
16.2: Simulating Dynamics on Networks




- Last updated
- Apr 30, 2024
- Save as PDF

( \newcommand{\kernel}{\mathrm{null}\,}\)
Because NetworkX adopts plain dictionaries as their main data structure, we can easily add states to nodes (and edges) and dynamically update those states iteratively. This is a simulation of dynamics on networks. This class of dynamical network models describes dynamic state changes taking place on a static network topology. Many real-world dynamical networks fall into this category, including:
- Regulatory relationships among genes and proteins within a cell, where nodes are genes and/or proteins and the node states are their expression levels.
- Ecological interactions among species in an ecosystem, where nodes are species and the node states are their populations.
- Disease infection on social networks, where nodes are individuals and the node states are their epidemiological states (e.g., susceptible, infected, recovered, immunized, etc.).
- Information/culture propagation on organizational/social networks, where nodes are individuals or communities and the node states are their informational/cultural states.
The implementation of simulation models for dynamics on networks is strikingly similar to that of CA. You may find it even easier on networks, because of the straightforward definition of “neighbors” on networks. Here, we will work on a simple local majority rule on a social network, with the following assumptions:
- Nodes represent individuals, and edges represent their symmetric connections for information sharing
- Each individual takes either 0 or 1 as his or her state.
- Each individual changes his or her state to a majority choice within his or her local neighborhood (i.e., the individual him- or herself and the neighbors connected to him or her). This neighborhood is also called the ego network of the focal individual in social sciences.
- State updating takes place simultaneously on all individuals in the network.
- Individuals’ states are initially random.
Let’s continue to use pycxsimulator.py and implement the simulator code by defining three essential components—initialization, observation, and updating.
The initialization part is to create a model of social network and then assign random states to all the nodes. Here I propose to perform the simulation on our favorite Karate Club graph. Just like the CA simulation, we need to prepare two network objects, one for the current time step and the other for the next time step, to avoid conflicts during the state updating process. Here is an example of the initialization part:

Here, we pre-calculate node positions using spring_layout and store the results under g as an attribute g.pos. Python is so flexible that you can dynamically add any attribute to an object without declaring it beforehand; we will utilize this trick later in the agent-based modeling as well. g.pos will be used in the visualization so that nodes won’t jump around every time you draw the network.
The g.nodes_iter() command used in the for loop above works essentially the same way as g.nodes() in this context, but it is much more memory efficient because it doesn’t generate an actual fully spelled-out list, but instead it generates a much more compact representation called an iterator, an object that can return next values iteratively. There is also g.edges_iter() for similar purposes for edges. It is generally a good idea to use nodes_iter() and edges_iter() in loops, especially if your network is large. Finally, in the last line, the copy command is used to create a duplicate copy of the network.
The observation part is about drawing the network. We have already done this many times, but there is a new challenge here: We need to visualize the node states in addition to the network topology. We can use the node_color option for this purpose:


