the same amount each year. However, most economic trends increase by about the same percentage each year on the average, so an exponential model might be more appropriate and would also be a good fit. To choose between these alternatives, we will find both best-fit models and examine what happens to them when extrapolated back 20 years.
| 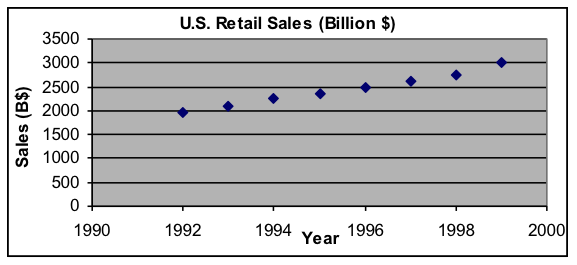 |
Question: For this data, which model has more reasonable extrapolation behavior—linear or exponential?
Solution approach:
[1] Copy the dataset into the Data Scratch Pad worksheet in Models.xls and modify it so that the input variable is years since 1992. This will make the model parameters easier to find. (The redefined dataset is shown to the right.)
[2] Use a copy of the Linear Model template to find the best linear model, which is about
[3] Use the Exponential Model template to find the best exponential model, which is about
[5] Note that the graphs of the two models both fit the data well.
| Since 1992 | Sales (B$) |
| 0 | 1,952 |
| 1 | 2,082 |
| 2 | 2,248 |
| 3 | 2,359 |
| 4 | 2,502 |
| 5 | 2,611 |
| 6 | 2,746 |
| 7 | 2,995 |
In both the Linear Model and Exponential Model worksheets, follow these steps:
[a] Insert the values from -1 to -20 into column A below the existing data. These new input values correspond to the years from 1991 back to 1972. [6] In both the Linear Model and Exponential Model worksheets, follow these steps:
[b] Spread the formula in column C down as far as the new input values. This will give the sales prediction of that model for the previous 20 years. The results for the two models should look like the worksheet extracts shown below.
| Extracts from Models.xls worksheets, with extrapolations back for 20 years | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Linear Model
| Exponential Model
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
[c] Make a new graph of the data and model (the A1:C30 rectangle of cells). In the graphs below showing the extrapolations, the scales have been set to equal and gridlines have been omitted, to make comparisons easier. But default-setting graphs will have the same information.
[6] Compare the extrapolated models. In this case, the linear extrapolation back 20 years predicts negative sales totals in 1972, which is obviously unrealistic. The exponential model remains positive regardless of how far back it is extrapolated, which shows that the exponential model is a much better choice for a sales model.
- Mathematics for Modeling. Authored by: Mary Parker and Hunter Ellinger. License: CC BY: Attribution