
1.5: Adaptive stepping



- Last updated
- Sep 20, 2022
- Save as PDF

( \newcommand{\kernel}{\mathrm{null}\,}\)
Choosing
Up until now I have not said much about what stepsize
As a first step, if you know something about your ODE, and in particular know the timescale on which you expect to see the solution change, then choosing a stepsize to fit that time scale is easy. However, you commonly don’t know much about your solution’s behavior, which is why you are simulating it in the first place. Also, your ODE might behave badly – the solution might be smooth and slowly-varying for one period of time, then become bursty or quickly-varying at a subsequent time. Because of this, adaptive stepping is a common method useful to find the best stepsize for your simulation. The idea is simple:
- Take a single step of size
- Estimate the error between the true solution and your step.
- If the error is too large, then go back and retry your step with a smaller stepsize, for example
- However, if the error is small enough, increase the stepsize for future steps.
- Go back to 1 and continue stepping.
The idea is that the error incurred at each step can stay below some bound. In rough terms, if your solution changes slowly then you may take larger steps. But if your solution changes quickly, then you need to take smaller steps in order to maintain good accuracy.
Of course, the big question is, how to estimate the error? In the best case you could compare your computed solution against the true solution – but if you already had the true solution then you wouldn’t need to run an ODE solver in the first place! As a second-best case, you could use a so-called "oracle". In computer science, an oracle is a function or a program you can ask if your solution is true or not. That is, you can compute a step, then give the result to an oracle and it will say either "yes, your solution is correct" or "no, your solution is wrong". As a thought-experiment the oracle is generally regarded as a "black box", meaning that you don’t necessarily know how it works on the inside. It’s enough to simply know that the oracle will either say "yes" or "no" to your proposed answer, and the oracle will give an accurate judgement.
What is a good oracle for use with an ODE solver? Here are two possibilities:
- A simple idea is to just run each step twice: first use stepsize
- You could also consider taking a step using, say, forward Euler, and then taking the same step using, say, Heun’s method. The idea here is that since forward Euler is
It turns out that real-world solvers use a variant of possibility 2. Recall the fourth-order Runge-Kutta method from 4.6. The RK4 method presented there is a member of a larger family of Runge-Kutta methods of varying order. Matlab’s famous ode45() solver uses a method called Dormand-Prince order 4/5. In this solver, two Runge-Kutta methods are used. The first is a 4th-order Runge-Kutta variant (not the one presented in 4.6), and the second is a 5th-order Runge-Kutta method. The coefficients used to compute the intermediate steps of both methods are the same, only the final computation is different. Therefore, the amount of additional computation required to implement the oracle check is a small part of the overall calculation at each step. The combined Butcher tableau of the methods used in ode45() are shown in [tab:5.1]. You can also see these parameters in Matlab by issuing the command "dbtype 201:213 ode45", which emits the Butcher table in a slightly different form than above.
Regarding changing the step size, my naive suggestion in item 1 either halves or doubles the step size depending upon the error measured by the method. A better approach would be to tune the step size depending upon the magnitude of the observed error. That is, make the new step size depend upon the actual error observed instead of blindly halving or doubling the step. Algorithms for doing such fine-tuning exist, but are outside the scope of this booklet.
