
7.3: Properties of Matrices

( \newcommand{\kernel}{\mathrm{null}\,}\)
The objects of study in linear algebra are linear operators. We have seen that linear operators can be represented as matrices through choices of ordered bases, and that matrices provide a means of efficient computation. We now begin an in depth study of matrices.
Definition: matrix, Column and Row Vectors
An r×k matrix M=(mij) for i=1,…,r;j=1,…,k is a rectangular array of real (or complex) numbers:
M=(m11m12⋯m1km21m22⋯m2k⋮⋮⋮mr1mr2⋯mrk).
The numbers mij are called entries. The superscript indexes the row of the matrix and the subscript indexes the column of the matrix in which mij appears.
An r×1 matrix v=(vr1)=(vr) is called a column vector, written
v=(v1v2⋮vr).
A 1×k matrix v=(v1k)=(vk) is called a row vector, written
v=(v1v2⋯vk).
The transpose of a column vector is the corresponding row vector and vice versa:
Example 7.3.1:
Let
v=(123).
Then
vT=(123),
and (vT)T=v.
A matrix is an efficient way to store information:
Example 7.3.2: Gif images
In computer graphics, you may have encountered image files with a .gif extension. These files are actually just matrices: at the start of the file the size of the matrix is given, after which each number is a matrix entry indicating the color of a particular pixel in the image.
This matrix then has its rows shuffled a bit: by listing, say, every eighth row, a web browser downloading the file can start displaying an incomplete version of the picture before the download is complete.
Finally, a compression algorithm is applied to the matrix to reduce the file size.
Example 7.3.3:
Graphs occur in many applications, ranging from telephone networks to airline routes. In the subject of graph theory, a graph is just a collection of vertices and some edges connecting vertices. A matrix can be used to indicate how many edges attach one vertex to another.
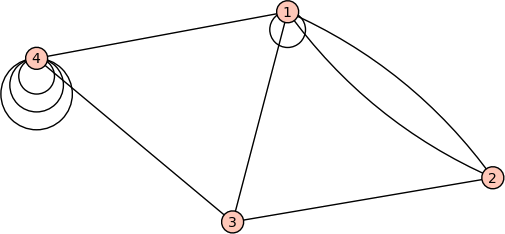
For example, the graph pictured above would have the following matrix, where mij indicates the number of edges between the vertices labeled i and j:
M=(1211201011011013)
This is an example of a symmetric matrix, since mij=mji.
The set of all r×k matrices
Mrk:={(mij)|mij∈R;i=1,…,r;j=1…k},
is itself a vector space with addition and scalar multiplication defined as follows:
M+N=(mij)+(nij)=(mij+nij)
rM=r(mij)=(rmij)
In other words, addition just adds corresponding entries in two matrices, and scalar multiplication multiplies every entry.
Notice that Mn1=ℜn is just the vector space of column vectors.
Recall that we can multiply an r×k matrix by a k×1 column vector to produce a r×1 column vector using the rule
MV=(k∑j=1mijvj).
This suggests the rule for multiplying an r×k matrix M by a k×s matrix~N: our k×s matrix N consists of s column vectors side-by-side, each of dimension k×1. We can multiply our r×k matrix M by each of these s column vectors using the rule we already know, obtaining s column vectors each of dimension r×1. If we place these s column vectors side-by-side, we obtain an r×s matrix MN.
That is, let
N=(n11n12⋯n1sn21n22⋯n2s⋮⋮⋮nk1nk2⋯nks)
and call the columns N1 through Ns:
N1=(n11n21⋮nk1),N2=(n12n22⋮nk2),…,Ns=(n1sn2s⋮nks).
Then
MN=M(|||N1N2⋯Ns|||)=(|||MN1MN2⋯MNs|||)
Concisely: If M=(mij) for i=1,…,r;j=1,…,k and N=(nij) for i=1,…,k;j=1,…,s, then MN=L where L=(ℓij) for i=i,…,r;j=1,…,s is given by
ℓij=k∑p=1mipnpj.
