
1.7: Numerical methods: Euler’s method
- Page ID
- 334

\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\dsum}{\displaystyle\sum\limits} \)
\( \newcommand{\dint}{\displaystyle\int\limits} \)
\( \newcommand{\dlim}{\displaystyle\lim\limits} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\(\newcommand{\longvect}{\overrightarrow}\)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)At this point it may be good to first try the Lab II and/or Project II from the IODE website: www.math.uiuc.edu/iode/. As we said before, unless \(f(x, y)\) is of a special form, it is generally very hard if not impossible to get a nice formula for the solution of the problem
\[y' = f(x, y), \, \, \, \, \,\, y(x_0) = y_0 \nonumber \]
If the equation can be solved in closed form, we should do that. But what if we have an equation that cannot be solved in closed form? What if we want to find the value of the solution at some particular \(x\)? Or perhaps we want to produce a graph of the solution to inspect the behavior. In this section we will learn about the basics of numerical approximation of solutions.
The simplest method for approximating a solution is Euler's Method.\(^{1}\) It works as follows: Take \(x_0\) and compute the slope \(k = f(x_0,y_0)\). The slope is the change in \(y\) per unit change in \(x\). Follow the line for an interval of length \(h\) on the \(x\)-axis. Hence if \(y = y_0\) at \(x_0\), then we say that \(y_1\) (the approximate value of \(y\) at \(x_1 = x_0 + h\)) is \(y_1 = y_0 + h k\). Rinse, repeat! Let \(k = f(x_1,y_1)\), and then compute \(x_2 = x_1 + h\), and \(y_2 = y_1 + h k\). Now compute \(x_3\) and \(y_3\) using \(x_2\) and \(y_2\), etc. Consider the equation \(y' = \frac{y^2}{3}\), \(y(0)=1\), and \(h=1\). Then \(x_0=0\) and \(y_0 = 1\). We compute
\[\begin{align}\begin{aligned} & x_1 = x_0 + h = 0 + 1 = 1, & & y_1 = y_0 + h \, f(x_0,y_0) = 1 + 1 \cdot \frac{1}{3} = \frac{4}{3} \approx 1.333,\\ & x_2 = x_1 + h = 1 + 1 = 2, & & y_2 = y_1 + h \, f(x_1,y_1) = \frac{4}{3} + 1 \cdot \frac{{(\frac{4}{3})}^2}{3} = \frac{52}{27} \approx 1.926.\end{aligned}\end{align} \nonumber \]
We then draw an approximate graph of the solution by connecting the points \((x_0,y_0)\), \((x_1,y_1)\), \((x_2,y_2)\),…. For the first two steps of the method see Figure \(\PageIndex{1}\).
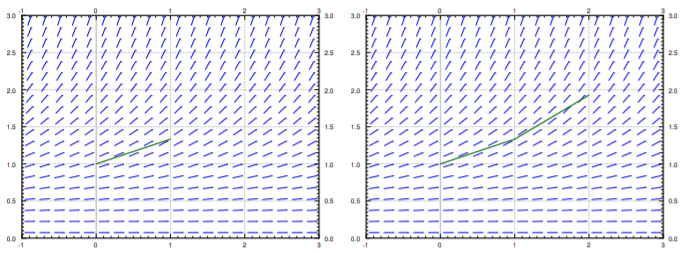
More abstractly, for any \(i=0,1,2,3,\ldots\), we compute \[x_{i+1} = x_i + h , \qquad y_{i+1} = y_i + h\, f(x_i,y_i) . \nonumber \]
The line segments we get are an approximate graph of the solution. Generally it is not exactly the solution. See Figure \(\PageIndex{2}\) for the plot of the real solution and the approximation.
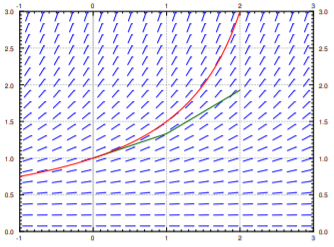
We continue with the equation \(y' = \frac{y^2}{3}\), \(y(0)=1\). Let us try to approximate \(y(2)\) using Euler’s method. In Figures \(\PageIndex{1}\) and \(\PageIndex{2}\) we have graphically approximated \(y(2)\) with step size 1. With step size 1, we have \(y(2) \approx 1.926\). The real answer is 3. We are approximately \(1.074\) off. Let us halve the step size. Computing \(y_4\) with \(h=0.5\), we find that \(y(2) \approx 2.209\), so an error of about \(0.791\). Table \(\PageIndex{1}\) gives the values computed for various parameters.
Solve this equation exactly and show that \(y(2) = 3\).
The difference between the actual solution and the approximate solution we will call the error. We will usually talk about just the size of the error and we do not care much about its sign. The main point is, that we usually do not know the real solution, so we only have a vague understanding of the error. If we knew the error exactly …what is the point of doing the approximation?
| \(h\) | Approximate \(y(2)\) | Error | \(\frac{\text{Error}}{\text{Previous error}}\) |
|---|---|---|---|
| 1 | 1.92593 | 1.07407 | |
| 0.5 | 2.20861 | 0.79139 | 0.73681 |
| 0.25 | 2.47250 | 0.52751 | 0.66656 |
| 0.125 | 2.68034 | 0.31966 | 0.60599 |
| 0.0625 | 2.82040 | 0.17960 | 0.56184 |
| 0.03125 | 2.90412 | 0.09588 | 0.53385 |
| 0.015625 | 2.95035 | 0.04965 | 0.51779 |
| 0.0078125 | 2.97472 | 0.02528 | 0.50913 |
Table \(\PageIndex{1}\): Euler’s method approximation of \(y(2)\) where of \(y' = \frac{y^2}{3}\), \(y(0) = 1\).