The vmin/vmax options are to use a fixed range of state values; otherwise matplotlib would automatically adjust the color mappings, which sometimes causes misleading visualization. Also note that we are using g.pos to keep the nodes in pre-calculated positions.
The updating part is pretty similar to what we did for CA. You just need to sweep all the nodes, and for each node, you sweep its neighbors, counting how many 1’s you have in the local neighborhood. Here is a sample code:
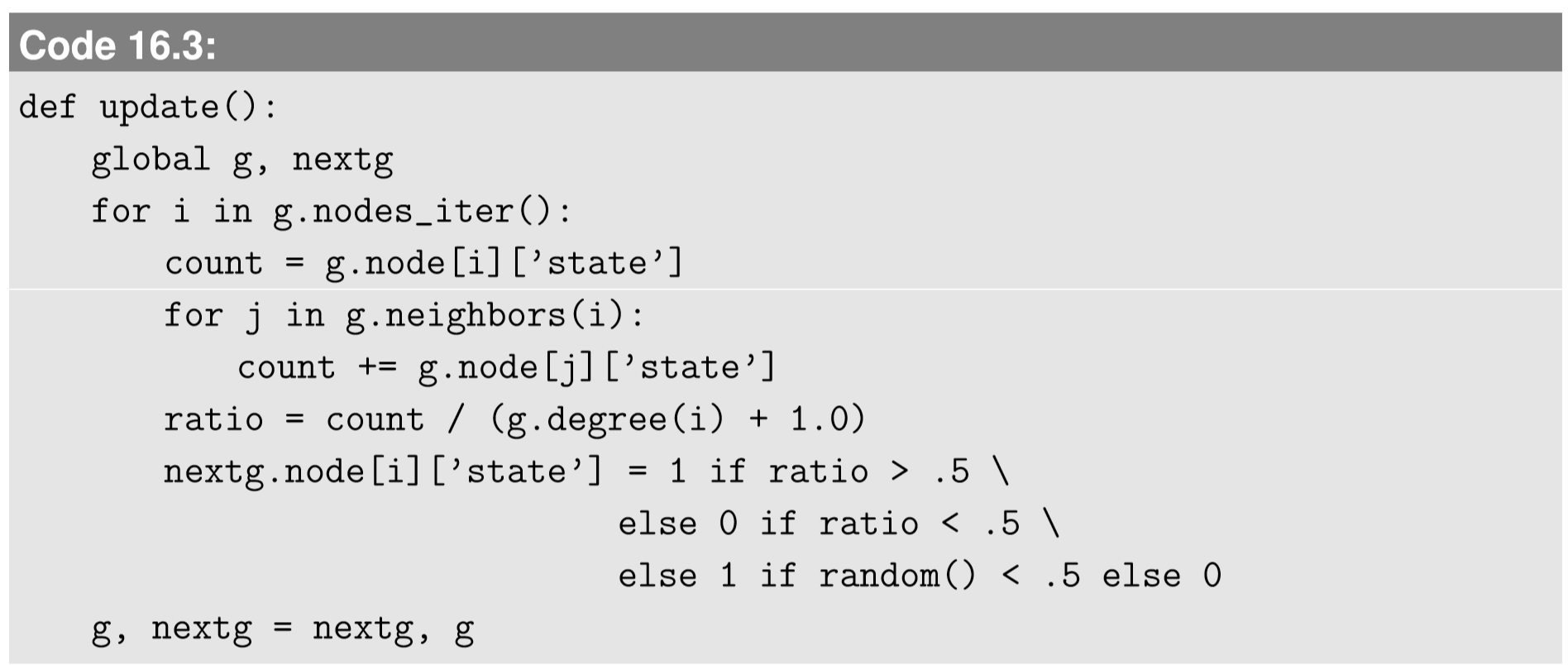
I believe this part deserves some in-depth explanation. The first for loop for i is to sweep the space, i.e., the whole network. For each node, i, the variable count is first initialized with node i’s own state. This is because, unlike in the previous CA implementations, the node i itself is not included in its neighbors, so we have to manually count it first. The second for loop for j is to sweep node i’s neighbors. NetworkX’s g.neighbors(i) function gives a list of i’s neighbors, which is a lot simpler than the neighborhood sweep in CA; we don’t have to write nested for loops for dx and dy, and we don’t have to worry about boundary conditions at all. Neighbors are neighbors, period.
Once the local neighborhood sweep is done, the state ratio is calculated by dividing count by the number of nodes counted (= the degree of node i plus 1 for itself). If the state ratio is above 0.5, the local majority is 1, so the next state of node i will be 1. If it is below 0.5, the local majority is 0, so the next state will be 0. Moreover, since this dynamic is taking place on a network, there is a chance for a tie (which never occurs on CA with von Neumann or Moore neighborhoods). In the example above, I just included a tie-breaker coin toss, to be fair. And the last swap of g and nextg is something we are already familiar with.
The entire simulation code looks like this:



Callstack:
at (Bookshelves/Scientific_Computing_Simulations_and_Modeling/Introduction_to_the_Modeling_and_Analysis_of_Complex_Systems_(Sayama)/16:_Dynamical_Networks_I__Modeling/16.02:_Simulating_Dynamics_on_Networks), /content/body/pre, line 1, column 12
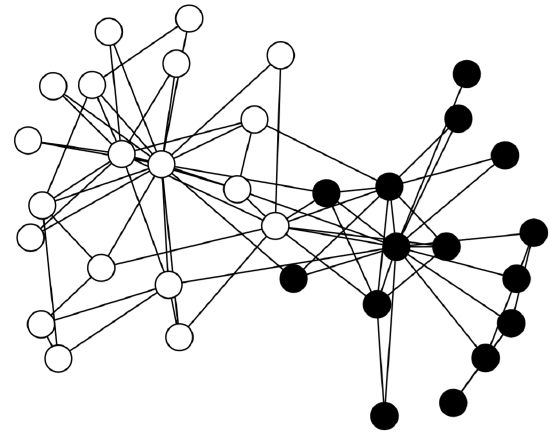
Run this code and enjoy your first dynamical network simulation. You will notice that the network sometimes converges to a homogeneous state, while at other times it remains in a divided condition (Fig. 16.2.1). Can you identify the areas where the boundaries between the different states tend to form?
{kind=link}
Revise the majority rule dynamical network model developed above so that each node stochastically flips its state with some probability. Then simulate the model and see how its behavior is affected.
In what follows, we will see some more examples of two categories of dynamics on networks models: discrete state/time models and continuous state/time models. We will discuss two exemplar models in each category.
Discrete state/time models (1): Voter model
The first example is a revision of the majority rule dynamical network model developed above. A very similar model of abstract opinion dynamics has been studied in statistical physics, which is called the voter model. Just like in the previous model, each node (“voter”) takes one of the finite discrete states (say, black and white, or red andblue—you could view it as a political opinion), but the updating rule is different. Instead of having all the nodes update their states simultaneously based on local majority choices, the voter model considers only one opinion transfer event at a time between a pair of connected nodes that are randomly chosen from the network (Fig. 16.2.2). In this sense, it is an asynchronous dynamical network model.