This rule obeys linearity.
Notice that in order for the multiplication make sense, the columns and rows must match. For an r×k matrix M and an s×m matrix N, then to make the product MN we must have k=s. Likewise, for the product NM, it is required that m=r. A common shorthand for keeping track of the sizes of the matrices involved in a given product is:
(r×k)×(k×m)=(r×m)
Example 7.3.4:
Multiplying a (3×1) matrix and a (1×2) matrix yields a (3×2) matrix.
(132)(23)=(1⋅21⋅33⋅23⋅32⋅22⋅3)=(236946)
Another way to view matrix multiplication is in terms of dot products:
The entries of MN are made from the dot products of the rows of M with the columns of N.
Example 7.3.5:
Let
M=(133526)=:(uTvTwT) and N=(231010)=:(abc)
where
u=(13),v=(35),w=(26),a=(20),b=(31),c=(10).
Then
$$
MN=\left(\!u⋅au⋅bu⋅cv⋅av⋅bv⋅cw⋅aw⋅bw⋅c\!\right)
=
(26161434122)\, .
\]
This fact has an obvious yet important consequence:
Theorem: orthogonal
Let M be a matrix and x a column vector. If
Mx=0
then the vector x is orthogonal to the rows of M.
Remark
Remember that the set of all vectors that can be obtained by adding up scalar multiples of the columns of a matrix is called its column space. Similarly the row space is the set of all row vectors obtained by adding up multiples of the rows of a matrix. The above theorem says that if Mx=0, then the vector x is orthogonal to every vector in the row space of M.
We know that r×k matrices can be used to represent linear transformations ℜk→ℜr via MV=k∑j=1mijvj, which is the same rule used when we multiply an r×k matrix by a k×1 vector to produce an r×1 vector.
Likewise, we can use a matrix N=(nij) to define a linear transformation of a vector space of matrices. For example
L:MskN⟶Mrk,
L(M)=(lik) where lik=s∑j=1nijmjk.
This is the same as the rule we use to multiply matrices. In other words, L(M)=NM is a linear transformation.
Matrix Terminology
Let M=(mij) be a matrix. The entries mii are called diagonal, and the set {m11, m22, …} is called the diagonal of the matrix.
Any r×r matrix is called a square matrix. A square matrix that is zero for all non-diagonal entries is called a diagonal matrix. An example of a square diagonal matrix is
$$(200030000)\, .\]
The r×r diagonal matrix with all diagonal entries equal to 1 is called the identity matrix, Ir, or just I. An identity matrix looks like
I=(100⋯0010⋯0001⋯0⋮⋮⋮⋱⋮000⋯1).
The identity matrix is special because IrM=MIk=M for all M of size r×k.
Definition
The transpose of an r×k matrix M=(mij) is the k×r matrix with entries
MT=(ˆmij)
with ˆmij=mji.
A matrix M is symmetric if M=MT.
Example 7.3.6:
\[(256134)^{T} =
(215364)\, ,and
(256134)
(256134)^{T} =
(65434326)\, ,$$
is symmetric.
Observations
- Only square matrices can be symmetric.
- The transpose of a column vector is a row vector, and vice-versa.
- Taking the transpose of a matrix twice does nothing. \emph{i.e.,} $(M^T)^T=M$.
Theorem: Transpose and Multiplication
Let M,N be matrices such that MN makes sense. Then
\[(MN)^{T}= N^{T}M^{T}.$$
The proof of this theorem is left to Review Question 2.
Associativity and Non-Commutativity
Many properties of matrices following from the same property for real numbers. Here is an example.
Example 7.3.7:
Associativity of matrix multiplication. We know for real numbers x, y and z that
x(yz)=(xy)z,
i.e., the order of bracketing does not matter. The same property holds for matrix multiplication, let us show why.
