
1.1: Basic Set Theory
- Page ID
- 130481
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)The goal of this chapter is to understand what is meant when we use the word probability?
There is an informal way and a formal way to answer this. The informal way appeals towards our intuition and so allow us to first discuss the informal solution. To do so, we first make a preliminary definition.
The relative frequency of an event refers to the ratio of the number of times for which an event occurs to the the total number of trials.
For instance, suppose we were flipping a fair coin 500 times and we were interested in the relative frequency of obtaining a heads. The following code in R simulates the experiment:
Click the "run" button above to simulate the experiment. We may repeatedly click the "run" button to obtain different simulations of tossing 500 coins.
For concreteness, let us run the experiment and determine the output:
We see that in the above simulation, we ended up with 255 heads after a total of 500 flips or trials. Hence the relative frequency is \( \dfrac{255}{500} \). With this definition in mind, we can begin to informally understand probability.
The probability of an event refers to the likelihood or relative frequency for which the event occurs if the experiment were repeated a large number of times under similar conditions.
What this definition is saying is that the probability of obtaining a head when a fair coin is tossed is 0.5 because the relative frequency of heads should be approximately 0.5 when the coin is tossed a large number of times under similar conditions. To see this, allow us to run the experiment a large number of times. For instance, let us run the experiment 500 times, 1000 times, 10,000 times and then 1,000,000 times and study the behavior of the relative frequency of heads.
As we repeat the experiment a large number of times under similar conditions, it appears that the relative frequency gets closer and close to 0.5. Thus, we may be inclined to say that the probability we obtain a heads is 0.5.
However, there are problems with this informal approach! What are these problems? Let us look back at our provisional definition of probability:
The probability of an event refers to the likelihood or relative frequency for which the event occurs if the experiment were repeated a large number of times under similar conditions.
1. What do we mean by the term "event"?
2. The second problem we face is what if it is not easy to repeat this mysterious event?
3. Additionally, how large is large? In the context of the above example, someone may say that 1,000,000 tosses is sufficient. And hence the probability that a toss of a fair coin resulting in heads is given by \( \displaystyle \dfrac{500008}{1000000} \neq 0.5 \).
4. What do we mean by "similar conditions"? Let us suppose we flipped the coin once and obtained heads. If we were to replicate the coin toss under exact conditions then what would happen? For instance, let us suppose that we kept all variables the same. That is, we used the same energy on the coin flip, we used the same trajectory of the initial coin flip, the same starting position of the coin, and so forth. If we keep everything identical then every flip will land on heads which takes away from the inherent randomness of the coin!
We see that our informal definition of probability has some holes in it and this is problematic! In order to study probability, we first must agree what probability is. The formal definition of probability which we all agree to will be presented in the next section. This definition is rooted in the language of sets and thus we must discuss basic set theory.
We first start off with a definition of one of the most fundamental objects in mathematics, a set. Quite simply,
A set, typically denoted by a capital letter such as \(A\), is an unordered collection of well-defined objects. We call these objects the elements of \(A\). If an object \(x\) is an element of \(A\), then we write \(x \in A\). If \(x\) is not an element of \(A\), then we write that \(x \not\in A \).
Before we take a look at some examples, an explanation is in order about the word "well-defined" means. For our purposes, we can think of well-defined as meaning that given any object, it is clear if that object belongs to the set or not. Here are a few examples of sets:
- \( A = \{ 1, 2, 3, 4, 5, 6 \} \).
- \( E = \{ x ~|~ x ~ \text{is a student enrolled in our Math 241 course} \} \).
- \( F = \{ x \in \mathbb{Z} ~|~ x \leq 10 \} \).
- \( G = \{ (1,6), (2,5), (3,4), (4,3), (5,2), (6,1) \} \).
The following is not an example of a set:
\[ A = \{ x ~ | ~ x ~ \text{is a good drink} \} \]
Can you explain why?
Sets will appear in every problem that we will ever consider in this course and so it is important to have an excellent command on sets and the operations involved with them. In order to understand one of the most important sets that we will discuss, we first must make a definition.
