
5.6: Asymptotic Behavior of Discrete-Time Linear Dynamical Systems





( \newcommand{\kernel}{\mathrm{null}\,}\)
One of the main objectives of rule-based modeling is to make predictions of the future. So, it is a natural question to ask where the system will eventually go in the (infinite) long run. This is called the asymptotic behavior of the system when time is taken to infinity, which turns out to be fully predictable if the system is linear.
Within the scope of discrete time models, linear dynamical systems are systems whose dynamics can be described as:
xt=Axt−1,
where x is the state vector of the system and A is the coefficient matrix. Technically, you could also add a constant vector to the right hand side, such as
xt=Axt−1+a,
but this can always be converted into a constant-free form by adding one more dimension, i.e.,
yt=(xt1)=(Aa01)=(xt−11)=Byt−1
Therefore, we can be assured that the constant-free form of Equati)on ??? covers all possible behaviors of linear difference equations.
Obviously, Equation ??? has the following closed-form solution:
xt=Atx0
This is simply because A is multiplied to the state vector x from the left at every time step. Now the key question is this: How will Eq. (5.1.3) behave when t→∞? In studying this, the exponential function of the matrix, At, is a nuisance. We need to turn it into a more tractable form in order to understand what will happen to this system as t gets bigger. And this is where eigenvalues and eigenvectors of the matrix A come to play a very important role. Just to recap, eigenvalues λi and eigenvectors vi of A are the scalars and vectors that satisfy
Avi=λiv1.
In other words, throwing at a matrix one of its eigenvectors will “destroy the matrix” and turn it into a mere scalar number, which is the eigenvalue that corresponds to the eigenvector used. If we repeatedly apply this “matrix neutralization” technique, we get
Atvi=At−1λivi=At−2λ2ivi=...=λtivi
This looks promising. Now,we just need to apply the above simplification to Equation ???. To do so, we need to represent the initial state x0 by using A’s eigenvectors as the basis vectors, i.e.,
x0=b1v1+b2v2+…+bnvn,
where n is the dimension of the state space (i.e., A is an n×n matrix). Most real-world n×n matrices are diagonalizable and thus have n linearly independent eigenvectors, so here we assume that we can use them as the basis vectors to represent any initial state x02. If you replace x0 with this new notation in Equation ???, we get the following:
xt=At(b1v1+b2v2+...+bnvn)=b1Atv1+b2Atv2+...+bnAtvn=b1λt1v1+b2λt2v2+...+bnλtnvn
This result clearly shows that the asymptotic behavior of xt is given by a summation of multiple exponential terms of λi. There are competitions among those exponential terms, and which term will eventually dominate the others is determined by the absolute value of λi. For example, if λ1. has the largest absolute value (|λ1|>|λ2|,|λ3|,...|λn|), then
xt=λt1(b1v1+b2(λ2λ1)tv2+....+bn(λnλ1)tvn
lim
This eigenvalue with the largest absolute value is called a dominant \ eigenvalue, and its corresponding eigenvector is called a dominant eigenvector, which will dictate which direction (a.k.a. mode in physics) the system’s state will be going asymptotically. Here is an important fact about linear dynamical systems:
If the coefficient matrix of a linear dynamical system has just one dominant eigenvalue, then the state of the system will asymptotically point to the direction given by its corresponding eigenvector regardless of the initial state.
This can be considered a very simple, trivial, linear version of self-organization. Let’s look at an example to better understand this concept. Consider the asymptotic behavior of the Fibonacci sequence:
x_{t} =x_{t-1} +x_{t-2}\label{(5.45)}
As we studied already, this equation can be turned into the following two-dimensional first-order model:
x_{t}=x_{t-1} +y_{t-1}\label{(5.46)}
y_{t} =x_{t-1}\label{ (5.47)}
This can be rewritten by letting (x_{t},y_{t}) ⇒ x_{t} and using a vector-matrix notation, as:
x_{t}=\binom{1 \ \ 1}{1 \ \ 0} x_{t-1}\label{(5.48)}
So, we just need to calculate the eigenvalues and eigenvectors of the above coefficient matrix to understand the asymptotic behavior of this system. Eigenvalues of a matrix A can be obtained by solving the following equation for λ:
\det\binom{1 -\lambda \ 1}{ 1 -\lambda} =-(1-\lambda)\lambda -1 =\lambda^{2} -\lambda-1 =0,\label{(5.50)}
which gives
\lambda = \frac{1\pm\sqrt{5}}{2}\label{(5.51)}
as its solutions. Note that one of them ((1 +√5)/2 = 1.618...) is the golden ratio! It is interesting that the golden ratio appears from such a simple dynamical system. Of course, you can also use Python to calculate the eigenvalues and eigenvectors (or, to be more precise, their approximated values). Do the following:

