
4.11: Orthogonality
- Page ID
- 21269

\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\dsum}{\displaystyle\sum\limits} \)
\( \newcommand{\dint}{\displaystyle\int\limits} \)
\( \newcommand{\dlim}{\displaystyle\lim\limits} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\(\newcommand{\longvect}{\overrightarrow}\)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)- Determine if a given set is orthogonal or orthonormal.
- Determine if a given matrix is orthogonal.
- Given a linearly independent set, use the Gram-Schmidt Process to find corresponding orthogonal and orthonormal sets.
- Find the orthogonal projection of a vector onto a subspace.
- Find the least squares approximation for a collection of points.
In this section, we examine what it means for vectors (and sets of vectors) to be orthogonal and orthonormal. First, it is necessary to review some important concepts. You may recall the definitions for the span of a set of vectors and a linear independent set of vectors. We include the definitions and examples here for convenience.
The collection of all linear combinations of a set of vectors \(\{ \vec{u}_1, \cdots ,\vec{u}_k\}\) in \(\mathbb{R}^{n}\) is known as the span of these vectors and is written as \(\mathrm{span} \{\vec{u}_1, \cdots , \vec{u}_k\}\).
We call a collection of the form \(\mathrm{span} \{\vec{u}_1, \cdots , \vec{u}_k\}\) a subspace of \(\mathbb{R}^{n}\).
Consider the following example.
Describe the span of the vectors \(\vec{u}=\left[ \begin{array}{rrr} 1 & 1 & 0 \end{array} \right]^T\) and \(\vec{v}=\left[ \begin{array}{rrr} 3 & 2 & 0 \end{array} \right]^T \in \mathbb{R}^{3}\).
Solution
You can see that any linear combination of the vectors \(\vec{u}\) and \(\vec{v}\) yields a vector \(\left[ \begin{array}{rrr} x & y & 0 \end{array} \right]^T\) in the \(XY\)-plane.
Moreover every vector in the \(XY\)-plane is in fact such a linear combination of the vectors \(\vec{u}\) and \(\vec{v}\). That’s because \[\left[ \begin{array}{r} x \\ y \\ 0 \end{array} \right] = (-2x+3y) \left[ \begin{array}{r} 1 \\ 1 \\ 0 \end{array} \right] + (x-y)\left[ \begin{array}{r} 3 \\ 2 \\ 0 \end{array} \right]\nonumber \]
Thus span\(\{\vec{u},\vec{v}\}\) is precisely the \(XY\)-plane.
The span of a set of a vectors in \(\mathbb{R}^n\) is what we call a subspace of \(\mathbb{R}^n\). A subspace \(W\) is characterized by the feature that any linear combination of vectors of \(W\) is again a vector contained in \(W\).
Another important property of sets of vectors is called linear independence.
A set of non-zero vectors \(\{ \vec{u}_1, \cdots ,\vec{u}_k\}\) in \(\mathbb{R}^{n}\) is said to be linearly independent if no vector in that set is in the span of the other vectors of that set.
Here is an example.
Consider vectors \(\vec{u}=\left[ \begin{array}{rrr} 1 & 1 & 0 \end{array} \right]^T\), \(\vec{v}=\left[ \begin{array}{rrr} 3 & 2 & 0 \end{array} \right]^T\), and \(\vec{w}=\left[ \begin{array}{rrr} 4 & 5 & 0 \end{array} \right]^T \in \mathbb{R}^{3}\). Verify whether the set \(\{\vec{u}, \vec{v}, \vec{w}\}\) is linearly independent.
Solution
We already verified in Example \(\PageIndex{1}\) that \(\mathrm{span} \{\vec{u}, \vec{v} \}\) is the \(XY\)-plane. Since \(\vec{w}\) is clearly also in the \(XY\)-plane, then the set \(\{\vec{u}, \vec{v}, \vec{w}\}\) is not linearly independent.
In terms of spanning, a set of vectors is linearly independent if it does not contain unnecessary vectors. In the previous example you can see that the vector \(\vec{w}\) does not help to span any new vector not already in the span of the other two vectors. However you can verify that the set \(\{\vec{u}, \vec{v}\}\) is linearly independent, since you will not get the \(XY\)-plane as the span of a single vector.
We can also determine if a set of vectors is linearly independent by examining linear combinations. A set of vectors is linearly independent if and only if whenever a linear combination of these vectors equals zero, it follows that all the coefficients equal zero. It is a good exercise to verify this equivalence, and this latter condition is often used as the (equivalent) definition of linear independence.
If a subspace is spanned by a linearly independent set of vectors, then we say that it is a basis for the subspace.
Let \(V\) be a subspace of \(\mathbb{R}^{n}\). Then \(\left\{ \vec{u}_{1},\cdots ,\vec{u}_{k}\right\}\) is a basis for \(V\) if the following two conditions hold.
- \(\mathrm{span}\left\{ \vec{u}_{1},\cdots ,\vec{u}_{k}\right\} =V\)
- \(\left\{ \vec{u}_{1},\cdots ,\vec{u}_{k}\right\}\) is linearly independent
Thus the set of vectors \(\{\vec{u}, \vec{v}\}\) from Example \(\PageIndex{2}\) is a basis for \(XY\)-plane in \(\mathbb{R}^{3}\) since it is both linearly independent and spans the \(XY\)-plane.
Recall from the properties of the dot product of vectors that two vectors \(\vec{u}\) and \(\vec{v}\) are orthogonal if \(\vec{u} \cdot \vec{v} = 0\). Suppose a vector is orthogonal to a spanning set of \(\mathbb{R}^n\). What can be said about such a vector? This is the discussion in the following example.
Let \(\{\vec{x}_1, \vec{x}_2, \ldots, \vec{x}_k\}\in\mathbb{R}^n\) and suppose \(\mathbb{R}^n=\mathrm{span}\{\vec{x}_1, \vec{x}_2, \ldots, \vec{x}_k\}\). Furthermore, suppose that there exists a vector \(\vec{u}\in\mathbb{R}^n\) for which \(\vec{u}\cdot \vec{x}_j=0\) for all \(j\), \(1\leq j\leq k\). What type of vector is \(\vec{u}\)?
Solution
Write \(\vec{u}=t_1\vec{x}_1 + t_2\vec{x}_2 +\cdots +t_k\vec{x}_k\) for some \(t_1, t_2, \ldots, t_k\in\mathbb{R}\) (this is possible because \(\vec{x}_1, \vec{x}_2, \ldots, \vec{x}_k\) span \(\mathbb{R}^n\)).
Then
\[\begin{aligned} \| \vec{u} \| ^2 & = \vec{u}\cdot\vec{u} \\ & = \vec{u}\cdot(t_1\vec{x}_1 + t_2\vec{x}_2 +\cdots +t_k\vec{x}_k) \\ & = \vec{u}\cdot (t_1\vec{x}_1) + \vec{u}\cdot (t_2\vec{x}_2) + \cdots + \vec{u}\cdot (t_k\vec{x}_k) \\ & = t_1(\vec{u}\cdot \vec{x}_1) + t_2(\vec{u}\cdot \vec{x}_2) + \cdots + t_k(\vec{u}\cdot \vec{x}_k) \\ & = t_1(0) + t_2(0) + \cdots + t_k(0) = 0.\end{aligned}\]
Since \( \| \vec{u} \| ^2 =0\), \( \| \vec{u} \| =0\). We know that \( \| \vec{u} \| =0\) if and only if \(\vec{u}=\vec{0}_n\). Therefore, \(\vec{u}=\vec{0}_n\). In conclusion, the only vector orthogonal to every vector of a spanning set of \(\mathbb{R}^n\) is the zero vector.
We can now discuss what is meant by an orthogonal set of vectors.
Let \(\{ \vec{u}_1, \vec{u}_2, \cdots, \vec{u}_m \}\) be a set of vectors in \(\mathbb{R}^n\). Then this set is called an orthogonal set if the following conditions hold:
- \(\vec{u}_i \cdot \vec{u}_j = 0\) for all \(i \neq j\)
- \(\vec{u}_i \neq \vec{0}\) for all \(i\)
If we have an orthogonal set of vectors and normalize each vector so they have length 1, the resulting set is called an orthonormal set of vectors. They can be described as follows.
A set of vectors, \(\left\{ \vec{w}_{1},\cdots ,\vec{w}_{m}\right\}\) is said to be an orthonormal set if \[\vec{w}_i \cdot \vec{w}_j = \delta _{ij} = \left\{ \begin{array}{c} 1\text{ if }i=j \\ 0\text{ if }i\neq j \end{array} \right.\nonumber \]
Note that all orthonormal sets are orthogonal, but the reverse is not necessarily true since the vectors may not be normalized. In order to normalize the vectors, we simply need divide each one by its length.