An experiment is any process, real or fake, where the possible outcomes of the process can be identified prior to the completion of the process. The set of all possible outcomes from an experiment is referred to as the sample space and is typically denoted by \(S\) or by the Greek letter, capital omega, \( \Omega\).
- The act of flipping a coin can be regarded as an experiment because before we flip the coin, we know all of the possible outcomes - we either obtain a heads or a tails. In this example, we have \( S = \{ H, T \} \) where the \(H\) stands for Heads and the \(T\) stands for tails.
- Rolling a regular six-sided die is an experiment where \( S = \{ 1, 2, 3, 4, 5, 6 \} \).
- Drawing a single card from a regular deck of 52 cards is also an experiment. Why?
- Measuring the amount of time in seconds it takes for your phone's battery life is also an experiment. What do you think the sample space is for this experiment?
When it comes to probability, having a visual aide is helpful. For that reason, we typically sketch out the sample space of a problem. Often, we will sketch out the sample space by a rectangular box labeled \( S \) and we will list out the elements in \( S \). For instance, the sample space mentioned in Example 1 and 2 above can be depicted as this:

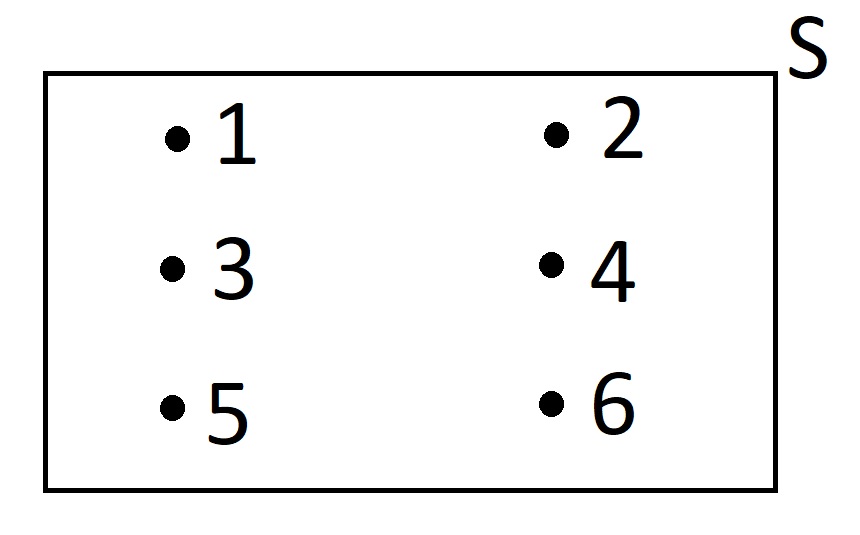
Informally speaking, we will often study a set contained within a larger set which. We call this set which is contained in the larger set a subset.
Given two sets, \(A\) and \(B \), we say \(A\) is a subset of \(B\) and write \(A \subseteq B \) provided that every element of \(A\) is an element of \(B \). That is, \[ A \subseteq B \text{ if and only if } x \in A \implies x \in B \]
If \(E = \{ 1, 2 \} \) and \(S = \{ 1, 2, 3, 4, 5, 6 \} \) then \(E \subseteq S \).
Visually, we have the following:

If \(A = \{ 1, 2 , 3, 4, 5 \} \) and \(B= \{ 2, 3, 4, 5, 6 \} \) then \(A \not\subseteq B \). Can you explain why?
In many cases, we will be studying the subset of a sample space and thus we reserve a special name for this set.
Any subset, \(E\), of a sample space \(S\), is called an event.
- If \(S = \{H, T \} \) and \(E = \{ \text{H} \} \) then \( E \) is an event since \(E \subseteq S \).
- If \(S = \{ 1, 2, 3, 4, 5, 6 \} \) and \( E = \{ \text{we get a positive even number less than or equal to 6} \} = \{ 2, 4, 6 \} \) then \( E \subseteq S \).