The eig function is there to calculate eigenvalues and eigenvectors of a square matrix. You immediately get the following results:

The first array shows the list of eigenvalues (it surely includes the golden ratio), while the second one shows the eigenvector matrix (i.e., a square matrix whose column vectors are eigenvectors of the original matrix). The eigenvectors are listed in the same order as eigenvalues. Now we need to interpret this result. The eigenvalues are 1.61803399 and -0.61803399. Which one is dominant? The answer is the first one, because its absolute value is greater than the second one’s. This means that, asymptotically, the system’s behavior looks like this:
x_{t} \approx 1.61803399x_{t-1}\label{(5.52)}
Namely, the dominant eigenvalue tells us the asymptotic ratio of magnitudes of the state vectors between two consecutive time points (in this case, it approaches the golden ratio). If the absolute value of the dominant eigenvalue is greater than 1, then the system will diverge to infinity, i.e., the system is unstable. If less than 1, the system will eventually shrink to zero, i.e., the system is stable. If it is precisely 1, then the dominant eigenvector component of the system’s state will be conserved with neither divergence nor convergence, and thus the system may converge to a non-zero equilibrium point. The same interpretation can be applied to non-dominant eigenvalues as well.
An eigenvalue tells us whether a particular component of a system’s state (given by its corresponding eigenvector) grows or shrinks over time. For discrete-time models:
• |λ| > 1 means that the component is growing.
• |λ| < 1 means that the component is shrinking.
• |λ| = 1 means that the component is conserved
For discrete-time models, the absolute value of the dominant eigenvalue λ_{d} determines the stability of the whole system as follows:
• |λ_{d}| > 1: The system is unstable, diverging to infinity.
• |λ_{d}| < 1: The system is stable, converging to the origin.
• |λ_{d}| = 1: The system is stable, but the dominant eigenvector component is conserved, and therefore the system may converge to a non-zero equilibrium point
We can now look at the dominant eigenvector that corresponds to the dominant eigenvalue, which is (0.85065081, 0.52573111). This eigenvector tells you the asymptotic direction of the system’s state. That is, after a long period of time, the system’s state (x_{t},y_{t}) will be proportional to (0.85065081, 0.52573111), regardless of its initial state. Let’s confirm this analytical result with computer simulations.
Visualize the phase space of Equation \ref{(5.48)}.
The results are shown in Fig. 5.6.1, for 3, 6, and 9 steps of simulation. As you can see in the figure, the system’s trajectories asymptotically diverge toward the direction given by the dominant eigenvector (0.85065081, 0.52573111), as predicted in the analysis above.