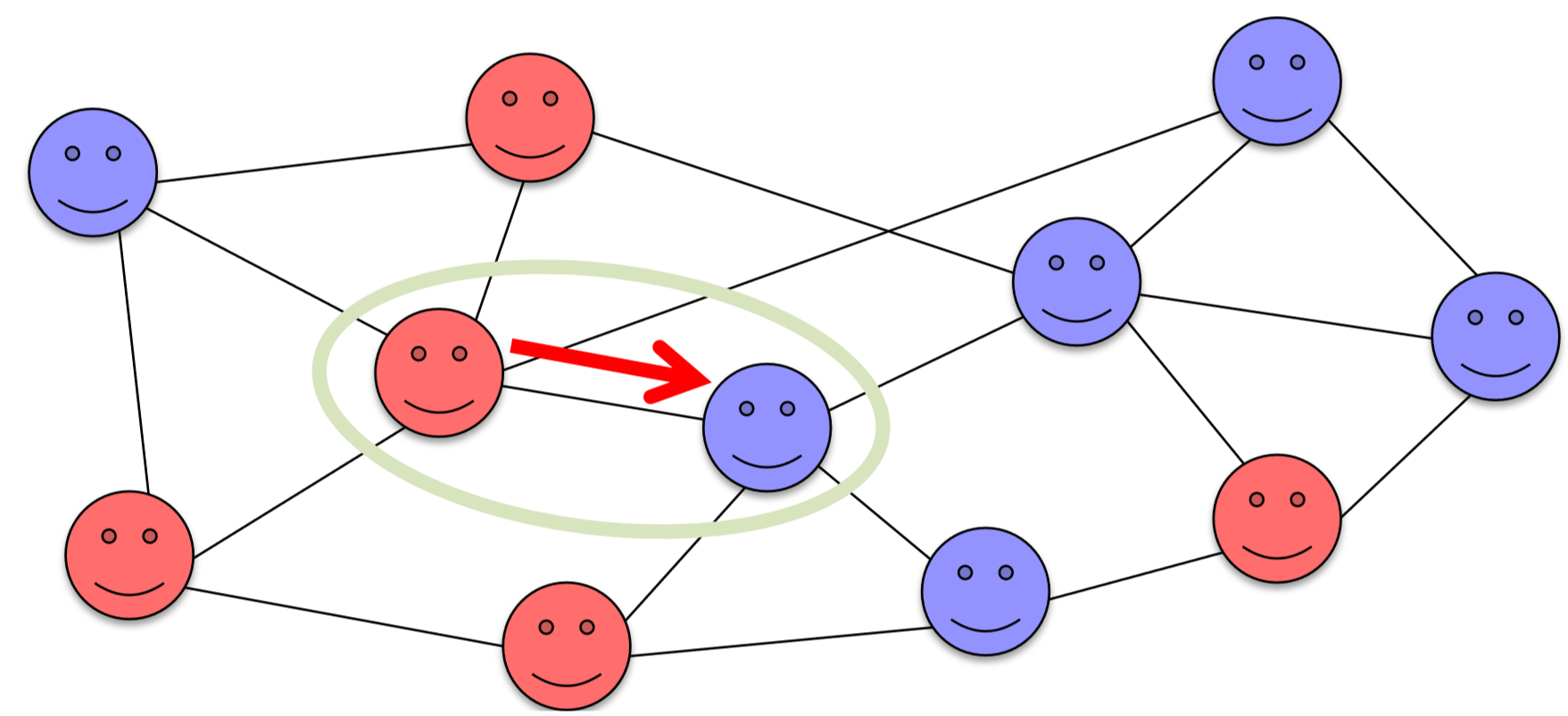
There are three minor variations of how those nodes are chosen:
- Original (“pull”) version: First, a “listener” node is randomly chosen from the network, and then a “speaker” node is randomly chosen from the listener’s neighbors.
- Reversed (“push”) version: First, a “speaker” node is randomly chosen from the network, and then a “listener” node is randomly chosen from the speaker’s neighbors.
- Edge-based (symmetric) version: First, an edge is randomly chosen from the network, and then the two endpoints (nodes) of the edge are randomly assigned to be a “speaker” and a “listener.”
In either case, the “listener” node copies the state of the “speaker” node. This is repeated a number of times until the entire network reaches a consensus with a homogenized state.
If you think through these model assumptions carefully, you may notice that the first two assumptions are not symmetric regarding the probability for a node to be chosen as a “speaker” or a “listener.” The probability actually depends on how popular a node is. Specifically, the original version tends to choose higher-degree nodes as a speaker more often, while the reversed version tends to choose higher-degree nodes as a listener more often. This is because of the famous friendship paradox, a counter-intuitive fact first reported by sociologist Scott Feld in the 1990s [68], which is that a randomly selected neighbor of a randomly selected node tends to have a larger-than-average degree. Therefore, it is expected that the original version of the voter model would promote homogenization of opinions as it gives more speaking time to the popular nodes, while the reversed version would give an equal chance of speech to everyone so the opinion homogenization would be much slower, and the edge-based version would be somewhere in between. We can check these predictions by computer simulations.
The good news is that the simulation code of the voter model is much simpler than that of the majority rule network model, because of the asynchrony of state updating. We no longer need to use two separate data structures; we can keep modifying just one Graph object directly. Here is a sample code for the original “pull” version of the voter model, again on the Karate Club graph:



See how simple the update function is! This simulation takes a lot more steps for the system to reach a homogeneous state, because each step involves only two nodes. It is probably a good idea to set the step size to 50 under the “Settings” tab to speed up the simulations.
Revise the code above so that you can measure how many steps it will take until the system reaches a consensus (i.e., homogenized state). Then run multiple simulations (Monte Carlo simulations) to calculate the average time length needed for consensus formation in the original voter model.
Revise the code further to implement (1) the reversed and (2) the edge-based voter models. Then conduct Monte Carlo simulations to measure the average time length needed for consensus formation in each case. Compare the results among the three versions.