Normalizing an orthogonal set is the process of turning an orthogonal (but not orthonormal) set into an orthonormal set. If \(\{ \vec{u}_1, \vec{u}_2, \ldots, \vec{u}_k\}\) is an orthogonal subset of \(\mathbb{R}^n\), then \[\left\{ \frac{1}{ \| \vec{u}_1 \| }\vec{u}_1, \frac{1}{ \| \vec{u}_2 \| }\vec{u}_2, \ldots, \frac{1}{ \| \vec{u}_k \| }\vec{u}_k \right\}\nonumber \] is an orthonormal set.
We illustrate this concept in the following example.
Consider the set of vectors given by \[\left\{ \vec{u}_1, \vec{u}_2 \right\} = \left\{ \left[ \begin{array}{c} 1 \\ 1 \end{array} \right], \left[ \begin{array}{r} -1 \\ 1 \end{array} \right] \right\}\nonumber \] Show that it is an orthogonal set of vectors but not an orthonormal one. Find the corresponding orthonormal set.
Solution
One easily verifies that \(\vec{u}_1 \cdot \vec{u}_2 = 0\) and \(\left\{ \vec{u}_1, \vec{u}_2 \right\}\) is an orthogonal set of vectors. On the other hand one can compute that \( \| \vec{u}_1 \| = \| \vec{u}_2 \| = \sqrt{2} \neq 1\) and thus it is not an orthonormal set.
Thus to find a corresponding orthonormal set, we simply need to normalize each vector. We will write \(\{ \vec{w}_1, \vec{w}_2 \}\) for the corresponding orthonormal set. Then, \[\begin{aligned} \vec{w}_1 &= \frac{1}{ \| \vec{u}_1 \| } \vec{u}_1\\ &= \frac{1}{\sqrt{2}} \left[ \begin{array}{c} 1 \\ 1 \end{array} \right] \\ &= \left[ \begin{array}{c} \frac{1}{\sqrt{2}}\\ \frac{1}{\sqrt{2}} \end{array} \right]\end{aligned}\]
Similarly, \[\begin{aligned} \vec{w}_2 &= \frac{1}{ \| \vec{u}_2 \| } \vec{u}_2\\ &= \frac{1}{\sqrt{2}} \left[ \begin{array}{r} -1 \\ 1 \end{array} \right] \\ &= \left[ \begin{array}{r} -\frac{1}{\sqrt{2}}\\ \frac{1}{\sqrt{2}} \end{array} \right]\end{aligned}\]
Therefore the corresponding orthonormal set is \[\left\{ \vec{w}_1, \vec{w}_2 \right\} = \left\{ \left[ \begin{array}{c} \frac{1}{\sqrt{2}}\\ \frac{1}{\sqrt{2}} \end{array} \right], \left[ \begin{array}{r} -\frac{1}{\sqrt{2}}\\ \frac{1}{\sqrt{2}} \end{array} \right] \right\}\nonumber \]
You can verify that this set is orthogonal.
Consider an orthogonal set of vectors in \(\mathbb{R}^n\), written \(\{ \vec{w}_1, \cdots, \vec{w}_k \}\) with \(k \leq n\). The span of these vectors is a subspace \(W\) of \(\mathbb{R}^n\). If we could show that this orthogonal set is also linearly independent, we would have a basis of \(W\). We will show this in the next theorem.
Let \(\{ \vec{w}_1, \vec{w}_2, \cdots, \vec{w}_k \}\) be an orthonormal set of vectors in \(\mathbb{R}^n\). Then this set is linearly independent and forms a basis for the subspace \(W = \mathrm{span} \{ \vec{w}_1, \vec{w}_2, \cdots, \vec{w}_k \}\).
- Proof
-
To show it is a linearly independent set, suppose a linear combination of these vectors equals \(\vec{0}\), such as: \[a_1 \vec{w}_1 + a_2 \vec{w}_2 + \cdots + a_k \vec{w}_k = \vec{0}, a_i \in \mathbb{R}\nonumber \] We need to show that all \(a_i = 0\). To do so, take the dot product of each side of the above equation with the vector \(\vec{w}_i\) and obtain the following.
\[\begin{aligned} \vec{w}_i \cdot (a_1 \vec{w}_1 + a_2 \vec{w}_2 + \cdots + a_k \vec{w}_k ) &= \vec{w}_i \cdot \vec{0}\\ a_1 (\vec{w}_i \cdot \vec{w}_1) + a_2 (\vec{w}_i \cdot \vec{w}_2) + \cdots + a_k (\vec{w}_i \cdot \vec{w}_k) &= 0 \end{aligned}\]
Now since the set is orthogonal, \(\vec{w}_i \cdot \vec{w}_m = 0\) for all \(m \neq i\), so we have: \[a_1 (0) + \cdots + a_i(\vec{w}_i \cdot \vec{w}_i) + \cdots + a_k (0) = 0\nonumber \] \[a_i \| \vec{w}_i \| ^2 = 0\nonumber \]
Since the set is orthogonal, we know that \( \| \vec{w}_i \| ^2 \neq 0\). It follows that \(a_i =0\). Since the \(a_i\) was chosen arbitrarily, the set \(\{ \vec{w}_1, \vec{w}_2, \cdots, \vec{w}_k \}\) is linearly independent.
Finally since \(W = \mbox{span} \{ \vec{w}_1, \vec{w}_2, \cdots, \vec{w}_k \}\), the set of vectors also spans \(W\) and therefore forms a basis of \(W\).
If an orthogonal set is a basis for a subspace, we call this an orthogonal basis. Similarly, if an orthonormal set is a basis, we call this an orthonormal basis.
We conclude this section with a discussion of Fourier expansions. Given any orthogonal basis \(B\) of \(\mathbb{R}^n\) and an arbitrary vector \(\vec{x} \in \mathbb{R}^n\), how do we express \(\vec{x}\) as a linear combination of vectors in \(B\)? The solution is Fourier expansion.
Let \(V\) be a subspace of \(\mathbb{R}^n\) and suppose \(\{ \vec{u}_1, \vec{u}_2, \ldots, \vec{u}_m \}\) is an orthogonal basis of \(V\). Then for any \(\vec{x}\in V\),
\[\vec{x} = \left(\frac{\vec{x}\cdot \vec{u}_1}{ \| \vec{u}_1 \| ^2}\right) \vec{u}_1 + \left(\frac{\vec{x}\cdot \vec{u}_2}{ \| \vec{u}_2 \| ^2}\right) \vec{u}_2 + \cdots + \left(\frac{\vec{x}\cdot \vec{u}_m}{ \| \vec{u}_m \| ^2}\right) \vec{u}_m\nonumber \]
This expression is called the Fourier expansion of \(\vec{x}\), and \[\frac{\vec{x}\cdot \vec{u}_j}{ \| \vec{u}_j \| ^2},\nonumber \] \(j=1,2,\ldots,m\) are the Fourier coefficients.
Consider the following example.
Let \(\vec{u}_1= \left[\begin{array}{r} 1 \\ -1 \\ 2 \end{array}\right], \vec{u}_2= \left[\begin{array}{r} 0 \\ 2 \\ 1 \end{array}\right]\), and \(\vec{u}_3 =\left[\begin{array}{r} 5 \\ 1 \\ -2 \end{array}\right]\), and let \(\vec{x} =\left[\begin{array}{r} 1 \\ 1 \\ 1 \end{array}\right]\).
Then \(B=\{ \vec{u}_1, \vec{u}_2, \vec{u}_3\}\) is an orthogonal basis of \(\mathbb{R}^3\).
Compute the Fourier expansion of \(\vec{x}\), thus writing \(\vec{x}\) as a linear combination of the vectors of \(B\).
Solution
Since \(B\) is a basis (verify!) there is a unique way to express \(\vec{x}\) as a linear combination of the vectors of \(B\). Moreover since \(B\) is an orthogonal basis (verify!), then this can be done by computing the Fourier expansion of \(\vec{x}\).
That is:
\[\vec{x} = \left(\frac{\vec{x}\cdot \vec{u}_1}{ \| \vec{u}_1 \| ^2}\right) \vec{u}_1 + \left(\frac{\vec{x}\cdot \vec{u}_2}{ \| \vec{u}_2 \| ^2}\right) \vec{u}_2 + \left(\frac{\vec{x}\cdot \vec{u}_3}{ \| \vec{u}_3 \| ^2}\right) \vec{u}_3. \nonumber\]
We readily compute:
\[\frac{\vec{x}\cdot\vec{u}_1}{ \| \vec{u}_1 \| ^2} = \frac{2}{6}, \; \frac{\vec{x}\cdot\vec{u}_2}{ \| \vec{u}_2 \| ^2} = \frac{3}{5}, \mbox{ and } \frac{\vec{x}\cdot\vec{u}_3}{ \| \vec{u}_3 \| ^2} = \frac{4}{30}. \nonumber\]
Therefore, \[\left[\begin{array}{r} 1 \\ 1 \\ 1 \end{array}\right] = \frac{1}{3}\left[\begin{array}{r} 1 \\ -1 \\ 2 \end{array}\right] +\frac{3}{5}\left[\begin{array}{r} 0 \\ 2 \\ 1 \end{array}\right] +\frac{2}{15}\left[\begin{array}{r} 5 \\ 1 \\ -2 \end{array}\right]. \nonumber\]
Orthogonal Matrices
Recall that the process to find the inverse of a matrix was often cumbersome. In contrast, it was very easy to take the transpose of a matrix. Luckily for some special matrices, the transpose equals the inverse. When an \(n \times n\) matrix has all real entries and its transpose equals its inverse, the matrix is called an orthogonal matrix.