Suppose M=(mij), N=(njk) and R=(rkl) are, respectively, m×n, n×r and r×t matrices. Then from the rule for matrix multiplication we have
MN=(n∑j=1mijnjk) and NR=(r∑k=1njkrkl).
So first we compute
(MN)R=(r∑k=1[n∑j=1mijnjk]rkl)=(r∑k=1n∑j=1[mijnjk]rkl)=(r∑k=1n∑j=1mijnjkrkl).
In the first step we just wrote out the definition for matrix multiplication, in the second step we moved summation symbol outside the bracket (this is just the distributive property x(y+z)=xy+xz for numbers) and in the last step we used the associativity property for real numbers to remove the square brackets. Exactly the same reasoning shows that
M(NR)=(n∑j=1mij[r∑k=1njkrkl])=(r∑k=1n∑j=1mij[njkrkl])=(r∑k=1n∑j=1mijnjkrkl).
This is the same as above so we are done. As a fun remark, note that Einstein would simply have written
(MN)R=(mijnjk)rkl=mijnjkrkl=mij(njkrkl)=M(NR).
Sometimes matrices do not share the properties of regular numbers. In particular, for generic n×n square matrices M and N,
$$MN\neq NM\, .\]
(Matrix multiplication does not commute.)
(1101)(1011)=(2111)
On the other hand:
(1011)(1101)=(1112).
Since n×n matrices are linear transformations ℜn→ℜn, we can see that the order of successive linear transformations matters. Here is an example of matrices acting on objects in three dimensions that also shows matrices not commuting.
Example 7.3.8:
In Review Problem 3, you learned that the matrix
M=(cosθsinθ−sinθcosθ),
rotates vectors in the plane by an angle θ. We can generalize this, using block matrices, to three dimensions. In fact the following matrices built from a 2×2 rotation matrix, a 1×1 identity matrix and zeroes everywhere else
M=(cosθsinθ0−sinθcosθ0001)andN=(1000cosθsinθ0−sinθcosθ),
perform rotations by an angle θ in the xy and yz planes, respectively. Because, they rotate single vectors, you can also use them to rotate objects built from a collection of vectors like pretty colored blocks! Here is a picture of M and then N acting on such a block, compared with the case of N followed by M. The special case of θ=90∘ is shown.
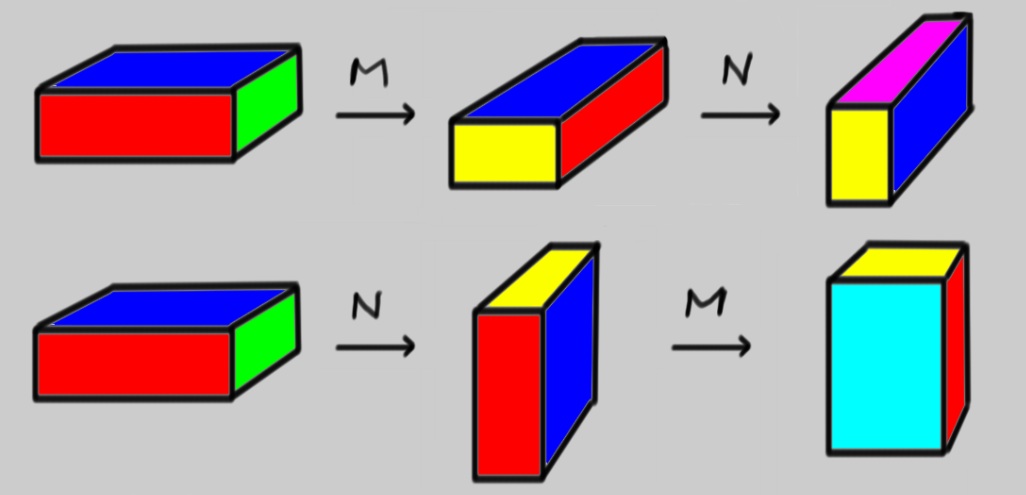
Notice how the end products of MN and NM are different, so MN≠NM here.