We notice that except for the first few times, every time we halved the interval the error approximately halved. This halving of the error is a general feature of Euler’s method as it is a first order method. In the IODE Project II you are asked to implement a second order method. A second order method reduces the error to approximately one quarter every time we halve the interval (second order as \(\frac{1}{4} = \frac{1}{2} \text{x} \frac{1}{2}\)).
To get the error to be within 0.1 of the answer we had to already do 64 steps. To get it to within 0.01 we would have to halve another three or four times, meaning doing 512 to 1024 steps. That is quite a bit to do by hand. The improved Euler method from IODE Project II should quarter the error every time we halve the interval, so we would have to approximately do half as many “halvings” to get the same error. This reduction can be a big deal. With 10 halvings (starting at \(h = 1\)) we have 1024 steps, whereas with 5 halvings we only have to do 32 steps, assuming that the error was comparable to start with. A computer may not care about this difference for a problem this simple, but suppose each step would take a second to compute (the function may be substantially more difficult to compute than \(\frac{y^2}{3}\)). Then the difference is 32 seconds versus about 17 minutes. Note: We are not being altogether fair, a second order method would probably double the time to do each step. Even so, it is 1 minute versus 17 minutes. Next, suppose that we have to repeat such a calculation for different parameters a thousand times. You get the idea.
Note that in practice we do not know how large the error is! How do we know what is the right step size? Well, essentially we keep halving the interval, and if we are lucky, we can estimate the error from a few of these calculations and the assumption that the error goes down by a factor of one half each time (if we are using standard Euler).
In the table above, suppose you do not know the error. Take the approximate values of the function in the last two lines, assume that the error goes down by a factor of 2. Can you estimate the error in the last time from this? Does it (approximately) agree with the table? Now do it for the first two rows. Does this agree with the table?
Let us talk a little bit more about the example \(y' = \frac{y^2}{3}\), \(y(0) = 1\). Suppose that instead of the value \( y(2)\) we wish to find \(y(3)\). The results of this effort are listed in Table \(\PageIndex{2}\) for successive halvings of \(h\). What is going on here? Well, you should solve the equation exactly and you will notice that the solution does not exist at \(x =3\). In fact, the solution goes to infinity when you approach \(x =3\).
| \(h\) | Approximate \(y(3)\) |
|---|---|
| 1 | 3.16232 |
| 0.5 | 4.54329 |
| 0.25 | 6.86079 |
| 0.125 | 10.80321 |
| 0.0625 | 17.59893 |
| 0.03125 | 29.46004 |
| 0.015625 | 50.40121 |
| 0.0078125 | 87.75769 |
Table \(\PageIndex{2}\): Attempts to use Euler’s to approximate \(y(3)\) where of \(y' = \frac{y^2}{3}\), \(y(0) = 1\).
Another case when things can go bad is if the solution oscillates wildly near some point. Such an example is given in IODE Project II. The solution may exist at all points, but even a much better numerical method than Euler would need an insanely small step size to approximate the solution with reasonable precision. And computers might not be able to easily handle such a small step size.
In real applications we would not use a simple method such as Euler’s. The simplest method that would probably be used in a real application is the standard Runge-Kutta method (see exercises). That is a fourth order method, meaning that if we halve the interval, the error generally goes down by a factor of 16 (it is fourth order as \(\frac{1}{16} = \frac{1}{2} \text{x} \frac{1}{2} \text{x} \frac{1}{2} \text{x} \frac{1}{2}\)).
Choosing the right method to use and the right step size can be very tricky. There are several competing factors to consider.
- Computational time: Each step takes computer time. Even if the function \(f\) is simple to compute, we do it many times over. Large step size means faster computation, but perhaps not the right precision.
- Roundoff errors: Computers only compute with a certain number of significant digits. Errors introduced by rounding numbers off during our computations become noticeable when the step size becomes too small relative to the quantities we are working with. So reducing step size may in fact make errors worse.
- Stability: Certain equations may be numerically unstable. What may happen is that the numbers never seem to stabilize no matter how many times we halve the interval. We may need a ridiculously small interval size, which may not be practical due to roundoff errors or computational time considerations. Such problems are sometimes called stiff. In the worst case, the numerical computations might be giving us bogus numbers that look like a correct answer. Just because the numbers have stabilized after successive halving, does not mean that we must have the right answer.
We have seen just the beginnings of the challenges that appear in real applications. Numerical approximation of solutions to differential equations is an active research area for engineers and mathematicians. For example, the general purpose method used for the ODE solver in Matlab and Octave (as of this writing) is a method that appeared in the literature only in the 1980s.
Footnotes
[1] Named after the Swiss mathematician Leonhard Paul Euler (1707–1783). The correct pronunciation of the name sounds more like “oiler.”