The precise definition is as follows.
A real \(n\times n\) matrix \(U\) is called an orthogonal matrix if
\[UU^{T}=U^{T}U=I.\nonumber \]
Note since \(U\) is assumed to be a square matrix, it suffices to verify only one of these equalities \(UU^{T}=I\) or \(U^{T}U=I\) holds to guarantee that \(U^T\) is the inverse of \(U\).
Consider the following example.
Orthogonal Matrix Show the matrix \[U=\left[ \begin{array}{rr} \frac{1}{\sqrt{2}} & \frac{1}{\sqrt{2}} \\ \frac{1}{\sqrt{2}} & -\frac{1}{\sqrt{2}} \end{array} \right]\nonumber \] is orthogonal.
Solution
All we need to do is verify (one of the equations from) the requirements of Definition \(\PageIndex{7}\).
\[UU^{T}=\left[ \begin{array}{rr} \frac{1}{\sqrt{2}} & \frac{1}{\sqrt{2}} \\ \frac{1}{\sqrt{2}} & -\frac{1}{\sqrt{2}} \end{array} \right] \left[ \begin{array}{rr} \frac{1}{\sqrt{2}} & \frac{1}{\sqrt{2}} \\ \frac{1}{\sqrt{2}} & -\frac{1}{\sqrt{2}} \end{array} \right] = \left[ \begin{array}{cc} 1 & 0 \\ 0 & 1 \end{array} \right]\nonumber \]
Since \(UU^{T} = I\), this matrix is orthogonal.
Here is another example.
Orthogonal Matrix Let \(U=\left[ \begin{array}{rrr} 1 & 0 & 0 \\ 0 & 0 & -1 \\ 0 & -1 & 0 \end{array} \right] .\) Is \(U\) orthogonal?
Solution
Again the answer is yes and this can be verified simply by showing that \(U^{T}U=I\):
\[\begin{aligned} U^{T}U&=\left[ \begin{array}{rrr} 1 & 0 & 0 \\ 0 & 0 & -1 \\ 0 & -1 & 0 \end{array} \right] ^{T}\left[ \begin{array}{rrr} 1 & 0 & 0 \\ 0 & 0 & -1 \\ 0 & -1 & 0 \end{array} \right] \\ &=\left[ \begin{array}{rrr} 1 & 0 & 0 \\ 0 & 0 & -1 \\ 0 & -1 & 0 \end{array} \right] \left[ \begin{array}{rrr} 1 & 0 & 0 \\ 0 & 0 & -1 \\ 0 & -1 & 0 \end{array} \right] \\ &=\left[ \begin{array}{rrr} 1 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \end{array} \right]\end{aligned}\]
When we say that \(U\) is orthogonal, we are saying that \(UU^T=I\), meaning that \[\sum_{j}u_{ij}u_{jk}^{T}=\sum_{j}u_{ij}u_{kj}=\delta _{ik}\nonumber \] where \(\delta _{ij}\) is the Kronecker symbol defined by \[\delta _{ij}=\left\{ \begin{array}{c} 1 \text{ if }i=j \\ 0\text{ if }i\neq j \end{array} \right.\nonumber \]
In words, the product of the \(i^{th}\) row of \(U\) with the \(k^{th}\) row gives \(1\) if \(i=k\) and \(0\) if \(i\neq k.\) The same is true of the columns because \(U^{T}U=I\) also. Therefore, \[\sum_{j}u_{ij}^{T}u_{jk}=\sum_{j}u_{ji}u_{jk}=\delta _{ik}\nonumber \] which says that the product of one column with another column gives \(1\) if the two columns are the same and \(0\) if the two columns are different.
More succinctly, this states that if \(\vec{u}_{1},\cdots ,\vec{u}_{n}\) are the columns of \(U,\) an orthogonal matrix, then \[\vec{u}_{i}\cdot \vec{u}_{j}=\delta _{ij} = \left\{ \begin{array}{c} 1\text{ if }i=j \\ 0\text{ if }i\neq j \end{array} \right.\nonumber \]
We will say that the columns form an orthonormal set of vectors, and similarly for the rows. Thus a matrix is orthogonal if its rows (or columns) form an orthonormal set of vectors. Notice that the convention is to call such a matrix orthogonal rather than orthonormal (although this may make more sense!).
The rows of an \(n \times n\) orthogonal matrix form an orthonormal basis of \(\mathbb{R}^n\). Further, any orthonormal basis of \(\mathbb{R}^n\) can be used to construct an \(n \times n\) orthogonal matrix.
- Proof
-
Recall from Theorem \(\PageIndex{1}\) that an orthonormal set is linearly independent and forms a basis for its span. Since the rows of an \(n \times n\) orthogonal matrix form an orthonormal set, they must be linearly independent. Now we have \(n\) linearly independent vectors, and it follows that their span equals \(\mathbb{R}^n\). Therefore these vectors form an orthonormal basis for \(\mathbb{R}^n\).
Suppose now that we have an orthonormal basis for \(\mathbb{R}^n\). Since the basis will contain \(n\) vectors, these can be used to construct an \(n \times n\) matrix, with each vector becoming a row. Therefore the matrix is composed of orthonormal rows, which by our above discussion, means that the matrix is orthogonal. Note we could also have construct a matrix with each vector becoming a column instead, and this would again be an orthogonal matrix. In fact this is simply the transpose of the previous matrix.
Consider the following proposition.
Det Suppose \(U\) is an orthogonal matrix. Then \(\det \left( U\right) = \pm 1.\)
- Proof
-
This result follows from the properties of determinants. Recall that for any matrix \(A\), \(\det(A)^T = \det(A)\). Now if \(U\) is orthogonal, then: \[(\det \left( U\right)) ^{2}=\det \left( U^{T}\right) \det \left( U\right) =\det \left( U^{T}U\right) =\det \left( I\right) =1\nonumber \]
Therefore \((\det (U))^2 = 1\) and it follows that \(\det \left( U\right) = \pm 1\).
Orthogonal matrices are divided into two classes, proper and improper. The proper orthogonal matrices are those whose determinant equals 1 and the improper ones are those whose determinant equals \(-1\). The reason for the distinction is that the improper orthogonal matrices are sometimes considered to have no physical significance. These matrices cause a change in orientation which would correspond to material passing through itself in a non physical manner. Thus in considering which coordinate systems must be considered in certain applications, you only need to consider those which are related by a proper orthogonal transformation. Geometrically, the linear transformations determined by the proper orthogonal matrices correspond to the composition of rotations.
We conclude this section with two useful properties of orthogonal matrices.
Suppose \(A\) and \(B\) are orthogonal matrices. Then \(AB\) and \(A^{-1}\) both exist and are orthogonal.
Solution
First we examine the product \(AB\). \[(AB)(B^TA^T)=A(BB^T)A^T =AA^T=I\nonumber \] Since \(AB\) is square, \(B^TA^T=(AB)^T\) is the inverse of \(AB\), so \(AB\) is invertible, and \((AB)^{-1}=(AB)^T\) Therefore, \(AB\) is orthogonal.
Next we show that \(A^{-1}=A^T\) is also orthogonal. \[(A^{-1})^{-1} = A = (A^T)^{T} =(A^{-1})^{T}\nonumber \] Therefore \(A^{-1}\) is also orthogonal.
Gram-Schmidt Process
The Gram-Schmidt process is an algorithm to transform a set of vectors into an orthonormal set spanning the same subspace, that is generating the same collection of linear combinations (see Definition 9.2.2).
The goal of the Gram-Schmidt process is to take a linearly independent set of vectors and transform it into an orthonormal set with the same span. The first objective is to construct an orthogonal set of vectors with the same span, since from there an orthonormal set can be obtained by simply dividing each vector by its length.
Let \(\{ \vec{u}_1,\cdots ,\vec{u}_n \}\) be a set of linearly independent vectors in \(\mathbb{R}^{n}\).