Discrete state/time models (2): Epidemic model
The second example of discrete state/time dynamical network models is the epidemic model on a network. Here we consider the Susceptible-Infected-Susceptible (SIS) model, which is even simpler than the SIR model we discussed in Exercise 7.3. In the SIS model, there are only two states: Susceptible and Infected. A susceptible node can get infected from an infected neighbor node with infection probability pi (per infected neighbor), while an infected node can recover back to a susceptible node (i.e., no immunity acquired) with recovery probability pr (Fig. 16.2.3). This setting still puts everything in binary states like in the earlier examples, so we can recycle their codes developed above.
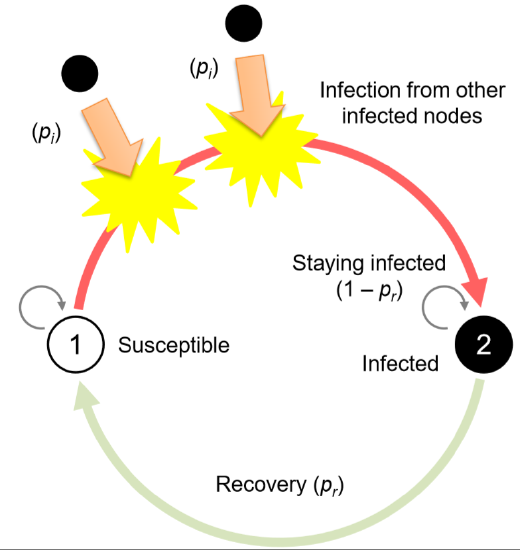
Regarding the updating scheme, I think you probably liked the simplicity of the asynchronous updating we used for the voter odel, so let’s adopt it for this SIS model too. We will first choose a node randomly, and if it is susceptible, then we will randomly choose one of its neighbors; this is similar to the original “pull” version of the voter model. All you need is to revise just the updating function as follows:


Again, you should set the step size to 50 to speed up the simulations. With these parameter settings (pi=pr=0.5), you will probably find that the disease (state 1 = black nodes) quickly dies off and disappears from the network, even though half of the initial population is infected at the beginning. This means that for these particular parameter values and network topology, the system can successfully suppress a pandemic without taking any special action.
Conduct simulations of the SIS model with either pi or pr varied systematically, while the other one is fixed at 0.5. Determine the condition in which a pandemic occurs (i.e., the disease persists for an indefinitely long period of time). Is the transition gradual or sharp? Once you get the results, try varying the other parameter as well.
Generate a much larger random network of your choice and conduct the same SIS model simulation on it. See how the dynamics are affected by the change of network size and/or topology. Will the disease continue to persist on the network?
Continuous state/time models (1): Diffusion model
So far, we haven’t seen any equations in this chapter, because all the models discussed above were described in algorithmic rules with stochastic factors involved. But if they are deterministic, dynamical network models are not fundamentally different from other conventional dynamical systems. In fact, any deterministic dynamical model of a network made of n nodes can be described in one of the following standard formulations using an n-dimensional vector state x,
xt=F(xt−1,t)(for discrete-time models)
or
dxdt=F(x,t)(for continuous-time models)
If function F correctly represents the interrelationships between the different components of x. For example, the local majority rule network model we discussed earlier in this chapter is fully deterministic, so its behavior can be captured entirely in a set of difference equations in the form of Equation ???. In this and next subsections, we will discuss two illustrative examples of the differential equation version of dynamics on networks models, i.e., the diffusion model and the coupled oscillator model. They are both extensively studied in network science.
Diffusion on a network can be a generalization of spatial diffusion models into non-regular, non-homogeneous spatial topologies. Each node represents a local site where some “stuff” can be accumulated, and each symmetric edge represents a channel through which the stuff can be transported, one way or the other, driven by the gradient of its concentration. This can be a useful model of the migration of species between geographically semi-isolated habitats, flow of currency between cities across a nation, dissemination of organizational culture within a firm, and so on. The basic assumption is that the flow of the stuff is determined by the difference in its concentration across the edge:
dcidt=α∑jϵNi(ci−ci)
Here ci is the concentration of the stuff on node i, α is the diffusion constant, and Ni is the set of node i’s neighbors. Inside the parentheses (cj−ci) represents the difference in the concentration between node j and node i across the edge (i,j). If neighbor j has more stuff than node i, there is an influx from j to i, causing a positive effect on dci/dt. Or if neighbor j has less than node i, there is an outflux from i to j, causing a negative effect on dci/dt. This makes sense.
