
1.1: Vectors
- Page ID
- 605

\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\dsum}{\displaystyle\sum\limits} \)
\( \newcommand{\dint}{\displaystyle\int\limits} \)
\( \newcommand{\dlim}{\displaystyle\lim\limits} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)Directed Line Segments and Vectors
A directed line segment is defined as an initial point, \(P\), and a terminal point \(Q\).
\[P = (2,3) \;\;\; \text{and} \;\;\; Q = (-1,4) \nonumber \]
Definition: Vector
A vector is the equivalence class of all directed segments of the same length and direction.
We can represent a vector by writing the unique directed line segment that has its initial point at the origin.
The vector between
\[P = (2,3) \;\;\; \text{and} \;\;\; Q = (-1,4) \nonumber \]
is equivalent to the directed line segment
\[Q - P = \langle -3, 1 \rangle \nonumber \]
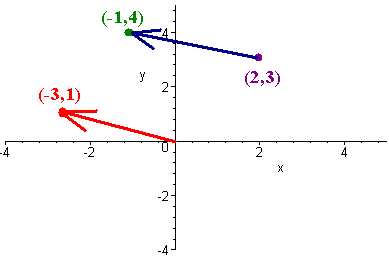
When we write the \(\langle \rangle\), we mean that the vector has initial point at the origin and terminal point at \((-3,1)\). This notation is called the component form of the vector.
The length of the vector \(\langle x,y\rangle\) is called the norm or magnitude of the vector. We can find it by the formula:
\[||\langle x,y\rangle|| = \sqrt{x^2+y^2} \nonumber \]
\[ ||\langle 3,1\rangle|| = \sqrt{3^2 + 1^1} = \sqrt{10} \nonumber \]
We also use the notation
\[-3 \hat{\textbf{i}} + \hat{\textbf{j}} \nonumber \]
to denote the vector \(\langle -3,1\rangle\).
A vector that has length 10 makes an angle of \(\dfrac{\pi}{6}\) with the x-axis. Find its components.
Solution
\[x= r \cos q, \;\;\; y = r \sin q \nonumber \]
So that
\[x= (10)(\dfrac{\sqrt{3}}{2}), \;\;\; y = 10 (\dfrac{1}{2}) = 5. \nonumber \]
We can write the vector as
\[5 \sqrt{3} \hat{\textbf{i}} + 5 \hat{\textbf{j}}. \nonumber \]
Unit Vectors in the Direction of \(\textbf{v}\)
A vector is called a unit vector if it has magnitude = 1. If
\[\textbf{v} = \langle a,b\rangle \nonumber \]
Then the unit vector in the direction of v can be found below.
\[ u = \dfrac{1}{||\textbf{v}||} \textbf{v} \nonumber \]
The unit vector in the direction of \(\langle -3,1\rangle\) is
\[- \dfrac{3}{\sqrt{10}}, \dfrac{1}{\sqrt{10}}. \nonumber \]
We can use the \(\langle \rangle\) notation and the \(\hat{\textbf{i}}\), \(\hat{\textbf{j}}\) notation interchangeably.
Algebra of Vectors
If
\[\textbf{v} = \langle a,b\rangle \;\;\; \text{and} \;\;\; \textbf{w} = \langle c,d\rangle \nonumber \]
and \(k\) is a constant, then we can define the sum an scalar multiplication as below.
\[v + w = \langle a + c,b + d\rangle \nonumber \]
and
\[kv = \langle ka, kb\rangle \nonumber \]
\[\begin{align*} 3 \langle 2,1\rangle - 2\langle -1,3\rangle = \langle 6 + 2,3 - 6\rangle = \langle 8,-3\rangle = 8\hat{\textbf{i}} - 3 \hat{\textbf{j}} \end{align*} \]
Geometrically v + w is the vector that corresponds to the diagonal of the parallelogram with two sides v and w.