I: Construct a new set of vectors \(\{ \vec{v}_1,\cdots ,\vec{v}_n \}\) as follows: \[\begin{array}{ll} \vec{v}_1 & = \vec{u}_1 \\ \vec{v}_{2} & = \vec{u}_{2} - \left( \dfrac{ \vec{u}_2 \cdot \vec{v}_1}{ \| \vec{v}_1 \| ^2} \right) \vec{v}_1\\ \vec{v}_{3} & = \vec{u}_{3} - \left( \dfrac{\vec{u}_3 \cdot \vec{v}_1}{ \| \vec{v}_1 \| ^2} \right) \vec{v}_1 - \left( \dfrac{\vec{u}_3 \cdot \vec{v}_2}{ \| \vec{v}_2 \| ^2} \right) \vec{v}_2\\ \vdots \\ \vec{v}_{n} & = \vec{u}_{n} - \left( \dfrac{\vec{u}_n \cdot \vec{v}_1}{ \| \vec{v}_1 \| ^2} \right) \vec{v}_1 - \left( \dfrac{\vec{u}_n \cdot \vec{v}_2}{ \| \vec{v}_2 \| ^2} \right) \vec{v}_2 - \cdots - \left( \dfrac{\vec{u}_{n} \cdot \vec{v}_{n-1}}{ \| \vec{v}_{n-1} \| ^2} \right) \vec{v}_{n-1} \\ \end{array}\nonumber \]
II: Now let \(\vec{w}_i = \dfrac{\vec{v}_i}{ \| \vec{v}_i \| }\) for \(i=1, \cdots ,n\).
Then
- \(\left\{ \vec{v}_1, \cdots, \vec{v}_n \right\}\) is an orthogonal set.
- \(\left\{ \vec{w}_1,\cdots , \vec{w}_n \right\}\) is an orthonormal set.
- \(\mathrm{span}\left\{ \vec{u}_1,\cdots ,\vec{u}_n \right\} = \mathrm{span} \left\{ \vec{v}_1, \cdots, \vec{v}_n \right\} = \mathrm{span}\left\{ \vec{w}_1,\cdots ,\vec{w}_n \right\}\).
Solution
The full proof of this algorithm is beyond this material, however here is an indication of the arguments.
To show that \(\left\{ \vec{v}_1,\cdots , \vec{v}_n \right\}\) is an orthogonal set, let \[a_2 = \dfrac{ \vec{u}_2 \cdot \vec{v}_1}{ \| \vec{v}_1 \| ^2}\nonumber \] then: \[\begin{array}{ll} \vec{v}_1 \cdot \vec{v}_2 & = \vec{v}_1 \cdot \left( \vec{u}_2 - a_2 \vec{v}_1 \right) \\ & = \vec{v}_1 \cdot \vec{u}_2 - a_2 (\vec{v}_1 \cdot \vec{v}_1 \\ & = \vec{v}_1 \cdot \vec{u}_2 - \dfrac{ \vec{u}_2 \cdot \vec{v}_1}{ \| \vec{v}_1 \| ^2} \| \vec{v}_1 \| ^2 \\ & = ( \vec{v}_1 \cdot \vec{u}_2 ) - ( \vec{u}_2 \cdot \vec{v}_1 ) =0\\ \end{array}\nonumber \] Now that you have shown that \(\{ \vec{v}_1, \vec{v}_2\}\) is orthogonal, use the same method as above to show that \(\{ \vec{v}_1, \vec{v}_2, \vec{v}_3\}\) is also orthogonal, and so on.
Then in a similar fashion you show that \(\mathrm{span}\left\{ \vec{u}_1,\cdots ,\vec{u}_n \right\} = \mathrm{span}\left\{ \vec{v}_1,\cdots ,\vec{v}_n \right\}\).
Finally defining \(\vec{w}_i = \dfrac{\vec{v}_i}{ \| \vec{v}_i \| }\) for \(i=1, \cdots ,n\) does not affect orthogonality and yields vectors of length 1, hence an orthonormal set. You can also observe that it does not affect the span either and the proof would be complete.
Consider the following example.
Consider the set of vectors \(\{\vec{u}_1, \vec{u}_2\}\) given as in Example \(\PageIndex{1}\). That is \[\vec{u}_1=\left[ \begin{array}{r} 1 \\ 1 \\ 0 \end{array} \right], \vec{u}_2=\left[ \begin{array}{r} 3 \\ 2 \\ 0 \end{array} \right] \in \mathbb{R}^{3}\nonumber \]
Use the Gram-Schmidt algorithm to find an orthonormal set of vectors \(\{\vec{w}_1, \vec{w}_2\}\) having the same span.
Solution
We already remarked that the set of vectors in \(\{\vec{u}_1, \vec{u}_2\}\) is linearly independent, so we can proceed with the Gram-Schmidt algorithm: \[\begin{aligned} \vec{v}_1 &= \vec{u}_1 = \left[ \begin{array}{r} 1 \\ 1 \\ 0 \end{array} \right] \\ \vec{v}_{2} &= \vec{u}_{2} - \left( \dfrac{\vec{u}_2 \cdot \vec{v}_1}{ \| \vec{v}_1 \| ^2} \right) \vec{v}_1\\ &= \left[ \begin{array}{r} 3 \\ 2 \\ 0 \end{array} \right] - \frac{5}{2} \left[ \begin{array}{r} 1 \\ 1 \\ 0 \end{array} \right] \\ &= \left[ \begin{array}{r} \frac{1}{2} \\ - \frac{1}{2} \\ 0 \end{array} \right] \end{aligned}\]
Now to normalize simply let \[\begin{aligned} \vec{w}_1 &= \frac{\vec{v}_1}{ \| \vec{v}_1 \| } = \left[ \begin{array}{r} \frac{1}{\sqrt{2}} \\ \frac{1}{\sqrt{2}} \\ 0 \end{array} \right] \\ \vec{w}_2 &= \frac{\vec{v}_2}{ \| \vec{v}_2 \| } = \left[ \begin{array}{r} \frac{1}{\sqrt{2}} \\ - \frac{1}{\sqrt{2}} \\ 0 \end{array} \right]\end{aligned}\]
You can verify that \(\{\vec{w}_1, \vec{w}_2\}\) is an orthonormal set of vectors having the same span as \(\{\vec{u}_1, \vec{u}_2\}\), namely the \(XY\)-plane.
In this example, we began with a linearly independent set and found an orthonormal set of vectors which had the same span. It turns out that if we start with a basis of a subspace and apply the Gram-Schmidt algorithm, the result will be an orthogonal basis of the same subspace. We examine this in the following example.
Let \[\vec{x}_1=\left[\begin{array}{c} 1\\ 0\\ 1\\ 0 \end{array}\right], \vec{x}_2=\left[\begin{array}{c} 1\\ 0\\ 1\\ 1 \end{array}\right], \mbox{ and } \vec{x}_3=\left[\begin{array}{c} 1\\ 1\\ 0\\ 0 \end{array}\right],\nonumber \] and let \(U=\mathrm{span}\{\vec{x}_1, \vec{x}_2,\vec{x}_3\}\). Use the Gram-Schmidt Process to construct an orthogonal basis \(B\) of \(U\).
Solution
First \(\vec{f}_1=\vec{x}_1\).
Next, \[\vec{f}_2=\left[\begin{array}{c} 1\\ 0\\ 1\\ 1 \end{array}\right] -\frac{2}{2}\left[\begin{array}{c} 1\\ 0\\ 1\\ 0 \end{array}\right] =\left[\begin{array}{c} 0\\ 0\\ 0\\ 1 \end{array}\right].\nonumber \]
Finally, \[\vec{f}_3=\left[\begin{array}{c} 1\\ 1\\ 0\\ 0 \end{array}\right] -\frac{1}{2}\left[\begin{array}{c} 1\\ 0\\ 1\\ 0 \end{array}\right] -\frac{0}{1}\left[\begin{array}{c} 0\\ 0\\ 0\\ 1 \end{array}\right] =\left[\begin{array}{c} 1/2\\ 1\\ -1/2\\ 0 \end{array}\right].\nonumber \]
Therefore, \[\left\{ \left[\begin{array}{c} 1\\ 0\\ 1\\ 0 \end{array}\right], \left[\begin{array}{c} 0\\ 0\\ 0\\ 1 \end{array}\right], \left[\begin{array}{c} 1/2\\ 1\\ -1/2\\ 0 \end{array}\right] \right\}\nonumber \] is an orthogonal basis of \(U\). However, it is sometimes more convenient to deal with vectors having integer entries, in which case we take \[B=\left\{ \left[\begin{array}{c} 1\\ 0\\ 1\\ 0 \end{array}\right], \left[\begin{array}{c} 0\\ 0\\ 0\\ 1 \end{array}\right], \left[\begin{array}{r} 1\\ 2\\ -1\\ 0 \end{array}\right] \right\}.\nonumber \]
Orthogonal Projections
An important use of the Gram-Schmidt Process is in orthogonal projections, the focus of this section.
You may recall that a subspace of \(\mathbb{R}^n\) is a set of vectors which contains the zero vector, and is closed under addition and scalar multiplication. Let’s call such a subspace \(W\). In particular, a plane in \(\mathbb{R}^n\) which contains the origin, \(\left(0,0, \cdots, 0 \right)\), is a subspace of \(\mathbb{R}^n\).