Note that the equation above is a linear dynamical system. So, if we represent the entire list of node states by a state vectorc=(c1c2...cn)T, Equation ??? can be written as
dcdt=−αLc,
where L is what is called a Laplacian matrix of the network, which is defined as
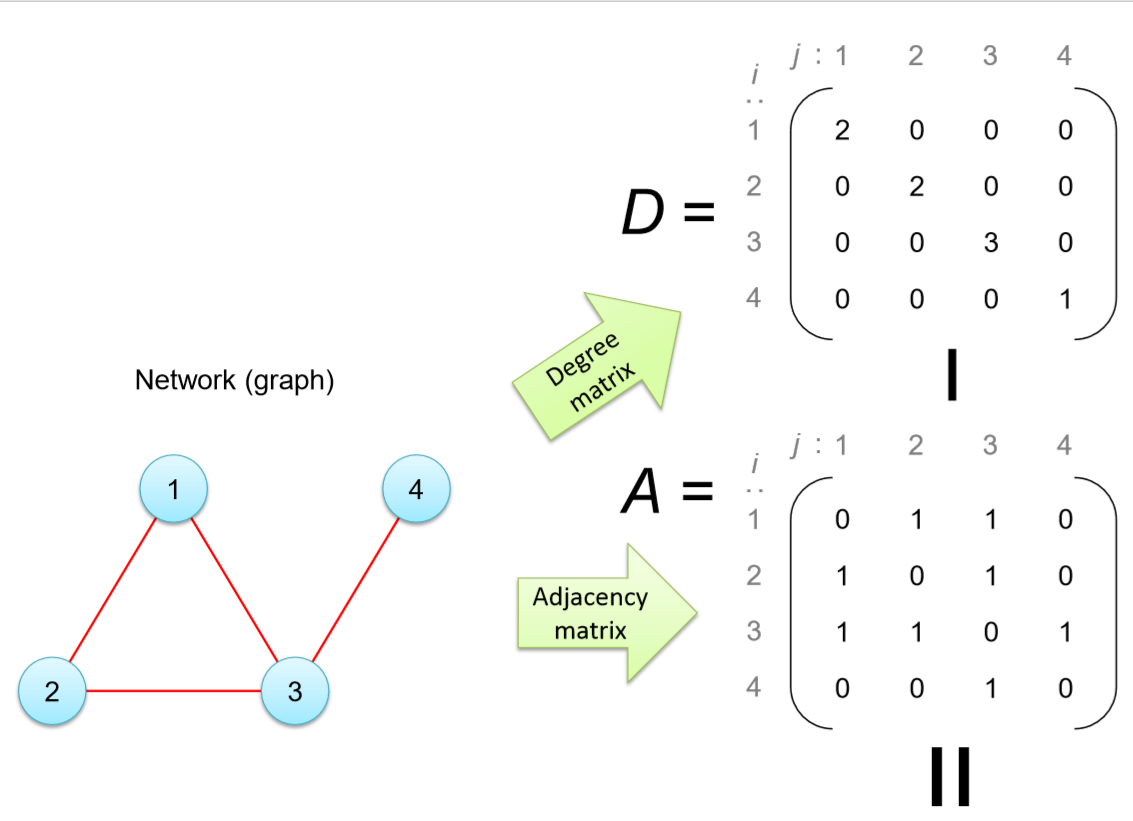
L=D−A,
where A is the adjacency matrix of the network, and D is the degree matrix of the network, i.e., a matrix whose i-th diagonal component is the degree of node i while all other components are 0. An example of those matrices is shown in Fig. 16.2.4.
Wait a minute. We already heard “Laplacian” many times when we discussed PDEs. The Laplacian operator (∇2) appeared in spatial diffusion equations, while this new Laplacian matrix thing also appears in a network-based diffusion equation. Are they related? The answer is yes. In fact, they are (almost) identical linear operators in terms of their role. Remember that when we discretized Laplacian operators in PDEs to simulate using CA (Eq. 13.5.21), we learned that a discrete version of a Laplacian can be calculated by the following principle:
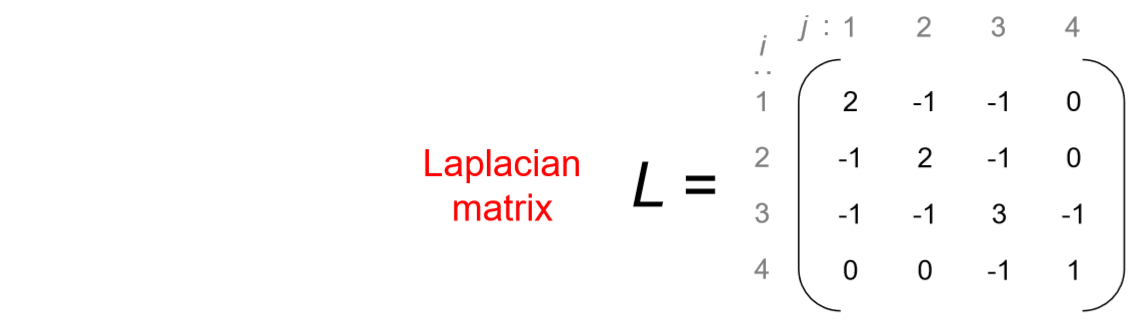
“Measure the difference between your neighbor and yourself, and then sum up all those differences.”
Note that this is exactly what we did on a network in Equation ???! So, essentially, the Laplacian matrix of a graph is a discrete equivalent of the Laplacian operator for continuous space. The only difference, which is quite unfortunate in my opinion, is that they are defined with opposite signs for historical reasons; compare the first term of Eq. 13.4.4 and Eq.???, and you will see that the Laplacian matrix did not absorb the minus sign inside it. So, conceptually,
∇2⇔−L.
I have always thought that this mismatch of signs was so confusing, but both of these “Laplacians” are already fully established in their respective fields. So, we just have to live with these inconsistent definitions of “Laplacians.”
Now that we have the mathematical equations for diffusion on a network, we can discretize time to simulate their dynamics in Python. Equation ??? becomes
ci(t+Δt)=cit+[α∑jϵNi(cj(t)−ci(t))]Δt=ci(t)+α[(∑jϵNicj(t))−ci(t)deg(i)]Δt.
Or, equivalently, we can also discretize time in Equation ???, i.e.,
c(t+Δt)=c(t)−αLC(t)Δt=(I−αLΔt)c(t),
where c is now the state vector for the entire network, and I is the identity matrix. Eqs.16.2.8 and 16.2.11 represent exactly the same diffusion dynamics, but we will use Equation 16.2.8 for the simulation in the following, because it won’t require matrix representation (which could be inefficient in terms of memory use if the network is large and sparse).