- Suppose an experiment is selecting a card at random from a regular deck of 52 cards. Then \( S = \{ \text{2 of Hearts}, \text{2 of Diamonds}, \text{2 of Clubs}, \text{2 of Spades}, \ldots, \text{Ace of Hearts}, \text{Ace of Diamonds}, \text{Ace of Clubs}, \text{Ace of Spades} \} \). If \( E = \{ \text{5 of Hearts}, \text{5 of Diamonds}, \text{5 of Clubs}, \text{5 of Spades} \}\) then \( E \subseteq S\).
For us, we will be using the words set and event interchangeably. More importantly, there is an algebra we can define on sets. What do we mean by this? Well, simply put, in the same way we can have rules for performing operations on numbers (like addition, subtraction, multiplication, and division) we can instead create rules for performing operations on sets (like taking their union, intersection, or complement).
For any two events, \(E\) and \(F\) of a sample space \(S\), we define \(E \cup F\), read as "\(E\) union \(F\) " to be the event which consists of all outcomes that are in either \(E\), or \(F\), or in both \(E\) and \(F\). That is,
\[ E \cup F = \{x \in S: x \in E \text{ or } x \in F\} \]
We define \(E \cap F\), read as "\(E\) intersect F\) ", to be the event which consists of all outcomes that are in both \(E\) and \(F\). That is,
\[ E \cap F = \{x \in S: x \in E \text{ and } x \in F\}\]
It should be noted that in the case that \(E\) and \(F\) share no common outcomes, we write \(E \cap F\) = \emptyset\), read as "\(E\) intersect F\) equals the empty set", where \(\emptyset\) refers to the set which contains no elements. If \(E \cap F\) = \emptyset\), then we say that \(E\) and \(F\) are disjoint or mutually exclusive events.
Find \(E \cup F \) and \( E \cap F \) for each of the following examples:
- \(E = \{ 0, 1, 2, 3, 4 \} \) and \(F = \{ 3, 4, 5, 6, 10 \} \).
- \(E = \{ 1, 2, 3 \} \) and \(F = \{ 4, 5, 6 \} \).
- Answer
-
- \( E \cup F = \{0, 1, 2, 3, 4, 5, 6, 10 \} \) and \( E \cap F = \{ 3, 4 \} \).
- \( E \cup F = \{ 1, 2, 3, 4, 5, 6 \} \) and \( E \cap F = \emptyset \).
Informally, we can think of the set theoretic operation of union as "merging" the sets into one "larger" set. Meanwhile, the set theoretic operation of intersection only takes what is common or shared from the underlying sets.
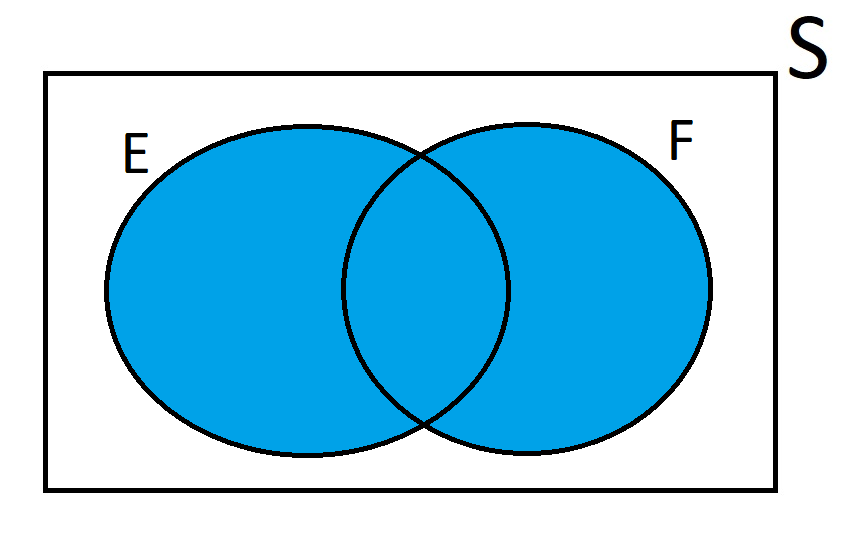
To understand these operations from a visual perspective, we can draw a Venn diagram. Here is what the Venn diagram may look like for two events:

For the above figure, can you shade the region that is referred to when we say \( E \cup F \)? Can you shade the region that is referred to when we say \( E \cap F \)?