Suppose a point \(Y\) in \(\mathbb{R}^n\) is not contained in \(W\), then what point \(Z\) in \(W\) is closest to \(Y\)? Using the Gram-Schmidt Process, we can find such a point. Let \(\vec{y}, \vec{z}\) represent the position vectors of the points \(Y\) and \(Z\) respectively, with \(\vec{y}-\vec{z}\) representing the vector connecting the two points \(Y\) and \(Z\). It will follow that if \(Z\) is the point on \(W\) closest to \(Y\), then \(\vec{y} - \vec{z}\) will be perpendicular to \(W\) (can you see why?); in other words, \(\vec{y} - \vec{z}\) is orthogonal to \(W\) (and to every vector contained in \(W\)) as in the following diagram.
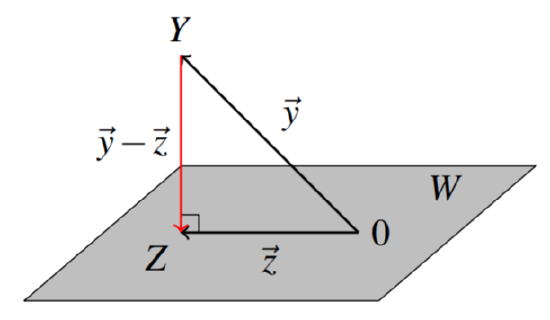
The vector \(\vec{z}\) is called the orthogonal projection of \(\vec{y}\) on \(W\). The definition is given as follows.
Let \(W\) be a subspace of \(\mathbb{R}^n\), and \(Y\) be any point in \(\mathbb{R}^n\). Then the orthogonal projection of \(Y\) onto \(W\) is given by \[\vec{z} = \mathrm{proj}_{W}\left( \vec{y}\right) = \left( \frac{\vec{y} \cdot \vec{w}_1}{ \| \vec{w}_1 \| ^2}\right) \vec{w}_1 + \left( \frac{\vec{y} \cdot \vec{w}_2}{ \| \vec{w}_2 \| ^2}\right) \vec{w}_2 + \cdots + \left( \frac{\vec{y} \cdot \vec{w}_m}{ \| \vec{w}_m \| ^2}\right) \vec{w}_m\nonumber \] where \(\{\vec{w}_1, \vec{w}_2, \cdots, \vec{w}_m \}\) is any orthogonal basis of \(W\).
Therefore, in order to find the orthogonal projection, we must first find an orthogonal basis for the subspace. Note that one could use an orthonormal basis, but it is not necessary in this case since as you can see above the normalization of each vector is included in the formula for the projection.
Before we explore this further through an example, we show that the orthogonal projection does indeed yield a point \(Z\) (the point whose position vector is the vector \(\vec{z}\) above) which is the point of \(W\) closest to \(Y\).
Let \(W\) be a subspace of \(\mathbb{R}^n\) and \(Y\) any point in \(\mathbb{R}^n\). Let \(Z\) be the point whose position vector is the orthogonal projection of \(Y\) onto \(W\).
Then, \(Z\) is the point in \(W\) closest to \(Y\).
- Proof
-
First \(Z\) is certainly a point in \(W\) since it is in the span of a basis of \(W\).
To show that \(Z\) is the point in \(W\) closest to \(Y\), we wish to show that \(|\vec{y}-\vec{z}_1| > |\vec{y}-\vec{z}|\) for all \(\vec{z}_1 \neq \vec{z} \in W\). We begin by writing \(\vec{y}-\vec{z}_1 = (\vec{y} - \vec{z}) + (\vec{z} - \vec{z}_1)\). Now, the vector \(\vec{y} - \vec{z}\) is orthogonal to \(W\), and \(\vec{z} - \vec{z}_1\) is contained in \(W\). Therefore these vectors are orthogonal to each other. By the Pythagorean Theorem, we have that \[ \| \vec{y} - \vec{z}_1 \| ^2 = \| \vec{y} - \vec{z} \| ^2 + \| \vec{z} -\vec{z}_1 \| ^2 > \| \vec{y} - \vec{z} \| ^2\nonumber \] This follows because \(\vec{z} \neq \vec{z}_1\) so \( \| \vec{z} -\vec{z}_1 \| ^2 > 0.\)
Hence, \( \| \vec{y} - \vec{z}_1 \| ^2 > \| \vec{y} - \vec{z} \| ^2\). Taking the square root of each side, we obtain the desired result.
Consider the following example.
Let \(W\) be the plane through the origin given by the equation \(x - 2y + z = 0\). Find the point in \(W\) closest to the point \(Y = (1,0,3)\).
Solution
We must first find an orthogonal basis for \(W\). Notice that \(W\) is characterized by all points \((a,b,c)\) where \(c = 2b-a\). In other words, \[W = \left[ \begin{array}{c} a \\ b \\ 2b - a \end{array} \right] = a \left[ \begin{array}{c} 1 \\ 0 \\ -1 \end{array} \right] + b \left[ \begin{array}{c} 0 \\ 1 \\ 2 \end{array} \right], \; a,b \in \mathbb{R}\nonumber \]
We can thus write \(W\) as \[\begin{aligned} W &= \mbox{span} \left\{ \vec{u}_1, \vec{u}_2 \right\} \\ &= \mbox{span} \left\{ \left[ \begin{array}{r} 1 \\ 0 \\ -1 \end{array} \right], \left[ \begin{array}{c} 0 \\ 1 \\ 2 \end{array} \right] \right\}\end{aligned}\]
Notice that this span is a basis of \(W\) as it is linearly independent. We will use the Gram-Schmidt Process to convert this to an orthogonal basis, \(\left\{\vec{w}_1, \vec{w}_2 \right\}\). In this case, as we remarked it is only necessary to find an orthogonal basis, and it is not required that it be orthonormal.
\[\vec{w}_1 = \vec{u}_1 = \left[ \begin{array}{r} 1 \\ 0 \\ -1 \end{array} \right]\nonumber \] \[\begin{aligned} \vec{w}_2 &= \vec{u}_2 - \left( \frac{ \vec{u}_2 \cdot \vec{w}_1}{ \| \vec{w}_1 \| ^2} \right) \vec{w}_1\\ &= \left[ \begin{array}{c} 0 \\ 1 \\ 2 \end{array} \right] - \left( \frac{-2}{2}\right) \left[ \begin{array}{r} 1 \\ 0 \\ -1 \end{array} \right] \\ &= \left[ \begin{array}{c} 0 \\ 1 \\ 2 \end{array} \right] + \left[ \begin{array}{r} 1 \\ 0 \\ -1 \end{array} \right] \\ &= \left[ \begin{array}{c} 1 \\ 1 \\ 1 \end{array} \right]\end{aligned}\]
Therefore an orthogonal basis of \(W\) is \[\left\{ \vec{w}_1, \vec{w}_2 \right\} = \left\{ \left[ \begin{array}{r} 1 \\ 0 \\ -1 \end{array} \right], \left[ \begin{array}{c} 1 \\ 1 \\ 1 \end{array} \right] \right\}\nonumber \]
We can now use this basis to find the orthogonal projection of the point \(Y=(1,0,3)\) on the subspace \(W\). We will write the position vector \(\vec{y}\) of \(Y\) as \(\vec{y} = \left[ \begin{array}{c} 1 \\ 0 \\ 3 \end{array} \right]\). Using Definition \(\PageIndex{8}\), we compute the projection as follows: \[\begin{aligned} \vec{z} &= \mathrm{proj}_{W}\left( \vec{y}\right)\\ &= \left( \frac{\vec{y} \cdot \vec{w}_1}{ \| \vec{w}_1 \| ^2}\right) \vec{w}_1 + \left( \frac{\vec{y} \cdot \vec{w}_2}{ \| \vec{w}_2 \| ^2}\right) \vec{w}_2 \\ &= \left( \frac{-2}{2} \right) \left[ \begin{array}{r} 1 \\ 0 \\ -1 \end{array} \right] + \left( \frac{4}{3} \right) \left[ \begin{array}{c} 1 \\ 1 \\ 1 \end{array} \right] \\ &= \left[ \begin{array}{c} \frac{1}{3} \\ \frac{4}{3} \\ \frac{7}{3} \end{array} \right]\end{aligned}\]
Therefore the point \(Z\) on \(W\) closest to the point \((1,0,3)\) is \(\left( \frac{1}{3}, \frac{4}{3}, \frac{7}{3} \right)\).
Recall that the vector \(\vec{y} - \vec{z}\) is perpendicular (orthogonal) to all the vectors contained in the plane \(W\). Using a basis for \(W\), we can in fact find all such vectors which are perpendicular to \(W\). We call this set of vectors the orthogonal complement of \(W\) and denote it \(W^{\perp}\).
Let \(W\) be a subspace of \(\mathbb{R}^n\). Then the orthogonal complement of \(W\), written \(W^{\perp}\), is the set of all vectors \(\vec{x}\) such that \(\vec{x} \cdot \vec{z} = 0\) for all vectors \(\vec{z}\) in \(W\). \[W^{\perp} = \{ \vec{x} \in \mathbb{R}^n \; \mbox{such that} \; \vec{x} \cdot \vec{z} = 0 \; \mbox{for all} \; \vec{z} \in W \}\nonumber \]
The orthogonal complement is defined as the set of all vectors which are orthogonal to all vectors in the original subspace. It turns out that it is sufficient that the vectors in the orthogonal complement be orthogonal to a spanning set of the original space.