We can reuse Code 16.4 for this simulation. We just need to replace the update function with the following:


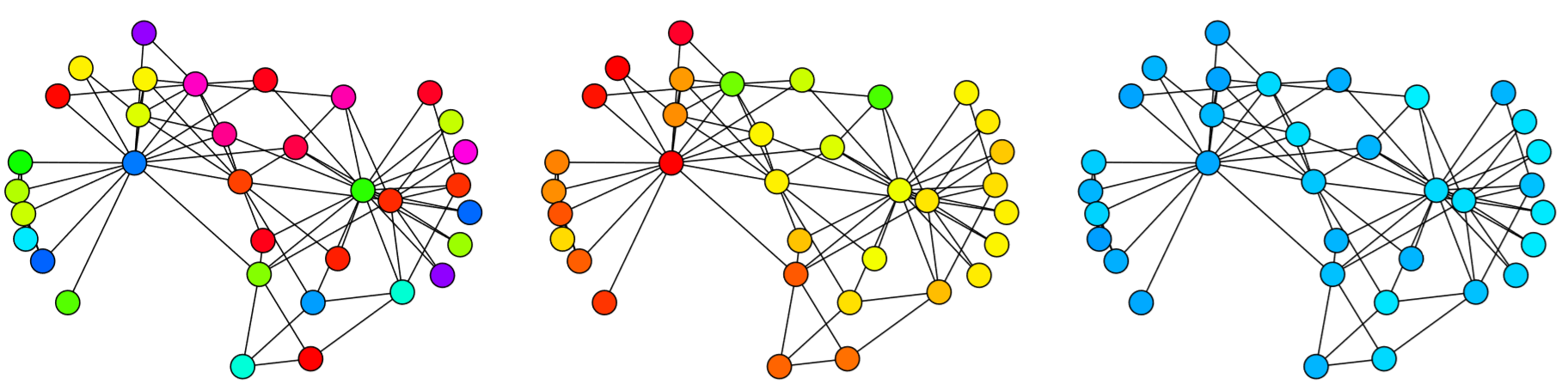
And then we can simulate a nice smooth diffusion process on a network, as shown in Fig. 16.2.5, where continuous node states are represented by shades of gray. You can see that the diffusion makes the entire network converge to a homogeneous configuration with the average node state (around 0.5, or half gray) everywhere.
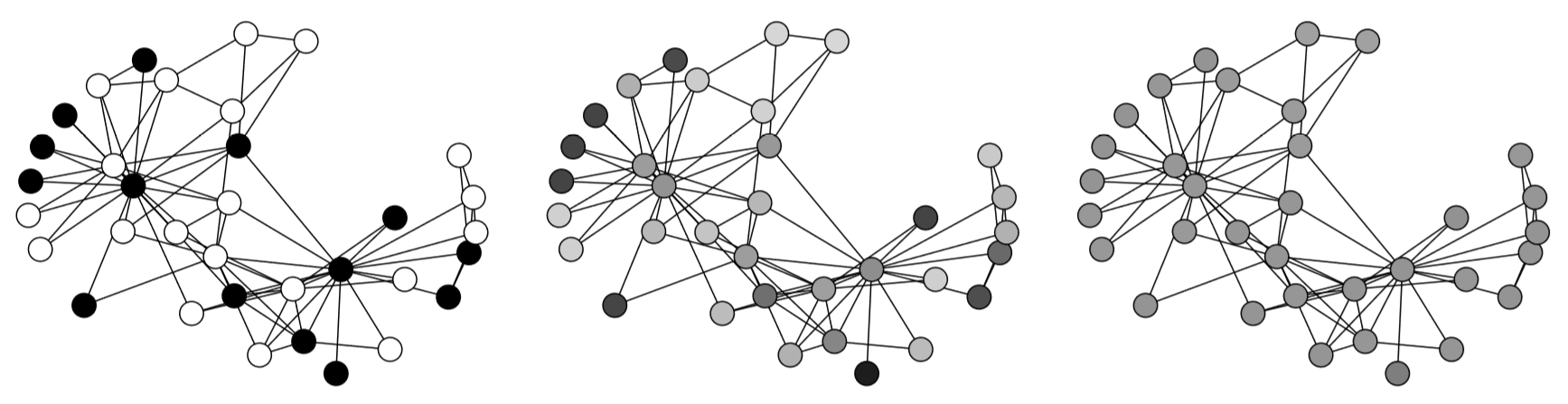
Figure 16.2.5: Visual output of Code 16.7. Time flows from left to right.
{kind=link}
This diffusion model conserves the sum of the node states. Confirm this by revising the code to measure the sum of the node states during the simulation.
Simulate a diffusion process on each of the following network topologies, and then discuss how the network topology affects the diffusion on it. For example, does it make diffusion faster or slower?
- random graph
- barbell graph
- ring-shaped graph (i.e., degree-2 regular graph)
Continuous state/time models (2): Coupled oscillator model
Now that we have a diffusion model on a network, we can naturally extend it to reaction-diffusion dynamics as well, just like we did with PDEs. Its mathematical formulation is quite straightforward; you just need to add a local reaction term to Equation ???, to obtain
dcidt=Ri(ci)+α∑jϵNi(cj−ci)
You can throw in any local dynamics to the reaction term Ri. If each node takes vector-valued states (like PDE-based reaction-diffusion systems), then you may also have different diffusion constants (α1, α2, ...) that correspond to multiple dimensions of the state space. Some researchers even consider different network topologies for different dimensions of the state space. Such networks made of superposed network topologies are called multiplex networks, which is a very hot topic actively studied right now (as of 2015), but we don’t cover it in this textbook.