Block Matrices
It is often convenient to partition a matrix M into smaller matrices called blocks, like so:
M=(1231456078910120)=(ABCD)
Here A=(123456789), B=(101), C=(012), D=(0).
1. The blocks of a block matrix must fit together to form a rectangle. So (BADC) makes sense, but
(CBDA) does not.
2. There are many ways to cut up an n×n matrix into blocks. Often context or the entries of the matrix will suggest a useful way to divide the matrix into blocks. For example, if there are large blocks of zeros in a matrix, or blocks that look like an identity matrix, it can be useful to partition the matrix accordingly.
3. Matrix operations on block matrices can be carried out by treating the blocks as matrix entries. In the example above,
M2=(ABCD)(ABCD)=(A2+BCAB+BDCA+DCCB+D2)
Computing the individual blocks, we get:
A2+BC=(303744668196102127152)AB+BD=(41016)CA+DC=(182124)CB+D2=(2)
Assembling these pieces into a block matrix gives:
(30374446681961010212715216410162)
This is exactly M2.
The Algebra of Square Matrices
Not every pair of matrices can be multiplied. When multiplying two matrices, the number of rows in the left matrix must equal the number of columns in the right. For an r×k matrix M and an s×l matrix N, then we must have k=s.
This is not a problem for square matrices of the same size, though. Two n×n matrices can be multiplied in either order. For a single matrix M∈Mnn, we can form M2=MM, M3=MMM, and so on. It is useful to define M0=I, the identity matrix, just like x0=1 for numbers.
As a result, any polynomial can be evaluated on a matrix.
Example 7.3.9:
Let f(x)=x−2x2+3x3
and M=(1t01). Then:
M2=(12t01),M3=(13t01),…
Hence:
f(M)=(1t01)−2(12t01)+3(13t01)=(26t02)
Suppose f(x) is any function defined by a convergent Taylor Series:
f(x)=f(0)+f′(0)x+12!f″(0)x2+⋯.
Then we can define the matrix function by just plugging in M:
f(M)=f(0)+f′(0)M+12!f″(0)M2+⋯.
There are additional techniques to determine the convergence of Taylor Series of matrices, based on the fact that the convergence problem is simple for diagonal matrices. It also turns out that the matrix exponential
exp(M)=I+M+12M2+13!M3+⋯,
always converges.
Trace
A large matrix contains a great deal of information, some of which often reflects the fact that you have not set up your problem efficiently. For example, a clever choice of basis can often make the matrix of a linear transformation very simple. Therefore, finding ways to extract the essential information of a matrix is useful. Here we need to assume that n<∞ otherwise there are subtleties with convergence that we'd have to address.
Definition: Trace
The trace of a square matrix M=(mij) is the sum of its diagonal entries:
trM=n∑i=1mii.
While matrix multiplication does not commute, the trace of a product of matrices does not depend on the order of multiplication:
tr(MN)=tr(∑lMilNlj)=∑i∑lMilNli=∑l∑iNliMil=tr(∑iNliMil)=tr(NM).
Thus we have a Theorem:
Theorem
tr(MN)=tr(NM) for any square matrices M and N.
Example 7.3.11:
M=(1101),N=(1011).
so
MN=(2111)≠NM=(1112).
However, tr(MN)=2+1=3=1+2=tr(NM).
Another useful property of the trace is that:
trM=trMT
This is true because the trace only uses the diagonal entries, which are fixed by the transpose. For example:
\[\textit{tr}(1123) = 4 = \textit{tr}(1213) = \textit{tr}(1213)^{T}\, .
$$
Finally, trace is a linear transformation from matrices to the real numbers. This is easy to check.
Contributor
David Cherney, Tom Denton, and Andrew Waldron (UC Davis)