
12.1: Invariant Directions

( \newcommand{\kernel}{\mathrm{null}\,}\)
Have a look at the linear transformation L depicted below:
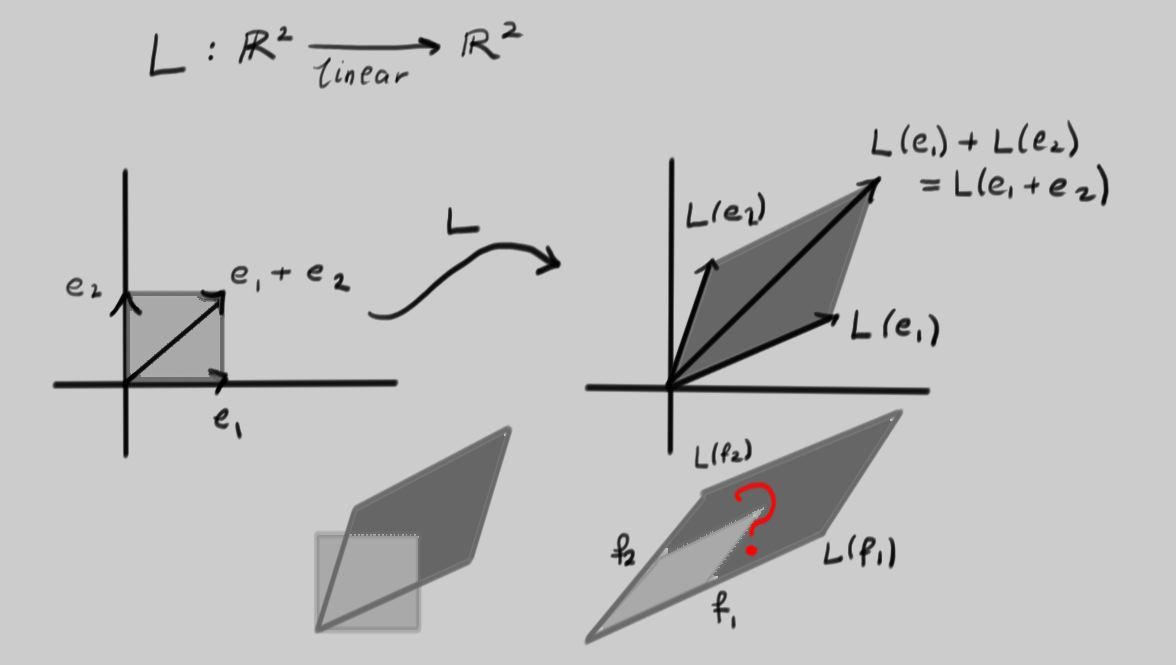
It was picked at random by choosing a pair of vectors L(e1) and L(e2) as the outputs of L acting on the canonical basis vectors. Notice how the unit square with a corner at the origin is mapped to a parallelogram. The second line of the picture shows these superimposed on one another. Now look at the second picture on that line. There, two vectors f1 and f2 have been carefully chosen such that if the inputs into L are in the parallelogram spanned by f1 and f2, the outputs also form a parallelogram with edges lying along the same two directions. Clearly this is a very special situation that should correspond to interesting properties of L.
Now lets try an explicit example to see if we can achieve the last picture:
Example 12.1.1:
Consider the linear transformation L such that L(10)=(−4−10) and L(01)=(37), so that the matrix of L is
(−43−107).
Recall that a vector is a direction and a magnitude; L applied to (10) or (01) changes both the direction and the magnitude of the vectors given to it.
Notice that L(35)=(−4⋅3+3⋅5−10⋅3+7⋅5)=(35). Then L fixes the direction (and actually also the magnitude) of the vector v1=(35).
Now, notice that any vector with the same direction as v1 can be written as cv1 for some constant c. Then L(cv1)=cL(v1)=cv1, so L fixes every vector pointing in the same direction as v1.