For simplicity, here we limit our consideration to scalar-valued node states only. Even with scalar-valued states, there are some very interesting dynamical network models. A classic example is coupled oscillators. Assume you have a bunch of oscillators, each of which tends to oscillate at its own inherent frequency in isolation. This inherent frequency is slightly different from oscillator to oscillator. But when connected together in a certain network topology, the oscillators begin to influence each other’s oscillation phases. A key question that can be answered using this model is: When and how do these oscillators synchronize? This problem about synchronization of the collective is an interesting problem that arises in many areas of complex systems [69]: firing patterns of spatially distributed fireflies, excitation patterns of neurons, and behavior of traders in financial markets. In each of those systems, individual behaviors naturally have some inherent variations. Yet if the connections among them are strong enough and meet certain conditions, those individuals begin to orchestrate their behaviors and may show a globally synchronized behavior (Fig.16.6), which may be good or bad, depending on the context. This problem can be studied using network models. In fact, addressing this problem was part of the original motivation for Duncan Watts’ and Steven Strogatz’s “small-world” paper published in the late 1990s [56], one of the landmark papers that helped create the field of network science.
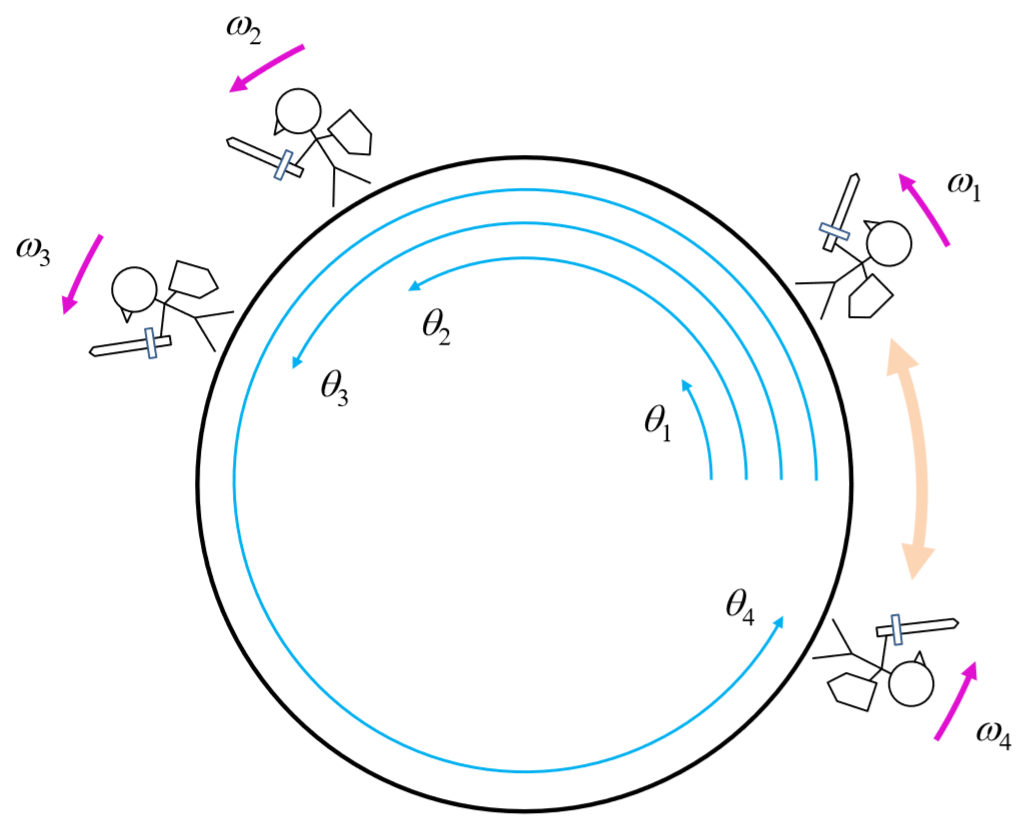
Representing oscillatory behavior naturally requires two or more dynamical variables, as we learned earlier. But purely harmonic oscillation can be reduced to a simple linear motion with constant velocity, if the behavior is interpreted as a projection of uniform circular motion and if the state is described in terms of angle θ. This turns the reaction term in Equation ??? into just a constant angular velocity ωi. In the meantime, this representation also affects the diffusion term, because the difference between two θ’s is no longer computable by simple arithmetic subtraction like θj−θi, because there are infinitely many θ’s that are equivalent (e.g., 0, 2π,−2π, 4π,−4π, etc.). So, the difference between the two states in the diffusion term has to be modified to focus only on the actual “phase difference” between the two nodes. You can imagine marching soldiers on a circular track as a visual example of this model (Fig. 16.2.7). Two soldiers who are far apart in θ may actually be close to each other in physical space (i.e., oscillation phase). The model should be set up in such a way that they try to come closer to each other in the physical space, not in the angular space.
