
17.5: Qualitative Analysis
- Page ID
- 7758

\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\dsum}{\displaystyle\sum\limits} \)
\( \newcommand{\dint}{\displaystyle\int\limits} \)
\( \newcommand{\dlim}{\displaystyle\lim\limits} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\(\newcommand{\longvect}{\overrightarrow}\)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)Often all that we know about actors and events is simple co-presence. That is, either an actor was, or wasn't, present, and our incidence matrix is binary. In cases like this, the scaling methods in the last section can be applied, but one should be very cautious about the results. This is because the various dimensional methods operate on similarity/distance matrices, and measures like correlations (as used in two-mode factor analysis) can be misleading with binary data. Even correspondence analysis, which is more friendly to binary data, can be troublesome when data are sparse.
An alternative approach is block modeling. Block modeling works directly on the binary incidence matrix by trying to permute rows and columns to fit, as closely as possible, idealized images. This approach doesn't involve any of the distributional assumptions that are made in scaling analysis.
In principle, one could fit any sort of block model to actor-by-event incidence data. We will examine two models that ask meaningful (alternative) questions about the patterns of linkage between actors and events. Both of these models can be directly calculated in UCINET. Alternative block models, of course, could be fit to incidence data using more general block-modeling algorithms.
Two-Mode Core-Periphery Analysis
The core-periphery structure is an ideal typical pattern that divides both the rows and the columns into two classes. One of the blocks on the main diagonal (the core) is a high-density block; the other block on the main diagonal (the periphery) is a low-density block. The core-periphery model is indifferent to the density of ties in the off-diagonal blocks.
When we apply the core-periphery model to actor-by-actor data (see Network>Core/Periphery), the model seeks to identify a set of actors who have high density of ties among themselves (the core) by sharing many events in common, and another set of actors who have very low density of ties among themselves (the periphery) by having few events in common. Actors in the core are able to coordinate their actions, those in the periphery are not. As a consequence, actors in the core are at a structural advantage in exchange relations with actors in the periphery.
When we apply the core-periphery model to actor-by-event data (Network>2-Mode>Categorical Core/Periphery) we are seeking the same idealized "image" of a high and a low density block along the main diagonal. But, now the meaning is rather different.
The "core" consists of a partition of actors that are closely connected to each of the events in an event partition; and simultaneously a partition of events that are closely connected to the actors in the core partition. So, the "core" is a cluster of frequently co-occurring actors and events. The "periphery" consists of a partition of actors who are not co-incident to the same events; and a partition of events that are disjoint because they have no actors in common.
Network>2-Mode>Categorical Core/Periphery uses numerical methods to search for the partition of actors and of events that comes as close as possible to the idealized image. Figure 17.16 shows a portion of the results of applying this method to participation (not partisanship) in the California donors and initiatives data.
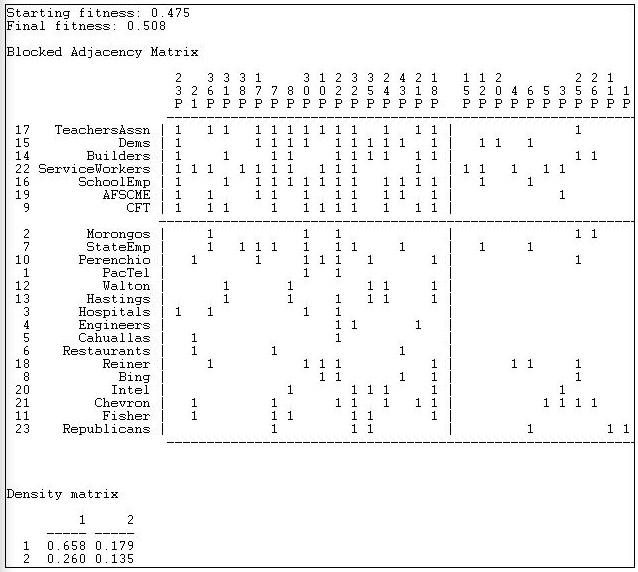
Figure 17.16: Categorical core-periphery model of California $1M donors and ballot initiatives (truncated)
The numerical search method used by Network>2-Mode>Categorical Core/Periphery is a genetic algorithm, and the measure of goodness of fit is stated in terms of a "fitness" score (0 means bad fit, 1 means excellent fit). You can also judge the goodness of the result by examining the density matrix at the end of the output. If the block model was completely successful, the 1,1 block should have a density of one, and the 2,2 block should have a density of zero. While far from perfect, the model here is good enough to be taken seriously.
The blocked matrix shows a "core" composed of the Democratic Party, a number of major unions, and the building industry association who are all very likely to participate in a considerable number of initiatives (proposition 23 through proposition 18). The remainder of the actors are grouped into the periphery as both participating less frequently, and having few issues in common. A considerable number of issues are also grouped as "peripheral" in the sense that they attract few donors, and these donors have little in common. We also see (upper right) that core actors do participate to some degree (0.179) in peripheral issues. In the lower left, we see that peripheral actors participate somewhat more heavily (0.260) in core issues.
Two-Mode Factions Analysis
An alternative block model is that of "factions". Factions are groupings that have high density within the group, and low density of ties between groups. Network>Subgroups>Factions fits this block model to one-mode data (for any user-specified number of factions). Network>2-Mode>2-Mode Factions fits the same type of model to two-mode data (but for only two factions).
When we apply the factions model to one-mode actor data, we are trying to identify two clusters of actors who are closely tied to one another by attending all of the same events, but very loosely connected to members of other factions and the events that tie them together. If we were to apply the idea of factions to events in a one-mode analysis, we would be seeking to identify events that were closely tied by having exactly the same participants.
Network>2-Mode>2-Mode Factions applies the same approach to the rectangular actor-by-event matrix. In doing this,we are trying to locate joint groupings of actors and events that are as mutually exclusive as possible. In principle, there could be more than two such factions. Figure 17.17 shows the results of the two-mode factions block model to the participation of top donors in political initiatives.

Figure 17.17: Two-mode factions model of California $1M donors and ballot initiatives (truncated)
Two measures of goodness-of-fit are available. First we have our "fitness" score, which is the correlation between the observed scores (0 or 1) and the scores that "should" be present in each block. The densities in the blocks also informs us about goodness of fit. For a factions analysis, an ideal pattern would be dense 1-blocks along the diagonal (many ties within groups) and zero-blocks off the diagonal (ties between groups).
The fit of the two factions model is not as impressive as the fit of the core-periphery model. This suggests that an "image" of California politics as one of two separate and largely disjoint issue-actor spaces is not as useful as an image of a high intensity core of actors and issues coupled with an otherwise disjoint set of issues and participants.
The blocking itself also is not very appealing, placing most of the actors in one faction (with modest density of 0.401). The second faction is small, and has a density (0.299) that is not very different from the off-diagonal blocks. As before, the blocking of actors by events is grouping together sets of actors and events that define one another.