Let \(W\) be a subspace of \(\mathbb{R}^n\) such that \(W = \mathrm{span} \left\{ \vec{w}_1, \vec{w}_2, \cdots, \vec{w}_m \right\}\). Then \(W^{\perp}\) is the set of all vectors which are orthogonal to each \(\vec{w}_i\) in the spanning set.
The following proposition demonstrates that the orthogonal complement of a subspace is itself a subspace.
Let \(W\) be a subspace of \(\mathbb{R}^n\). Then the orthogonal complement \(W^{\perp}\) is also a subspace of \(\mathbb{R}^n\).
Consider the following proposition.
The complement of \(\mathbb{R}^n\) is the set containing the zero vector: \[(\mathbb{R}^n)^{\perp} = \left\{ \vec{0} \right\}\nonumber \] Similarly, \[\left\{ \vec{0} \right\}^{\perp} = (\mathbb{R}^n). \nonumber \]
- Proof
-
Here, \(\vec{0}\) is the zero vector of \(\mathbb{R}^n\). Since \(\vec{x}\cdot\vec{0}=0\) for all \(\vec{x}\in\mathbb{R}^n\), \(\mathbb{R}^n\subseteq\{ \vec{0}\}^{\perp}\). Since \(\{ \vec{0}\}^{\perp}\subseteq\mathbb{R}^n\), the equality follows, i.e., \(\{ \vec{0}\}^{\perp}=\mathbb{R}^n\).
Again, since \(\vec{x}\cdot\vec{0}=0\) for all \(\vec{x}\in\mathbb{R}^n\), \(\vec{0}\in (\mathbb{R}^n)^{\perp}\), so \(\{ \vec{0}\}\subseteq(\mathbb{R}^n)^{\perp}\). Suppose \(\vec{x}\in\mathbb{R}^n\), \(\vec{x}\neq\vec{0}\). Since \(\vec{x}\cdot\vec{x}=||\vec{x}||^2\) and \(\vec{x}\neq\vec{0}\), \(\vec{x}\cdot\vec{x}\neq 0\), so \(\vec{x}\not\in(\mathbb{R}^n)^{\perp}\). Therefore \((\mathbb{R}^n)^{\perp}\subseteq \{\vec{0}\}\), and thus \((\mathbb{R}^n)^{\perp}=\{\vec{0}\}\).
In the next example, we will look at how to find \(W^{\perp}\).
Let \(W\) be the plane through the origin given by the equation \(x - 2y + z = 0\). Find a basis for the orthogonal complement of \(W\).
Solution
From Example \(\PageIndex{11}\) we know that we can write \(W\) as \[W = \mbox{span} \left\{ \vec{u}_1, \vec{u}_2 \right\} = \mbox{span} \left\{ \left[ \begin{array}{r} 1 \\ 0 \\ -1 \end{array} \right], \left[ \begin{array}{c} 0 \\ 1 \\ 2 \end{array} \right] \right\}\nonumber \]
In order to find \(W^{\perp}\), we need to find all \(\vec{x}\) which are orthogonal to every vector in this span.
Let \(\vec{x} = \left[ \begin{array}{c} x_1 \\ x_2 \\ x_3 \end{array} \right]\). In order to satisfy \(\vec{x} \cdot \vec{u}_1 = 0\), the following equation must hold. \[x_1 - x_3 = 0\nonumber \]
In order to satisfy \(\vec{x} \cdot \vec{u}_2 = 0\), the following equation must hold. \[x_2 + 2x_3 = 0\nonumber \]
Both of these equations must be satisfied, so we have the following system of equations. \[\begin{array}{c} x_1 - x_3 = 0 \\ x_2 + 2x_3 = 0 \end{array}\nonumber \]
To solve, set up the augmented matrix.
\[\left[ \begin{array}{rrr|r} 1 & 0 & -1 & 0 \\ 0 & 1 & 2 & 0 \end{array} \right]\nonumber \]
Using Gaussian Elimination, we find that \(W^{\perp} = \mbox{span} \left\{ \left[ \begin{array}{r} 1 \\ -2 \\ 1 \end{array} \right] \right\}\), and hence \(\left\{ \left[ \begin{array}{r} 1 \\ -2 \\ 1 \end{array} \right] \right\}\) is a basis for \(W^{\perp}\).
The following results summarize the important properties of the orthogonal projection.
Let \(W\) be a subspace of \(\mathbb{R}^n\), \(Y\) be any point in \(\mathbb{R}^n\), and let \(Z\) be the point in \(W\) closest to \(Y\). Then,
- The position vector \(\vec{z}\) of the point \(Z\) is given by \(\vec{z} = \mathrm{proj}_{W}\left( \vec{y}\right)\)
- \(\vec{z} \in W\) and \(\vec{y} - \vec{z} \in W^{\perp}\)
- \(| Y - Z | < | Y - Z_1 |\) for all \(Z_1 \neq Z \in W\)
Consider the following example of this concept.
Let \[\vec{x}_1=\left[\begin{array}{c} 1\\ 0\\ 1\\ 0 \end{array}\right], \vec{x}_2=\left[\begin{array}{c} 1\\ 0\\ 1\\ 1 \end{array}\right], \vec{x}_3=\left[\begin{array}{c} 1\\ 1\\ 0\\ 0 \end{array}\right], \mbox{ and } \vec{v}=\left[\begin{array}{c} 4\\ 3\\ -2\\ 5 \end{array}\right].\nonumber \] We want to find the vector in \(W =\mathrm{span}\{\vec{x}_1, \vec{x}_2,\vec{x}_3\}\) closest to \(\vec{y}\).
Solution
We will first use the Gram-Schmidt Process to construct the orthogonal basis, \(B\), of \(W\): \[B=\left\{ \left[\begin{array}{c} 1\\ 0\\ 1\\ 0 \end{array}\right], \left[\begin{array}{c} 0\\ 0\\ 0\\ 1 \end{array}\right], \left[\begin{array}{r} 1\\ 2\\ -1\\ 0 \end{array}\right] \right\}.\nonumber \]
By Theorem \(\PageIndex{4}\), \[\mathrm{proj}_U(\vec{v}) = \frac{2}{2} \left[\begin{array}{c} 1\\ 0\\ 1\\ 0 \end{array}\right] + \frac{5}{1}\left[\begin{array}{c} 0\\ 0\\ 0\\ 1 \end{array}\right] + \frac{12}{6}\left[\begin{array}{r} 1\\ 2\\ -1\\ 0 \end{array}\right] = \left[\begin{array}{r} 3\\ 4\\ -1\\ 5 \end{array}\right]\nonumber \] is the vector in \(U\) closest to \(\vec{y}\).
Consider the next example.
Let \(W\) be a subspace given by \(W = \mbox{span} \left\{ \left[ \begin{array}{c} 1 \\ 0 \\ 1 \\ 0 \\ \end{array} \right], \left[ \begin{array}{c} 0 \\ 1 \\ 0 \\ 2 \\ \end{array} \right] \right\}\), and \(Y = (1,2,3,4)\).
Find the point \(Z\) in \(W\) closest to \(Y\), and moreover write \(\vec{y}\) as the sum of a vector in \(W\) and a vector in \(W^{\perp}\).
Solution
From Theorem \(\PageIndex{3}\) the point \(Z\) in \(W\) closest to \(Y\) is given by \(\vec{z} = \mathrm{proj}_{W}\left( \vec{y}\right)\).
Notice that since the above vectors already give an orthogonal basis for \(W\), we have:
\[\begin{aligned} \vec{z} &= \mathrm{proj}_{W}\left( \vec{y}\right)\\ &= \left( \frac{\vec{y} \cdot \vec{w}_1}{ \| \vec{w}_1 \| ^2}\right) \vec{w}_1 + \left( \frac{\vec{y} \cdot \vec{w}_2}{ \| \vec{w}_2 \| ^2}\right) \vec{w}_2 \\ &= \left( \frac{4}{2} \right) \left[ \begin{array}{c} 1 \\ 0 \\ 1 \\ 0 \end{array} \right] + \left( \frac{10}{5} \right) \left[ \begin{array}{c} 0 \\ 1 \\ 0 \\ 2 \end{array} \right] \\ &= \left[ \begin{array}{c} 2 \\ 2 \\ 2 \\ 4 \end{array} \right]\end{aligned}\]
Therefore the point in \(W\) closest to \(Y\) is \(Z = (2,2,2,4)\).
Now, we need to write \(\vec{y}\) as the sum of a vector in \(W\) and a vector in \(W^{\perp}\). This can easily be done as follows: \[\vec{y} = \vec{z} + (\vec{y} - \vec{z})\nonumber \] since \(\vec{z}\) is in \(W\) and as we have seen \(\vec{y} - \vec{z}\) is in \(W^{\perp}\).