Also notice that
L(12)=(−4⋅1+3⋅2−10⋅1+7⋅2)=(24)=2(12),
so L fixes the direction of the vector v2=(12) but stretches v2 by a factor of 2. Now notice that for any constant c, L(cv2)=cL(v2)=2cv2. Then L stretches every vector pointing in the same direction as v2 by a factor of 2.
In short, given a linear transformation L it is sometimes possible to find a vector v≠0 and constant λ≠0 such that Lv=λv.

We call the direction of the vector v an invariant direction. In fact, any vector pointing in the same direction also satisfies this equation because L(cv)=cL(v)=λcv. More generally, any non-zero vector v that solves
Lv=λv
is called an eigenvector of L, and λ (which now need not be zero) is an eigenvalue. Since the direction is all we really care about here, then any other vector cv (so long as c≠0) is an equally good choice of eigenvector. Notice that the relation "u and v point in the same direction'' is an equivalence relation.
In our example of the linear transformation L with matrix
(−43−107),
we have seen that L enjoys the property of having two invariant directions, represented by eigenvectors v1 and v2 with eigenvalues 1 and 2, respectively.
It would be very convenient if we could write any vector w as a linear combination of v1 and v2. Suppose w=rv1+sv2 for some constants r and s. Then:
L(w)=L(rv1+sv2)=rL(v1)+sL(v2)=rv1+2sv2.
Now L just multiplies the number r by 1 and the number s by 2. If we could write this as a matrix, it would look like:
(1002)(st)
which is much slicker than the usual scenario
L(xy)=(abcd)(xy)=(ax+bycx+dy).
Here, s and t give the coordinates of w in terms of the vectors v1 and v2. In the previous example, we multiplied the vector by the matrix L and came up with a complicated expression. In these coordinates, we see that L has a very simple diagonal matrix, whose diagonal entries are exactly the eigenvalues of L.
This process is called diagonalization. It makes complicated linear systems much easier to analyze.
Now that we've seen what eigenvalues and eigenvectors are, there are a number of questions that need to be answered.
- How do we find eigenvectors and their eigenvalues?
- How many eigenvalues and (independent) eigenvectors does a given linear transformation have?
- When can a linear transformation be diagonalized?
We'll start by trying to find the eigenvectors for a linear transformation.
Example 12.1.2:
Let L:ℜ2→ℜ2 such that L(x,y)=(2x+2y,16x+6y). First, we find the matrix of L:
(xy)L⟼(22166)(xy).
We want to find an invariant direction v=(xy) such that
Lv=λv
or, in matrix notation,
(22166)(xy)=λ(xy)⇔(22166)(xy)=(λ00λ)(xy)⇔(2−λ2166−λ)(xy)=(00).
This is a homogeneous system, so it only has solutions when the matrix (2−λ2166−λ) is singular. In other words,
det(2−λ2166−λ)=0⇔(2−λ)(6−λ)−32=0⇔λ2−8λ−20=0⇔(λ−10)(λ+2)=0
For any square n×n matrix M, the polynomial in λ given by PM(λ)=det(λI−M)=(−1)ndet(M−λI) is called the characteristic polynomial of M, and its roots are the eigenvalues of M.
In this case, we see that L has two eigenvalues, λ1=10 and λ2=−2. To find the eigenvectors, we need to deal with these two cases separately. To do so, we solve the linear system (2−λ2166−λ)(xy)=(00) with the particular eigenvalue λ plugged in to the matrix.
1. [λ=10_:] We solve the linear system
(−8216−4)(xy)=(00).
Both equations say that y=4x, so any vector (x4x) will do. Since we only need the direction of the eigenvector, we can pick a value for x. Setting x=1 is convenient, and gives the eigenvector v1=(14).
2. [λ=−2_:] We solve the linear system
(42168)(xy)=(00).
Here again both equations agree, because we chose λ to make the system singular. We see that y=−2x works, so we can choose v2=(1−2).
Our process was the following:
- Find the characteristic polynomial of the matrix M for L, given by det(λI−M).
- Find the roots of the characteristic polynomial; these are the eigenvalues of L.
- For each eigenvalue λi, solve the linear system (M−λiI)v=0 to obtain an eigenvector v associated to λi.