To represent this type of phase-based interaction among coupled oscillators, a Japanese physicist Yoshiki Kuramoto proposed the following very simple, elegant mathematical model in the 1970s [70]:
dθidt=wi+α∑jϵNisin(θj−θi)|Ni|
The angular difference part was replaced by a sine function of angular difference, which becomes positive if j is physically ahead of i, or negative if j is physically behind i on the circular track (because adding or subtracting 2π inside sin won’t affect the result). These forces that soldier i receives from his or her neighbors will be averaged and used to determine the adjustment of his or her movement. The parameter α determines the strength of the couplings among the soldiers. Note that the original Kuramoto model used a fully connected network topology, but here we are considering the same dynamics on a network of a nontrivial topology.
Let’s do some simulations to see if our networked soldiers can self-organize to march in sync. We can take the previous code for network diffusion (Code 16.7) and revise it for this Kuramoto model. There are several changes we need to implement. First, each node needs not only its dynamic state (θi) but also its static preferred velocity (ωi), the latter of which should be initialized so that there are some variations among the nodes. Second, the visualization function should convert the states into some bounded values, since angular position θi continuously increases toward infinity. We can use sin(θi) for this visualization purpose. Third, the updating rule needs to be revised, of course, to implement Equation ???.
Here is an example of the revised code, where I also changed the color map to cm.hsv so that the state can be visualized in a more cyclic manner:




Figure 16.2.8 shows a typical simulation run. The dynamics of this simulation can be better visualized if you increase the step size to 50. Run it yourself, and see how the inherently diverse nodes get self-organized to start asynchronized marching. Do you see any spatial patterns there?
{kind=link}
It isknown that thelevel of synchronization in the Kuramoto model (and many other coupled oscillator models) can be characterized by the following measurement (called phase coherence):
r=|1n∑ieiθi|
Here n is the number of nodes, θi is the state of node i, and i is the imaginary unit (to avoid confusion with node index i). This measurement becomes 1 if all the nodes are in perfect synchronization, or 0 if their phases are completely random and uniformly distributed in the angular space. Revise the simulation code so that you can measure and monitor how this phase coherence changes during the simulation.
Simulate the Kuramoto model on each of the following network topologies:
- random graph
- barbell graph
- ring-shaped graph (i.e., degree-2 regular graph)
Discuss how the network topology affects the synchronization. Will it make synchronization easier or more difficult?
Conduct simulations of the Kuramoto model by systematically increasing the amount of variations of ωi (currently set to 0.05 in the initialize function) and see when/how the transition of the system behavior occurs.
Here are some more exercises of dynamics on networks models. Have fun!
John Hopfield proposed a discrete state/time dynamical network model that can recover memorized arrangements of states from incomplete initial conditions [20, 21]. This was one of the pioneering works of artificial neural network research, and its basic principles are still actively used today in various computational intelligence applications. Here are the typical assumptions made in the Hopfield network model:
- The nodes represent artificial neurons, which take either -1 or 1 as dynamic states.
- Their network is fully connected (i.e., a complete graph).
- The edges are weighted and symmetric.
- The node states will update synchronously in discrete time steps according to the following rule:
st(t+1)=sign(∑wijsj(t))
Here, si(t) is the state of node i at time t, wij is the edge weight between nodes i and j ( wij=wji because of symmetry), and sign(x) is a function that gives 1 if x>0, -1 if x<0, or 0 if x=0.
- There are no self-loops (wii = 0 for all i).
What Hopfield showed is that one can “imprint” a finite number of pre-determined patterns into this network by carefully designing the edge weights using the following simple encoding formula:
wij=∑si,ksj,kk
Here si,k is the state of node i in the k-th pattern to be imprinted in the network. Implement a simulator of the Hopfield network model, and construct the edge weights wij from a few state patterns of your choice. Then simulate the dynamics of the network from a random initial condition and see how the network behaves. Once your model successfully demonstrates the recovery of imprinted patterns, try increasing the number of patterns to be imprinted, and see when/how the network loses the capability to memorize all of those patterns.
This model is a continuous-state, discretetime dynamical network model that represents how a functional failure of a component in an infrastructure network can trigger subsequent failures and cause a large-scale systemic failure of the whole network. It is often used as a stylized model of massive power blackouts, financial catastrophe, and other (undesirable) socio-technological and socio-economical events.
Here are the typical assumptions made in the cascading failure model:
- The nodes represent a component of an infrastructure network, such as power transmitters, or financial institutions. The nodes take non-negative real numbers as their dynamic states, which represent the amount of load or burden they are handling. The nodes can also take a specially designated “dead” state.
- Each node also has its own capacity as a static property.
- Their network can be in any topology.
- The edges can be directed or undirected.
- The node states will update either synchronously or asynchronously in discrete time steps, according to the following simple rules:
- If the node is dead, nothing happens.
- If the node is not dead but its load exceeds its capacity, it will turn to a dead state, and the load it was handling will be evenly distributed to its neighbors that are still alive.
Implement a simulator of the cascading failure model, and simulate the dynamics of the network from an initial condition that is constructed with randomly assigned loads and capacities, with one initially overloaded node. Try increasing the average load level relative to the average capacity level, and see when/how the network begins to show a cascading failure. Investigate which node has the most significant impact when it is overloaded. Also try several different network topologies to see if topology affects the resilience of the networks.
Create a continuous state/time network model of coupled oscillators where each oscillator tries to desynchronize from its neighbors. You can modify the Kuramoto model to develop such a model. Then simulate the network from an initial condition where the nodes’ phases are almost the same, and demonstrate that the network can spontaneously diversify node phases. Discuss potential application areas for such a model.