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1/5 | 1/5 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3/10 | 3/40 | 9/40 | 0 | 0 | 0 | 0 | 0 |
| 4/5 | 44/45 | -56/15 | 32/9 | 0 | 0 | 0 | 0 |
| 8/9 | 19372/6561 | -25360/2187 | 64448/6561 | -212/729 | 0 | 0 | 0 |
| 1 | 9017/3168 | -355/33 | 46732/5247 | 49/176 | -5103/18656 | 0 | 0 |
| 1 | 35/384 | 0 | 500/1113 | 125/192 | -2187/6784 | 11/84 | 0 |
| 35/384 | 0 | 500/1113 | 125/192 | -2187/6784 | 11/84 | 0 | |
| 5179/57600 | 0 | 7571/16695 | 393/640 | -92097/339200 | 187/2100 | 1/40 |
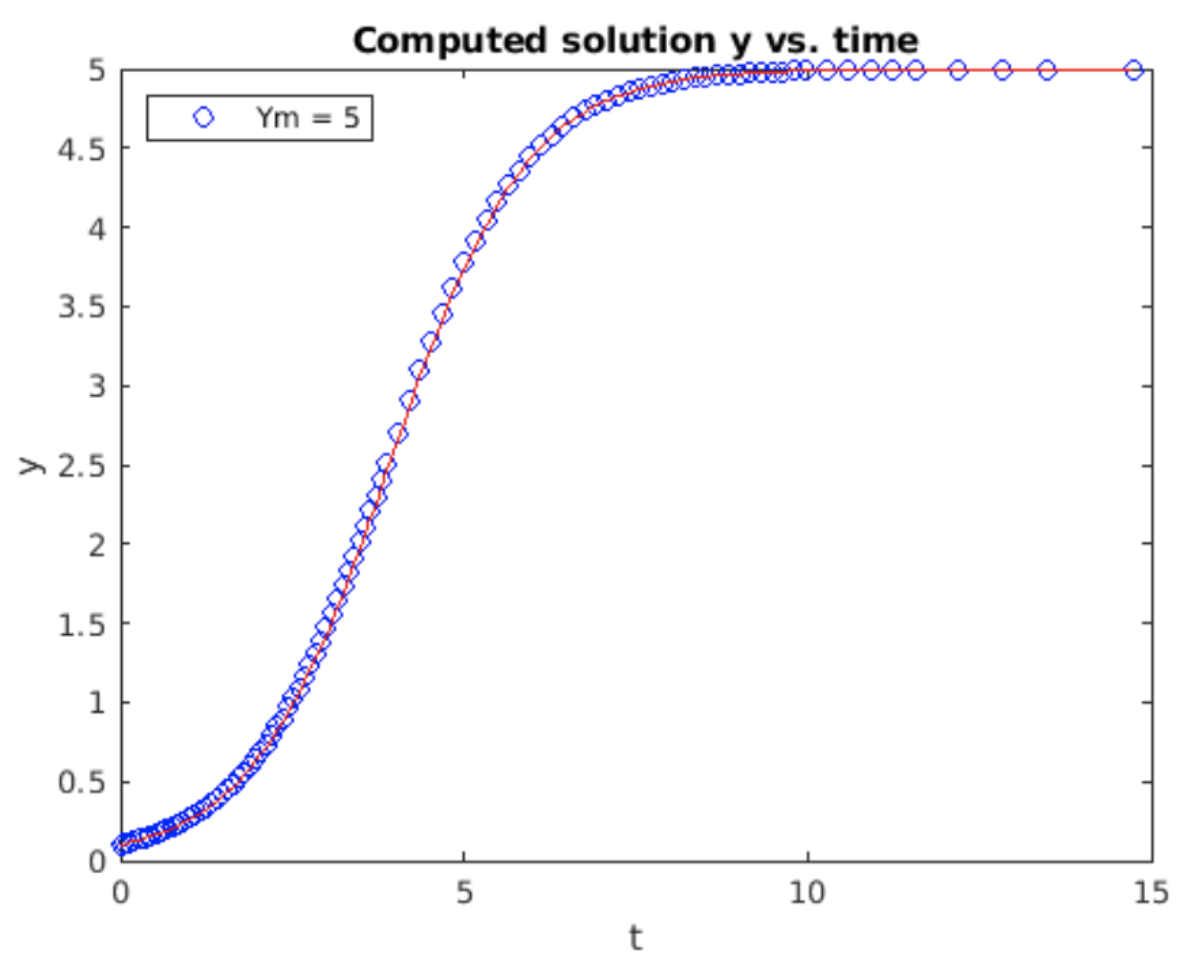
Example: the logistic equation
Instead of demonstrating the full Dormand-Prince 4/5, I will show a simpler adaptive stepper based on possibility 2 above. The program algorithm is shown in [alg:6]. I use the logistic equation as the example because the solution has (roughly) two regions of interest: A quickly varying phase of exponential growth at the beginning of the run followed by a plateau as
__________________________________________________________________________________________________________________________________
Algorithm 6 Naive adaptive step method
__________________________________________________________________________________________________________________________________
Inputs: initial condition
Initialize:
Initialize:
for
Get inital slope:
Take forward Euler step:
Get slope at new position:
Take Heun step:
Check difference between Euler and Heun steps:
if
Error too large - decrease step:
else if
Error very small - increase step:
else
Error neither too small or too large. Keep step.