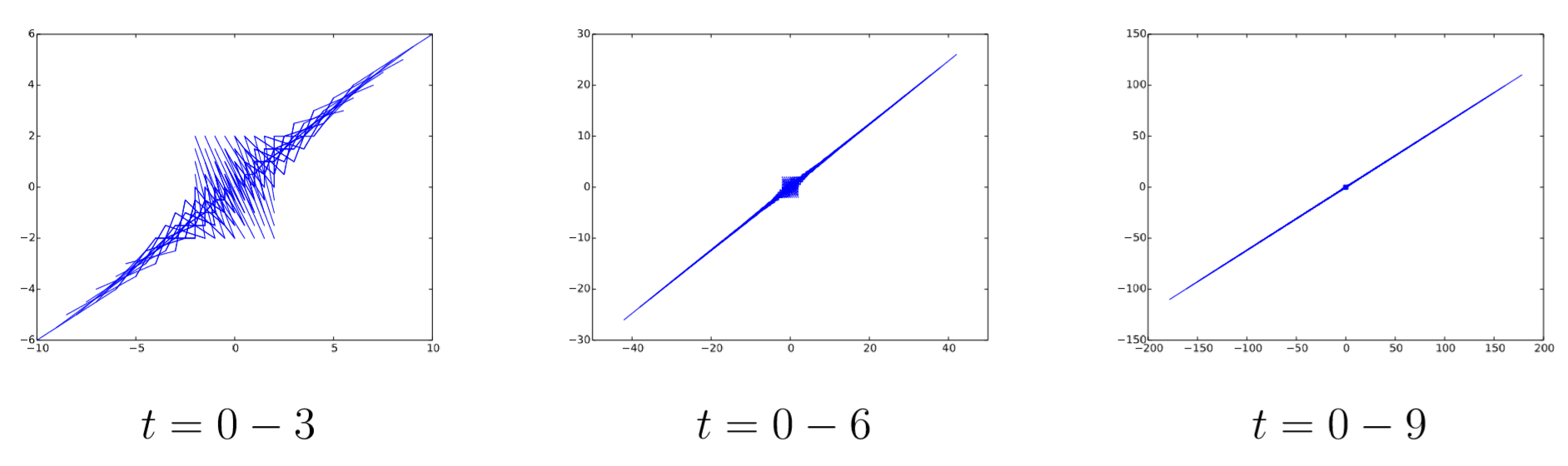
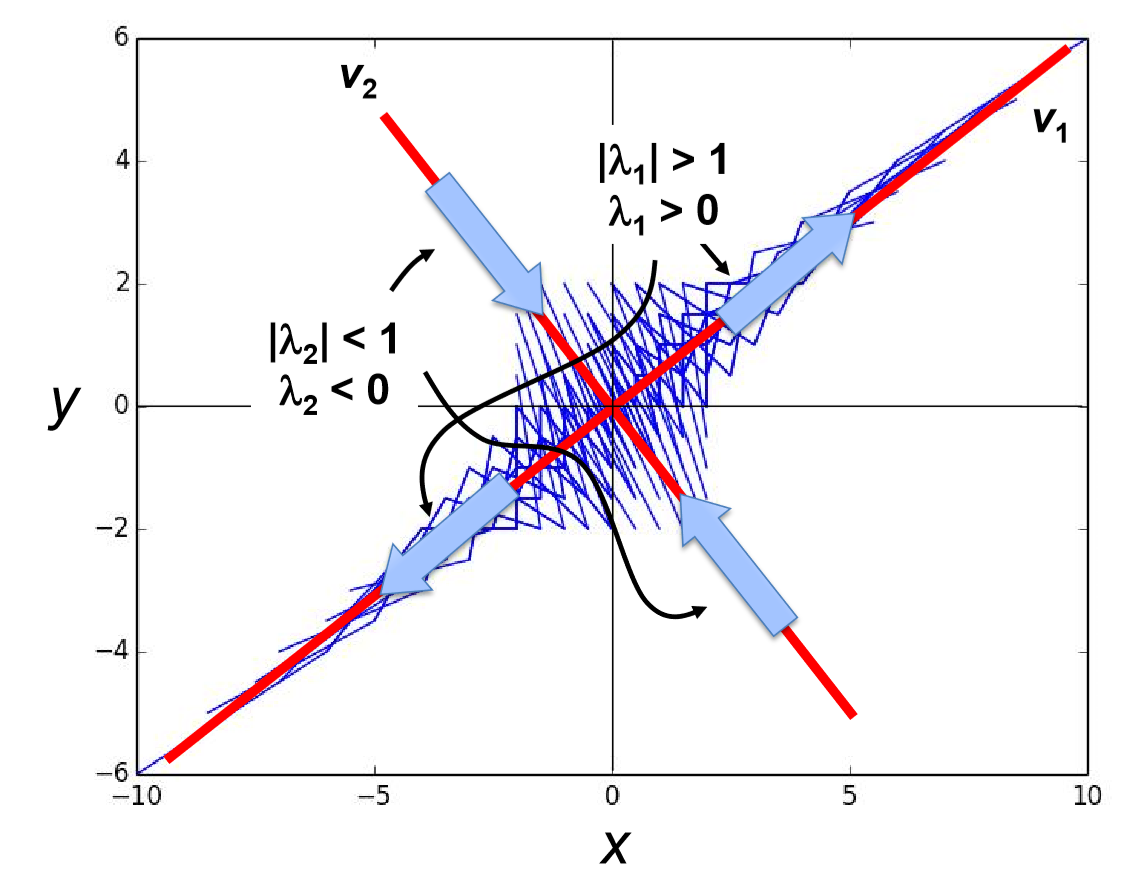
Figure 5.6.2 illustrates the relationships among the eigenvalues, eigenvectors, and the phase space of a discrete-time dynamical system. The two eigenvectors show the directions of two invariant lines in the phase space (shown in red). Any state on each of those lines will be mapped onto the same line. There is also an eigenvalue associated with each line (λ_{1} and λ_{2} in the figure). If its absolute value is greater than 1, the corresponding eigenvector component of the system’s state is growing exponentially ((λ_{1}, (v_{1}), whereas if it is less than 1, the component is shrinking exponentially ((λ_{2}, v_{2}). In addition, for discrete-time models, if the eigenvalue is negative, the corresponding eigenvector component alternates its sign with regard to the origin every time the system’s state is updated (which is the case for (λ_{2}, v_{2} in the figure).
Here is a summary perspective for you to understand the dynamics of linear systems:
Dynamics of a linear system are decomposable into multiple independent one-dimensional exponential dynamics, each of which takes place along the direction given by an eigenvector. A general trajectory from an arbitrary initial condition can be obtained by a simple linear superposition of those independent dynamics.
One more thing. Sometimes you may find some eigenvalues of a coefficient matrix to be complex conjugate, not real. This may happen only if the matrix is asymmetric (i.e., symmetric matrices always have only real eigenvalues). If this happens, the eigenvectors also take complex values, which means that there are no invariant lines in the phase space. So, what is happening there? The answer is rotation. As you remember, linear systems can show oscillatory behaviors, which are rotations in their phase space. In such cases, their coefficient matrices have complex conjugate eigenvalues. The meaning of the absolute values of those complex eigenvalues is still the same as before—greater than 1 means instability, and less than 1 means stability. Here is a summary:
If a linear system’s coefficient matrix has complex conjugate eigenvalues, the system’s state is rotating around the origin in its phase space. The absolute value of those complex conjugate eigenvalues still determines the stability of the system, as follows:
• |λ| > 1 means rotation with an expanding amplitude.
• |λ| < 1 means rotation with a shrinking amplitude.
• |λ| = 1 means rotation with a sustained amplitude.
Here is an example of such rotating systems, with coefficients taken from Code 4.13.
{kind=link}