The vector \(\vec{y} - \vec{z}\) is given by \[\vec{y} - \vec{z} = \left[ \begin{array}{c} 1 \\ 2 \\ 3 \\ 4 \end{array} \right] - \left[ \begin{array}{c} 2 \\ 2 \\ 2 \\ 4 \end{array} \right] = \left[ \begin{array}{r} -1 \\ 0 \\ 1 \\ 0 \end{array} \right]\nonumber \] Therefore, we can write \(\vec{y}\) as \[\left[ \begin{array}{c} 1 \\ 2 \\ 3 \\ 4 \end{array} \right] = \left[ \begin{array}{c} 2 \\ 2 \\ 2 \\ 4 \end{array} \right] + \left[ \begin{array}{r} -1 \\ 0 \\ 1 \\ 0 \end{array} \right]\nonumber \]
Find the point \(Z\) in the plane \(3x+y-2z=0\) that is closest to the point \(Y=(1,1,1)\).
Solution
The solution will proceed as follows.
- Find a basis \(X\) of the subspace \(W\) of \(\mathbb{R}^3\) defined by the equation \(3x+y-2z=0\).
- Orthogonalize the basis \(X\) to get an orthogonal basis \(B\) of \(W\).
- Find the projection on \(W\) of the position vector of the point \(Y\).
We now begin the solution.
- \(3x+y-2z=0\) is a system of one equation in three variables. Putting the augmented matrix in reduced row-echelon form: \[\left[\begin{array}{rrr|r} 3 & 1 & -2 & 0 \end{array}\right] \rightarrow \left[\begin{array}{rrr|r} 1 & \frac{1}{3} & -\frac{2}{3} & 0 \end{array}\right]\nonumber \] gives general solution \(x=\frac{1}{3}s+\frac{2}{3}t\), \(y=s\), \(z=t\) for any \(s,t\in\mathbb{R}\). Then \[W=\mathrm{span} \left\{ \left[\begin{array}{r} -\frac{1}{3} \\ 1 \\ 0 \end{array}\right], \left[\begin{array}{r} \frac{2}{3} \\ 0 \\ 1 \end{array}\right]\right\}\nonumber \] Let \(X=\left\{ \left[\begin{array}{r} -1 \\ 3 \\ 0 \end{array}\right], \left[\begin{array}{r} 2 \\ 0 \\ 3 \end{array}\right]\right\}\). Then \(X\) is linearly independent and \(\mathrm{span}(X)=W\), so \(X\) is a basis of \(W\).
- Use the Gram-Schmidt Process to get an orthogonal basis of \(W\): \[\vec{f}_1=\left[\begin{array}{r} -1\\3\\0\end{array}\right]\mbox{ and }\vec{f}_2=\left[\begin{array}{r}2\\0\\3\end{array}\right]-\frac{-2}{10}\left[\begin{array}{r}-1\\3\\0\end{array}\right]=\frac{1}{5}\left[\begin{array}{r}9\\3\\15\end{array}\right].\nonumber\] Therefore \(B=\left\{\left[\begin{array}{r}-1\\3\\0\end{array}\right], \left[\begin{array}{r}3\\1\\5 \end{array}\right]\right\}\) is an orthogonal basis of \(W\).
- To find the point \(Z\) on \(W\) closest to \(Y=(1,1,1)\), compute \[\begin{aligned} \mathrm{proj}_{W}\left[\begin{array}{r} 1 \\ 1 \\ 1 \end{array}\right] & = \frac{2}{10} \left[\begin{array}{r} -1 \\ 3 \\ 0 \end{array}\right] + \frac{9}{35}\left[\begin{array}{r} 3 \\ 1 \\ 5 \end{array}\right]\\ & = \frac{1}{7}\left[\begin{array}{r} 4 \\ 6 \\ 9 \end{array}\right].\end{aligned}\] Therefore, \(Z=\left( \frac{4}{7}, \frac{6}{7}, \frac{9}{7}\right)\).
Least Squares Approximation
It should not be surprising to hear that many problems do not have a perfect solution, and in these cases the objective is always to try to do the best possible. For example what does one do if there are no solutions to a system of linear equations \(A\vec{x}=\vec{b}\)? It turns out that what we do is find \(\vec{x}\) such that \(A\vec{x}\) is as close to \(\vec{b}\) as possible. A very important technique that follows from orthogonal projections is that of the least square approximation, and allows us to do exactly that.
We begin with a lemma.
Recall that we can form the image of an \(m \times n\) matrix \(A\) by \(\mathrm{im}\left( A\right) = = \left\{ A\vec{x} : \vec{x} \in \mathbb{R}^n \right\}\). Rephrasing Theorem \(\PageIndex{4}\) using the subspace \(W=\mathrm{im}\left( A\right)\) gives the equivalence of an orthogonality condition with a minimization condition. The following picture illustrates this orthogonality condition and geometric meaning of this theorem.
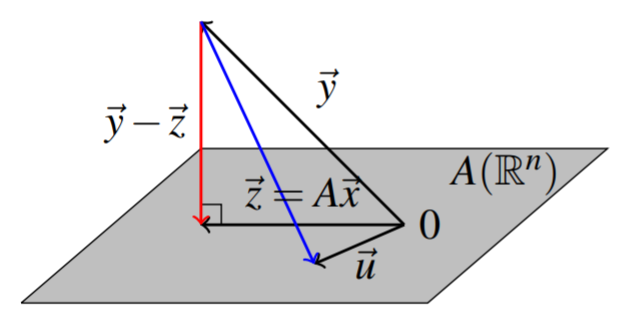
Let \(\vec{y}\in \mathbb{R}^{m}\) and let \(A\) be an \(m\times n\) matrix.
Choose \(\vec{z}\in W= \mathrm{im}\left( A\right)\) given by \(\vec{z} = \mathrm{proj}_{W}\left( \vec{y}\right)\), and let \(\vec{x} \in \mathbb{R}^{n}\) such that \(\vec{z}=A\vec{x}\).
Then
- \(\vec{y} - A\vec{x} \in W^{\perp}\)
- \( \| \vec{y} - A\vec{x} \| < \| \vec{y} - \vec{u} \| \) for all \(\vec{u} \neq \vec{z} \in W\)
We note a simple but useful observation.
Let \(A\) be an \(m\times n\) matrix. Then \[A\vec{x} \cdot \vec{y} = \vec{x}\cdot A^T\vec{y}\nonumber \]
- Proof
-
This follows from the definitions: \[A\vec{x} \cdot \vec{y}=\sum_{i,j}a_{ij}x_{j} y_{i} =\sum_{i,j}x_{j} a_{ji} y_{i}= \vec{x} \cdot A^T\vec{y}\nonumber \]
The next corollary gives the technique of least squares.
A specific value of \(\vec{x}\) which solves the problem of Theorem \(\PageIndex{5}\) is obtained by solving the equation \[A^TA\vec{x}=A^T\vec{y}\nonumber \] Furthermore, there always exists a solution to this system of equations.
- Proof
-
For \(\vec{x}\) the minimizer of Theorem \(\PageIndex{5}\), \(\left( \vec{y}-A\vec{x}\right) \cdot A \vec{u} =0\) for all \(\vec{u} \in \mathbb{R}^{n}\) and from Lemma \(\PageIndex{1}\), this is the same as saying \[A^T\left( \vec{y}-A\vec{x}\right) \cdot \vec{u}=0\nonumber \] for all \(u \in \mathbb{R}^{n}.\) This implies \[A^T\vec{y}-A^TA\vec{x}=\vec{0}.\nonumber \] Therefore, there is a solution to the equation of this corollary, and it solves the minimization problem of Theorem \(\PageIndex{5}\).
Note that \(\vec{x}\) might not be unique but \(A\vec{x}\), the closest point of \(A\left(\mathbb{R}^{n}\right)\) to \(\vec{y}\) is unique as was shown in the above argument.
Consider the following example.
Find a least squares solution to the system \[\left[ \begin{array}{rr} 2 & 1 \\ -1 & 3 \\ 4 & 5 \end{array} \right] \left[ \begin{array}{c} x \\ y \end{array} \right] =\left[ \begin{array}{c} 2 \\ 1 \\ 1 \end{array} \right]\nonumber \]
Solution
First, consider whether there exists a real solution. To do so, set up the augmnented matrix given by \[\left[ \begin{array}{rr|r} 2 & 1 & 2 \\ -1 & 3 & 1 \\ 4 & 5 & 1 \end{array} \right]\nonumber \] The reduced row-echelon form of this augmented matrix is \[\left[ \begin{array}{rr|r} 1 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \end{array} \right]\nonumber \]
It follows that there is no real solution to this system. Therefore we wish to find the least squares solution. The normal equations are \[\begin{aligned} A^T A \vec{x} &= A^T \vec{y} \\ \left[ \begin{array}{rrr} 2 & -1 & 4 \\ 1 & 3 & 5 \end{array} \right] \left[ \begin{array}{rr} 2 & 1 \\ -1 & 3 \\ 4 & 5 \end{array} \right] \left[ \begin{array}{c} x \\ y \end{array} \right] &=\left[ \begin{array}{rrr} 2 & -1 & 4 \\ 1 & 3 & 5 \end{array} \right] \left[ \begin{array}{c} 2 \\ 1 \\ 1 \end{array} \right]\end{aligned}\] and so we need to solve the system \[\left[ \begin{array}{rr} 21 & 19 \\ 19 & 35 \end{array} \right] \left[ \begin{array}{c} x \\ y \end{array} \right] =\left[ \begin{array}{r} 7 \\ 10 \end{array} \right]\nonumber \] This is a familiar exercise and the solution is \[\left[ \begin{array}{c} x \\ y \end{array} \right] =\left[ \begin{array}{c} \frac{5}{34} \\ \frac{7}{34} \end{array} \right]\nonumber \]
Consider another example.