If two events are disjoint, then the Venn diagram might look like the following:

We shall now take a small jump. You see, there is no reason to restrict ourselves to studying the union or intersection of only two events. Instead, we may discuss the union or intersection of three events or four events or five events or \( k \) events. In fact, we can also have the union or intersection of infinitely many events. In terms of a Venn Diagram, let us see what is meant by the union of three events and the intersection of three events.
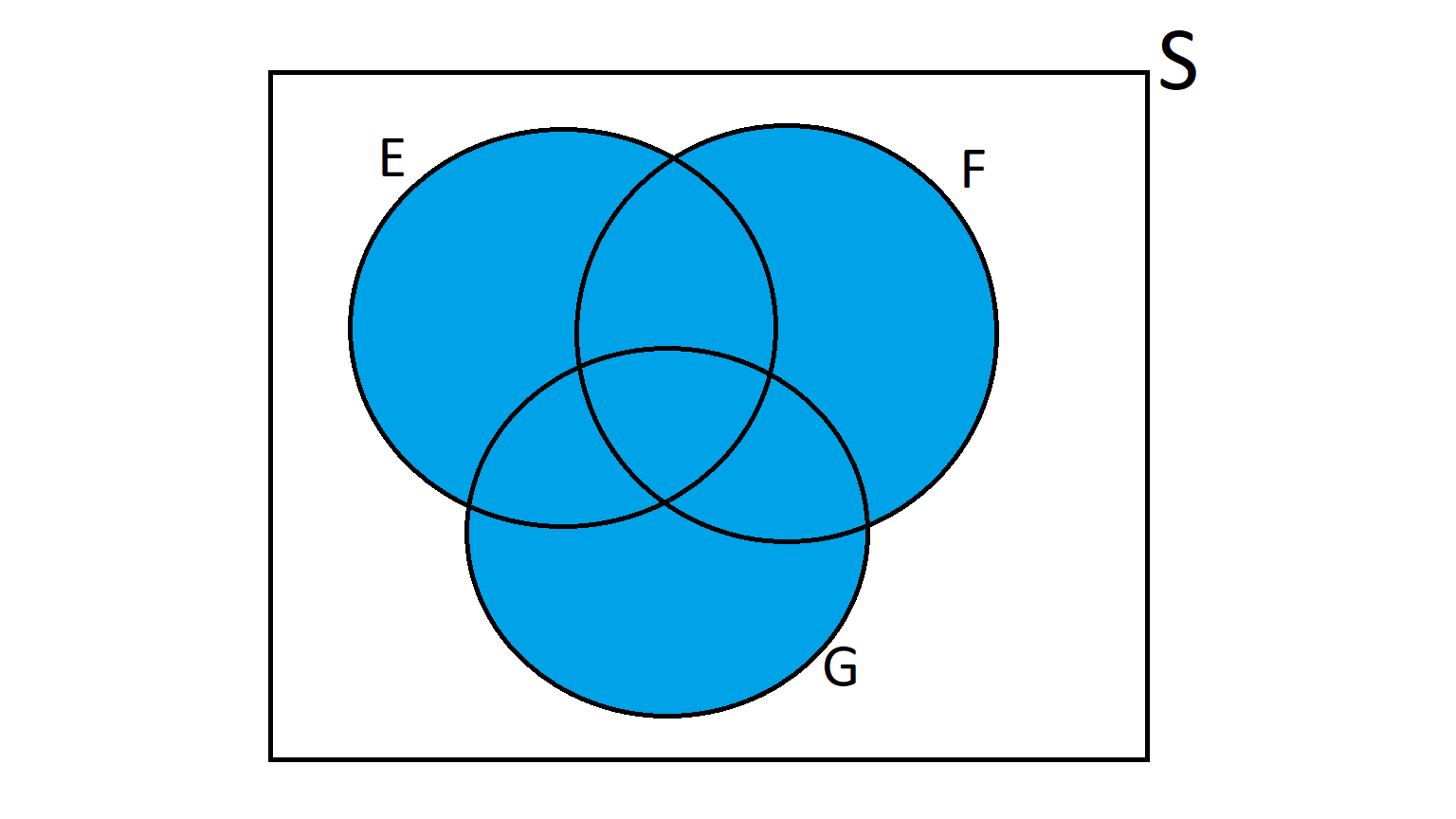
A Venn diagram for three events, \( E, F \) and \(G \) may look like the following:

- Shade in \( E \cup F \cup G \).