end if
end for
return
Stiff ODEs
In the last section we saw an adaptive step method which took small steps when the solution varied quickly, and took larger steps when the solution varied slowly. The concept of slow vs. fast varying generalizes to the concept of "stiffness" of an ODE. An exact definition of the term "stiff" is hard to pin down, but the basic intuition is that a stiff ODE is one where you need to take small steps at some times to maintain accuracy, but can take much larger steps at other times. The problem with a stiff ODE is that if you use a fixed time step
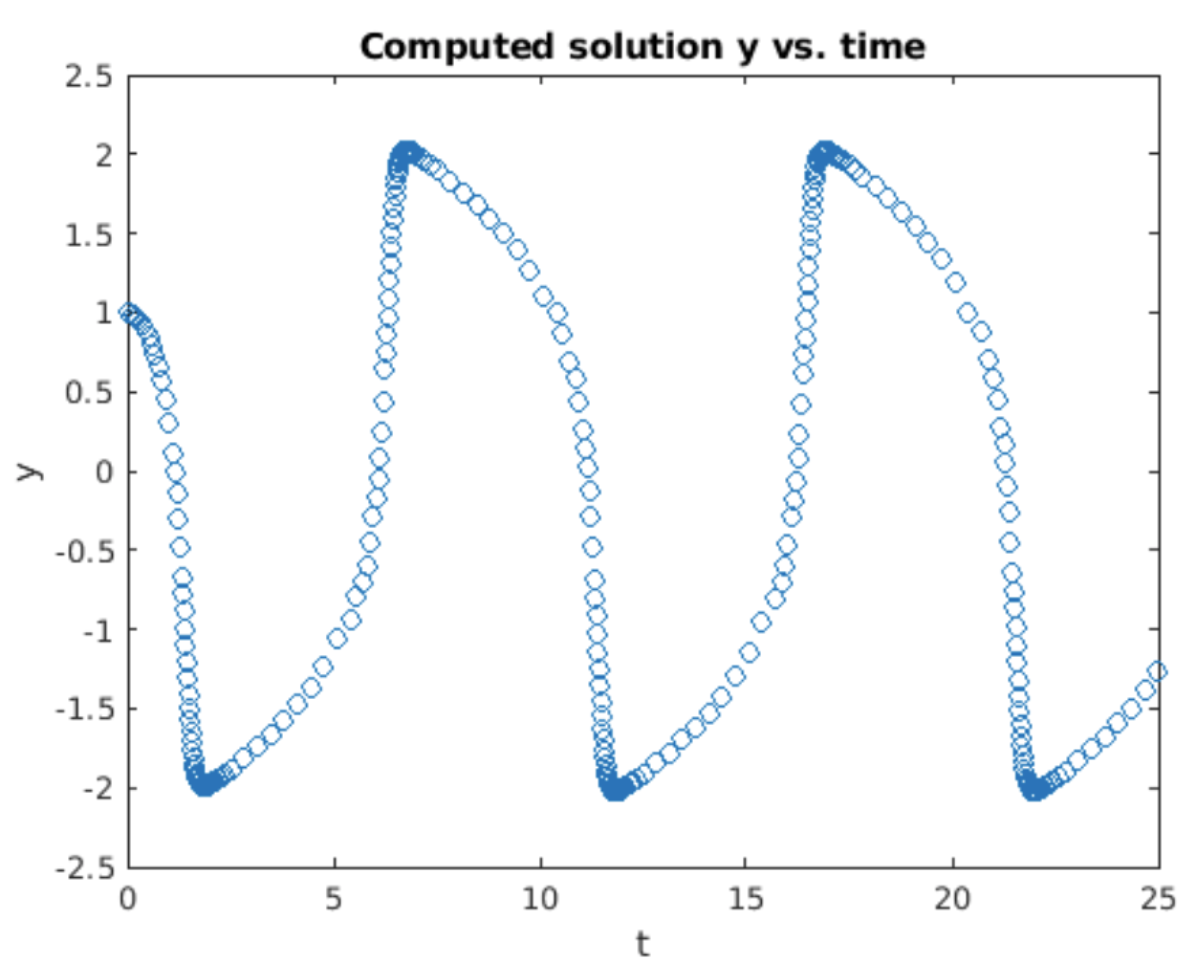
The Van der Pol equation is a common example of a stiff ODE. The solution computed using the adaptive stepper is shown in 5.2. When the solution peaks out at around
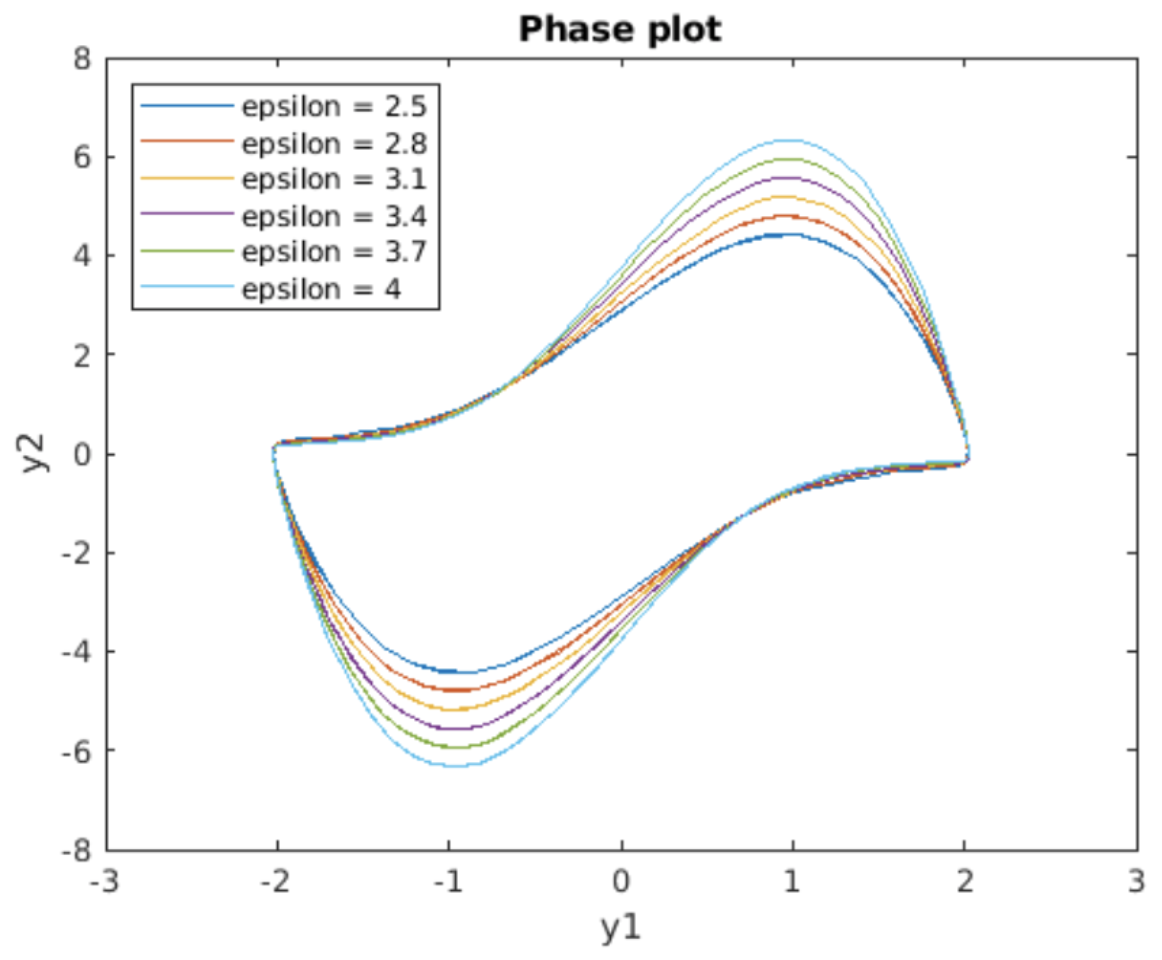
in the phase plane, but not in others? The answer comes from considering the entire family of solutions to the Van der Pol equation in the phase plane. A plot of the situation is shown in 5.4, which is a phase plot for varying values of
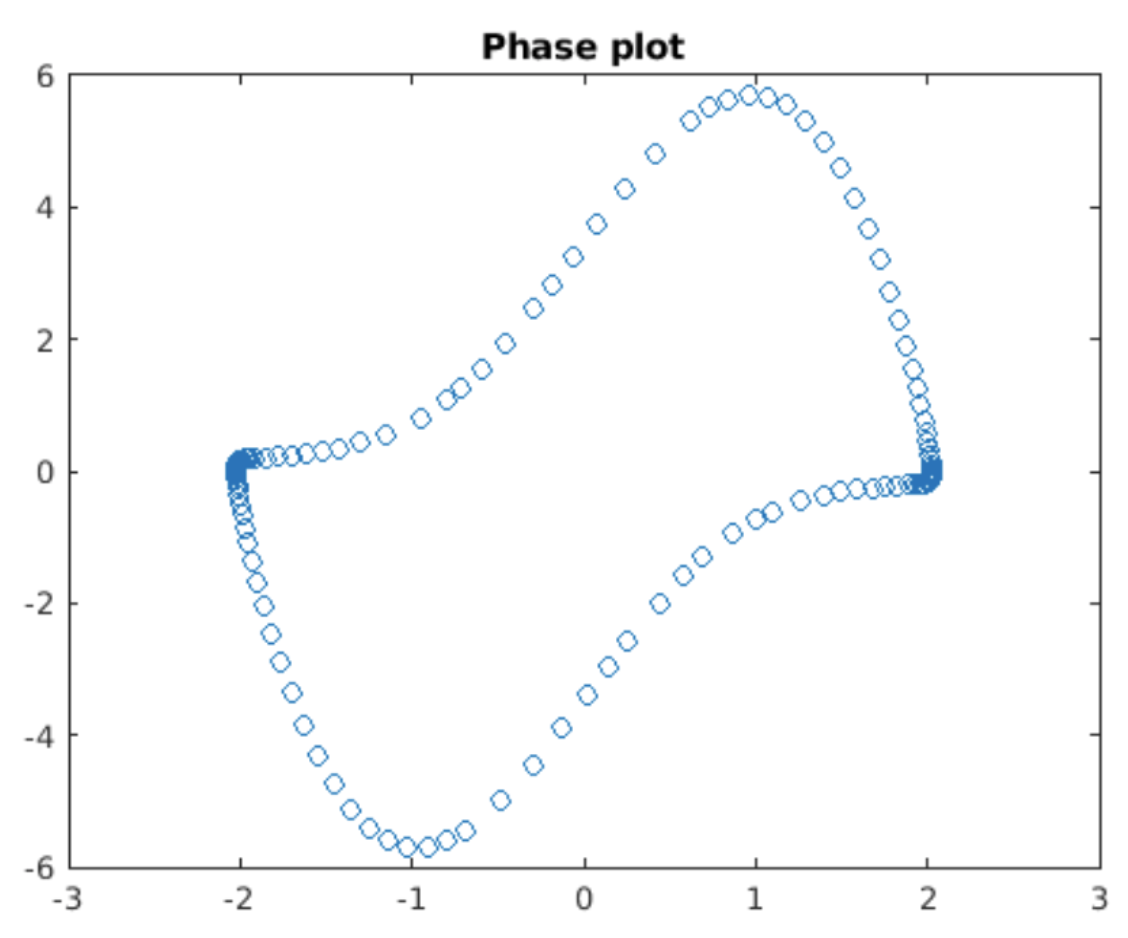
accordingly adjusts the step size to remain on the correct trajectory. The importance of adaptive step size solvers is simply that if the solver did not change its step size, then to get an accurate solution you would need to use a very small step
Chapter summary
Here are the important points made in this chapter:
- An adaptive step size method changes the step size
- A stiff system is one in which the solution evidences regions of fast and regions of slow variation, or more exactly high or low sensitivity to adjacent solutions to the ODE.