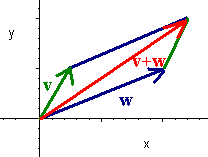
The appropriate diagram can also be drawn to show how
\[\textbf{v} - \textbf{w} = \textbf{v} + (-\textbf{w}). \nonumber \]
We have the following four properties of vectors: If u, v ,and w are vectors and a and b are scalars (numbers) then
- \[(\textbf{u} + \textbf{v}) + \textbf{w} = \textbf{u} + (\textbf{v} + \textbf{w}), \nonumber \]
- \[a( \textbf{u} + \textbf{v} ) = a \textbf{u} + a \textbf{v}, \nonumber \]
- \[a(b \textbf{v} ) = (ab) \textbf{v}, \nonumber \]
- \[\textbf{u} + \textbf{v} = \textbf{v} + \textbf{u}. \nonumber \]
An boat captain wants to travel due south at 40 knots. If the current is moving northwest at 16 knots, in what direction and magnitude should he work the engine?
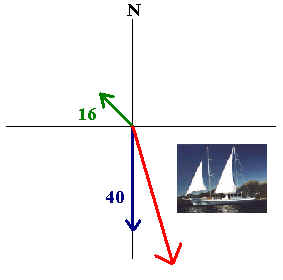
Solution
We have
\[\textbf{u} = \textbf{v} + \textbf{w} \nonumber \]
where u corresponds to the velocity vector of the boat, v corresponds to the engine's vector, and w corresponds to the velocity of the current. We have
\[\textbf{u} = -40 \hat{\textbf{j}} \;\;\; \text{and} \;\;\; \textbf{w} = -8\sqrt{2} \hat{\textbf{i}}+ 8 \sqrt{2} \hat{\textbf{j}} \nonumber \]
Hence
\[\textbf{v} = \textbf{u} - \textbf{w} = -40 \hat{\textbf{j}} - (-8 \sqrt{2} \hat{\textbf{i}} + 8 \sqrt{2} \hat{\textbf{j}} ) = 8 \sqrt{2} \hat{\textbf{i}} - (40+ 8\sqrt{2}) \hat{\textbf{j}}. \nonumber \]
The magnitude is
\[[(8 \sqrt{2})^2 + (40 + 8 \sqrt{2})^2]^{\frac{1}{2}}= 52.5. \nonumber \]
The direction is
\[ \tan^{-1} \Big(- \dfrac{40+8\sqrt{2}}{8 \sqrt{2}} \Big) = -1.35 \text{radians}. \nonumber \]
Dimensional Coordinates
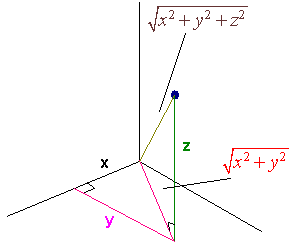
To generalize the plane to 3 dimensions, we draw a third axis, called the z-axis at a right angle from the plane so that if you grab on to the z-axis with your right hand your hand will curl from the positive x-axis to the positive y-axis. To plot a point in the xyz-space We first plot a point in the xy-plane and then draw a segment parallel to the z-axis of length equal to the z coordinate.
Plot \((1,2,3)\).
Solution
We first draw the x,y, and z-axes. Then we plot the point \((1,2)\) in the xy-plane. Finally move up three units and plot the point.
Plot \((2,4,3)\).
The Distance Formula
The distance formula is derived from the three dimensional version of the Pythagorean theorem, which is displayed below.
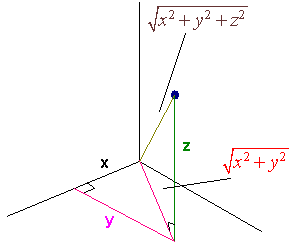
The distance between two points \(x_1, y_1, z_1 \) and \(x_2, y_2, z_2 \) and is given below.
\[D = \sqrt{ (x_2 - x_1)^2 + (y_2 - y_1)^2 + (z_2-z_1)^2 } \nonumber \]
Algebra of vectors in 3D
A vector in space is given by
\[\langle x,y,z\rangle = x \hat{\textbf{i}} + y \hat{\textbf{j}} + z \hat{\textbf{k}} \nonumber \]
The algebra rules are similar to those in two dimensions.
Contributors and Attributions
- Larry Green (Lake Tahoe Community College)
Integrated by Justin Marshall.