- Shade in \( E \cap F \cap G \).
- Answer
-

Unfortunately, we cannot draw a picture to illustrate what it means to take the union of an infinite number of sets nor can we draw the picture for what it means to take the intersection of an infinite number of sets. Why is that? Well clearly, we cannot draw an infinite number of sets! And since we do not have a concise way of doing so, we can only present it's definition.
If \( E_1, E_2, E_3, \ldots \) are events in a sample space \( S \), then the union of these events, denoted by
\[
\bigcup_{i=1}^{\infty} E_i = E_1 \cup E_2 \cup E_3 \cup \ldots
\]
is defined to be the event that consist of all outcomes that are in \(E_n \) for at least one value of \( n = 1, 2, 3, \ldots \). That is,
\[
\bigcup_{i=1}^{\infty} E_i = \{ x \in S ~|~ x \in E_{i} ~ \text{for some} ~ i \in \mathbb{N} \}
\]
If \( E_1, E_2, E_3, \ldots \) are events in a sample space \( S \), then the intersection of these events, denoted by
\[
\bigcap_{i=1}^{\infty} E_i = E_1 \cap E_2 \cap E_3 \cap \ldots
\]
is defined to be the event that consist of all outcomes that are common to all of the events \( E_n \) for \( n = 1, 2, 3, \ldots \).
That is,
\[
\bigcap_{i=1}^{\infty} E_i = \{ x \in S ~|~ x \in E_{i} ~ \text{for all} ~ i \in \mathbb{N} \}
\]
Finally, there is one last set theoretic operation we must discuss - how to take the complement of an event.
Given any event \(A\) of a sample space \(S\), we define the complement of \(A \), denoted by \( A^c \) or \( A' \), to be the event containing all of the elements in \(S\) that are not in \(A\). That is, \[ A^c = \{ x \in S: x \notin A\} \]
Find \(E^c \) for each of the following examples:
- \( S = \{0, 1, 2, 3, 4, 5, 6, 10 \} \) and \( E = \{ 0, 1, 2, 3 \} \)
- \( S = \{ 1, 2, 3, 4, 5, 6 \} \) and if \( E = \{ 2, 4, 6 \} \)
- \( S = \{ 1, 2, 3 \} \) and \( E = \{ 1, 2, 3 \} \)
- Answer
-
- \( E^c = \{ 4, 5, 6, 10 \} \)
- \( E^c = \{1, 3, 5 \} \)
- \( E^c = \emptyset \)
Shade in \(E^c \) on the following Venn Diagram.

- Answer
-


We now discuss three definitions which will play a critical part in developing our theory of probability. The first definition generalizes what it means for more than two sets to be mutually exclusive. The remaining two definitions will play a central role in Week 5 when we discuss conditional probabilities.
- The events \(E_1, E_2, \ldots, E_k\) are said to be mutually exclusive events if \( E_i \cap E_j = \emptyset \) for all \(i \neq j \).
- The events \(E_1, E_2, \ldots, E_k\) are said to be exhaustive on \(S\) if \(E_1 \cup E_2 \cup \ldots \cup E_k = S\).