Find a least squares solution to the system \[\left[ \begin{array}{rr} 2 & 1 \\ -1 & 3 \\ 4 & 5 \end{array} \right] \left[ \begin{array}{c} x \\ y \end{array} \right] =\left[ \begin{array}{c} 3 \\ 2 \\ 9 \end{array} \right]\nonumber \]
Solution
First, consider whether there exists a real solution. To do so, set up the augmnented matrix given by \[\left[ \begin{array}{rr|r} 2 & 1 & 3 \\ -1 & 3 & 2 \\ 4 & 5 & 9 \end{array} \right]\nonumber\] The reduced row-echelon form of this augmented matrix is \[\left[ \begin{array}{rr|r} 1 & 0 & 1 \\ 0 & 1 & 1 \\ 0 & 0 & 0 \end{array} \right]\nonumber \]
It follows that the system has a solution given by \(x=y=1\). However we can also use the normal equations and find the least squares solution. \[\left[ \begin{array}{rrr} 2 & -1 & 4 \\ 1 & 3 & 5 \end{array} \right] \left[ \begin{array}{rr} 2 & 1 \\ -1 & 3 \\ 4 & 5 \end{array} \right] \left[ \begin{array}{c} x \\ y \end{array} \right] =\left[ \begin{array}{rrr} 2 & -1 & 4 \\ 1 & 3 & 5 \end{array} \right] \left[ \begin{array}{r} 3 \\ 2 \\ 9 \end{array} \right]\nonumber \] Then \[\left[ \begin{array}{rr} 21 & 19 \\ 19 & 35 \end{array} \right] \left[ \begin{array}{c} x \\ y \end{array} \right] =\left[ \begin{array}{c} 40 \\ 54 \end{array} \right]\nonumber \]
The least squares solution is \[\left[ \begin{array}{c} x \\ y \end{array} \right] =\left[ \begin{array}{c} 1 \\ 1 \end{array} \right]\nonumber \] which is the same as the solution found above.
An important application of Corollary \(\PageIndex{1}\) is the problem of finding the least squares regression line in statistics. Suppose you are given points in the \(xy\) plane \[\left\{ \left( x_{1},y_{1}\right), \left( x_{2},y_{2}\right), \cdots, \left( x_{n},y_{n}\right) \right\}\nonumber \] and you would like to find constants \(m\) and \(b\) such that the line \(\vec{y}=m\vec{x}+b\) goes through all these points. Of course this will be impossible in general. Therefore, we try to find \(m,b\) such that the line will be as close as possible. The desired system is
\[\left[ \begin{array}{c} y_{1} \\ \vdots \\ y_{n} \end{array} \right] =\left[ \begin{array}{cc} x_{1} & 1 \\ \vdots & \vdots \\ x_{n} & 1 \end{array} \right] \left[ \begin{array}{c} m \\ b \end{array} \right]\nonumber \]
which is of the form \(\vec{y}=A\vec{x}\). It is desired to choose \(m\) and \(b\) to make
\[\left \| A\left[ \begin{array}{c} m \\ b \end{array} \right] -\left[ \begin{array}{c} y_{1} \\ \vdots \\ y_{n} \end{array} \right] \right \| ^{2}\nonumber \]
as small as possible. According to Theorem \(\PageIndex{5}\) and Corollary \(\PageIndex{1}\), the best values for \(m\) and \(b\) occur as the solution to
\[A^{T}A\left[ \begin{array}{c} m \\ b \end{array} \right] =A^{T}\left[ \begin{array}{c} y_{1} \\ \vdots \\ y_{n} \end{array} \right] ,\ \;\mbox{where}\; A=\left[ \begin{array}{cc} x_{1} & 1 \\ \vdots & \vdots \\ x_{n} & 1 \end{array} \right]\nonumber \]
Thus, computing \(A^{T}A,\)
\[\left[ \begin{array}{cc} \sum_{i=1}^{n}x_{i}^{2} & \sum_{i=1}^{n}x_{i} \\ \sum_{i=1}^{n}x_{i} & n \end{array} \right] \left[ \begin{array}{c} m \\ b \end{array} \right] =\left[ \begin{array}{c} \sum_{i=1}^{n}x_{i}y_{i} \\ \sum_{i=1}^{n}y_{i} \end{array} \right]\nonumber \]
Solving this system of equations for \(m\) and \(b\) (using Cramer’s rule for example) yields:
\[m= \frac{-\left( \sum_{i=1}^{n}x_{i}\right) \left( \sum_{i=1}^{n}y_{i}\right) +\left( \sum_{i=1}^{n}x_{i}y_{i}\right) n}{\left( \sum_{i=1}^{n}x_{i}^{2}\right) n-\left( \sum_{i=1}^{n}x_{i}\right) ^{2}}\nonumber \] and \[b=\frac{-\left( \sum_{i=1}^{n}x_{i}\right) \sum_{i=1}^{n}x_{i}y_{i}+\left( \sum_{i=1}^{n}y_{i}\right) \sum_{i=1}^{n}x_{i}^{2}}{\left( \sum_{i=1}^{n}x_{i}^{2}\right) n-\left( \sum_{i=1}^{n}x_{i}\right) ^{2}}.\nonumber \]
Consider the following example.
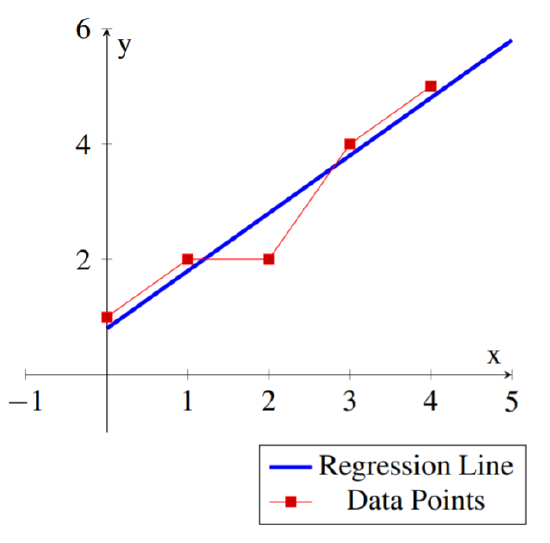
Find the least squares regression line \(\vec{y}=m\vec{x}+b\) for the following set of data points: \[\left\{ (0,1), (1,2), (2,2), (3,4), (4,5) \right\} \nonumber\]
Solution
In this case we have \(n=5\) data points and we obtain: \[\begin{array}{ll} \sum_{i=1}^{5}x_{i} = 10 & \sum_{i=1}^{5}y_{i} = 14 \\ \\ \sum_{i=1}^{5}x_{i}y_{i} = 38 & \sum_{i=1}^{5}x_{i}^{2} = 30\\ \end{array}\nonumber \] and hence \[\begin{aligned} m &= \frac{- 10 * 14 + 5*38}{5*30-10^2} = 1.00 \\ \\ b &= \frac{- 10 * 38 + 14*30}{5*30-10^2} = 0.80 \\\end{aligned}\]
The least squares regression line for the set of data points is: \[\vec{y} = \vec{x}+.8\nonumber \]
One could use this line to approximate other values for the data. For example for \(x=6\) one could use \(y(6)=6+.8=6.8\) as an approximate value for the data.
The following diagram shows the data points and the corresponding regression line.
One could clearly do a least squares fit for curves of the form \(y=ax^{2}+bx+c\) in the same way. In this case you want to solve as well as possible for \(a,b,\) and \(c\) the system \[\left[ \begin{array}{ccc} x_{1}^{2} & x_{1} & 1 \\ \vdots & \vdots & \vdots \\ x_{n}^{2} & x_{n} & 1 \end{array} \right] \left[ \begin{array}{c} a \\ b \\ c \end{array} \right] =\left[ \begin{array}{c} y_{1} \\ \vdots \\ y_{n} \end{array} \right]\nonumber \] and one would use the same technique as above. Many other similar problems are important, including many in higher dimensions and they are all solved the same way.