The result is this:

Now we see the complex unit j (yes, Python uses j instead of i to represent the imaginary unit i) in the result, which means this system is showing oscillation. Moreover, you can calculate the absolute value of those eigenvalues:

Then the result is as follows:

This means that |λ| is essentially 1, indicating that the system shows sustained oscillation, as seen in Fig. 4.4.2. For higher-dimensional systems, various kinds of eigenvalues can appear in a mixed way; some of them may show exponential growth, some may show exponential decay, and some others may show rotation. This means that all of those behaviors are going on simultaneously and independently in the system. A list of all the eigenvalues is called the eigenvalue spectrum of the system (or just spectrum for short). The eigenvalue spectrum carries a lot of valuable information about the system’s behavior, but often, the most important information is whether the system is stable or not, which can be obtained from the dominant eigenvalue.
{kind=link}
Study the asymptotic behavior of the following three-dimensional difference equation model by calculating its eigenvalues and eigenvectors:
x_{t} = x_{t-1} -y_{t-1}\label{(5.53)}
y_{t} =-x_{t-1} -3y_{t-1} +z_{t-1}\label{(5.54)}
z_{t} =y_{t-1} +z_{t-1}\label{(5.55) }
Consider the dynamics of opinion diffusion among five people sitting in a ring-shaped structure. Each individual is connected to her two nearest neighbors (i.e., left and right). Initially they have random opinions (represented as random real numbers), but at every time step, each individual changes her opinion to the local average in her social neighborhood (i.e, her own opinion plus those of her two neighbors, divided by 3). Write down these dynamics as a linear difference equation with five variables, then study its asymptotic behavior by calculating its eigenvalues and eigenvectors.
What if a linear system has more than one dominant, real-valued eigenvalue? What does it imply for the relationship between the initial condition and the asymptotic behavior of the system?
2This assumption doesn’t apply to defective (non-diagonalizable) matrices that don’t have n linearly independent eigenvectors. However, such cases are rather rare in real-world applications, because any arbitrarily small perturbations added to a defective matrix would make it diagonalizable. Problems withs uch sensitive, ill-behaving properties are sometimes called pathological in mathematics and physics. For more details about matrix diagonalizability and other related issues, look at linear algebra textbooks, e.g. [28].