- The events \(E_1, E_2, \ldots, E_k\) are said to form a partition on \(S\)} if \(E_1, E_2, \ldots, E_k\) are mutually exclusive events and exhaustive events.
- If \( S = \{ 1, 2, 3, 4, 5, 6 \} \) and \(E_1 = \{ 1, 2, 3 \} \) and \(E_2 = \{ 4, 5, 6 \} \) then \(E_1 \) and \(E_2 \) are disjoint or mutually exclusive.
- If \( S = \{ 1, 2, 3, 4, 5, 6 \} \) and \(E_1 = \{ 1, 2, 3 \} \) and \(E_2 = \{ 4, 5, 6 \} \) then \(E_1 \) and \(E_2 \) are exhaustive events.
- If \( S = \{ 1, 2, 3, 4, 5, 6 \} \) and \(E_1 = \{ 1, 2, 3 \}\) and \(E_2 = \{ 4, 5, 6 \}\) then \(E_1\) and $\(E_2\) form a partition on \(S \).
- If \( S = \{ 1, 2, 3, 4, 5, 6 \} \) and \(E_1 = \{ 1, 2 \}\) and \(E_2 = \{ 3, 4 \}\) and \(E_3 = \{ 5, 6 \}\) then \(E_1\), \(E_2\), \(E_3\) forms a partition on \(S\).
- If \( E_1 = \{ 1, 2, 3 \} \) and \(E_2 = \{ 4, 5, 6 \}\) and \(E_3 = \{ 7, 8, 9 \}\) then \(E_1\), \(E_2\) and \(E_3\) are said to be disjoint or mutually exclusive.
- If \( E_1 = \{ 1, 2, 3 \} \) and \(E_2 = \{ 4, 5, 6 \}\) and \(E_3 = \{ 6, 7, 8, 9 \}\) then \(E_1\), \(E_2\) and \(E_3\) are NOT disjoint.
- If \( S = \{ 1, 2, 3, 4, 5, 6 \} \) and \(E_1 = \{ 1, 2, 3, 4 \}\) and \(E_2 = \{ 4, 5, 6 \}\) then \(E_1\) and \(E_2\) are still exhaustive events.
\(\emptyset \subseteq A\) for every set \(A\).
Proof
- Answer
-
\( \emptyset \subseteq A \) means that \( x \in \emptyset \implies x \in A \). Since the premise is false, the implication is true.
Suppose that \(A\), \(B\) and \(C\) are subsets of a set \(S\). Then
- \(A \subseteq A\) (the reflexive property).
- If \(A \subseteq B\) and \(B \subseteq A\) then \(A = B \) (the anti-symmetric property).
- If \(A \subseteq B\) and \(B \subseteq C\) then \(A \subseteq C\) (the transitive property).
If \( E \subseteq F \) then \( F = E \cup (E^c \cap F) \)
- \(A \cup \emptyset = A\)
- \(A \cap S = A\)
- \(A \cup A = A\)
- \(A \cap A = A\)
- \(A \cup \emptyset = A\)
- \(A \cap \emptyset = \emptyset \)
- \(A \cup A^c = S\)
- \(A \cap A^c = \emptyset\)
\((A^c)^c = A\)
- \(A \cup B = B \cup A\)
- \(A \cap B = B \cap A\)
- \(A \cup (B \cup C) = (A \cup B) \cup C\)
- \(A \cap (B \cap C) = (A \cap B) \cap C\)
- \(A \cap (B \cup C) = (A \cap B) \cup (A \cap C)\)
- \(A \cup (B \cap C) = (A \cup B) \cap (A \cup C)\)
- \((A \cup B)^c = A^c \cap B^c\)
- \((A \cap B)^c = A^c \cup B^c\).
- \[ \left(\bigcup_{i =1}^{\infty} A_i \right)^c = \bigcap_{i=1}^{\infty} A_i^c \]
- \[ \left( \bigcap_{i =1}^{\infty} A_i \right)^c = \bigcup_{i=1}^{\infty} A_i^c \]