
9.2: Ego Network Data

( \newcommand{\kernel}{\mathrm{null}\,}\)
Ego network data commonly arise in two ways:
Surveys may be used to collect information on ego networks. We can ask each research subject to identify all of the actors to whom they have a connection, and to report to us (as an informant) what the ties are among these other actors. Alternatively, we could use a two-stage snowball method; first, ask ego to identify others to whom ego has a tie, then ask each of those identified about their ties to each of the others identified.
Data collected in this way cannot directly inform us about the overall embeddedness of the networks in a population, but it can give us information on the prevalence of various kinds of ego networks in even very large populations. When data are collected this way, we essentially have a data structure that is composed of a collection of networks. As the actors in each network are likely to be different people, the networks need to be treated as separate actor-by-actor matrices stored as different data sets (i.e. it isn't a good idea to "stack" the multiple networks in the same data file, because the multiple matrices do not represent multiple relations among the same set of actors).
A modification of the survey method can give rise to a multiplex data structure (that is, a "stack" of actor-by-actor matrices of equal dimension). If we ask each ego to characterize relation with the occupants of social roles (or a particular occupant of a role), and to also report on the relations among occupants of those roles, we can build "conformable" matrices for each ego. For example, suppose that we asked a number of egos "Do you have a male fried or friends in your classroom?", "Do you have a female friend or friends in your classroom?", and "Are your male friends friends of your female friends?", the resulting data for each ego would have three nodes (in the sense of social roles, but not individuals) they could be treated as a type of multiplex data that we will discuss more later on.
The second major way in which ego network data arise is by "extracting" them from regular complete network data. The Data>Extract approach can be used to select a single actor and their ties, but would not include the ties among the "alters". The Data>Subgraphs from partitions approach could be used if we had previously identified the members of a particular ego neighborhood, and stored this as an attribute vector.
More commonly, though, we would want to extract multiple, or even all of the ego networks from a full network to be stored as separate files. For this task, the Data>Egonet tool is ideal. Here is an example of the dialog for using the tool:
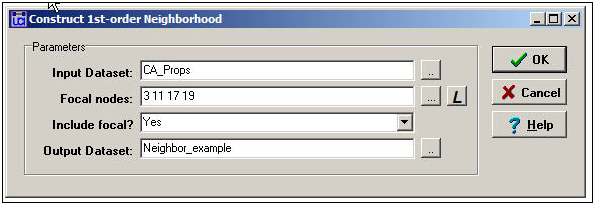
Figure 9.1: Dialog for Data>Egonet
Here we are focusing on ballot proposition campaigns in California that are connected by having donors in common (i.e. CA_Props is a proposition-by-proposition valued matrix). We've said that we want to extract a network that includes the 3rd, 11th, 17th, and 19th rows/columns, and all the nodes that are connected to any of these actors. More commonly, we might select a single "ego". The list of focal nodes can be provided either as an attribute file, by typing in the list of row numbers, or by selecting the node labels of the desired actors.
A picture of part of the resulting data, stored as a new file called "Neighbor_example" is shown in Figure 9.2.
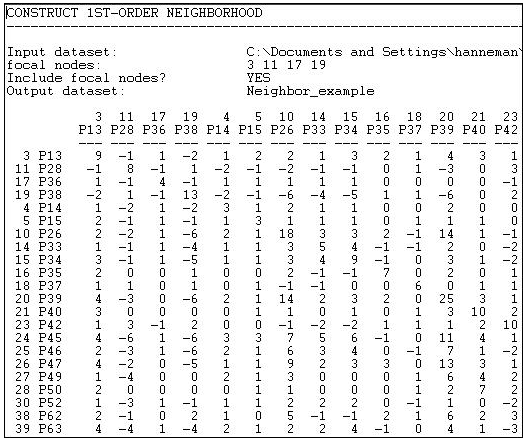
Figure 9.2: (Partial) output of Data>Egonet
Extracting sub-graphs, based on a focal actor or set of actors (e.g. "elites") can be a very useful way of looking at a part of a whole network, or the condition of an individual actor. The Data>Egonet tool is helpful for creating datasets that are good for graphing and separate analysis - particularly when the networks in which the focal actor/actors embedded are quite large.
It is not necessary, however, to create separate ego network datasets for each actor to be analyzed. The approaches to analysis that we'll review later generate output for the first-order ego network of every node in a dataset. For small datasets, there is often no need to extract separate ego networks.