In the previous section we saw the important connection between linear functions and matrices. In this section we will discuss various operations on matrices which we will find useful in our later work with linear functions.
The algebra of matrices
If is an matrix with in the th row and th column, , then we will write . With this notation the definitions of addition, subtraction, and scalar multiplication for matrices are straightforward.
Definition
Suppose and are matrices and is a real number. Then we define
and
In other words, we define addition, subtraction, and scalar multiplication for matrices by performing these operations on the individual elements of the matrices, in a manner similar to the way we perform these operations on vectors.
Example
If
and
then, for example,
and
These operations have natural interpretations in terms of linear functions. Suppose and are linear with and for matrices and . If we define by
then
for . Hence the th column of the matrix which represents is the sum of the th columns of and . In other words,
for all in . Similarly, if we define by
then
If, for any scalar , we define by
then
for . Hence the th column of the matrix which represents is the scalar times the th column of . That is,
for all in . In short, the operations of addition, subtraction, and scalar multiplication for matrices corresponds in a natural way with the operations of addition, subtraction, and scalar multiplication for linear functions.
Now consider the case where and are linear functions. Let be the matrix such that for all in and let be the matrix such that for all in . Since for any in , is in , we can form , the composition of with , defined by
Now
so it would be natural to define , the product of the matrices and , to be the matrix of , in which case we would have
Thus we want the th column of , , to be
which is just the dot product of with the rows of . But is the th column of , so the th column of is formed by taking the dot product of the th column of with the rows of . In other words, the entry in the th row and th column of is the dot product of the th row of with the th column of . We write this out explicitly in the following definition.
Definition
If is an matrix and is a matrix, then we define the product of and to be the matrix , where
Note that is an matrix since . Moreover, the product of two matrices and is defined only when the number of columns of is equal to the number of rows of .
Example
If
and
then
Note that is , is , and is . Also, note that it is not possible to form the product in the other order.
Example
Let be the linear function defined by
and let be the linear function defined by
Then the matrix for is
the matrix for is
and the matrix for is
In other words,
Note that it in this case it is possible to form the composition in the other order. The matrix for is
and so
In particular, note that not only is , but in fact and are not even the same size.
Determinants
The notion of the determinant of a matrix is closely related to the idea of area and volume. To begin our definition, consider the matrix
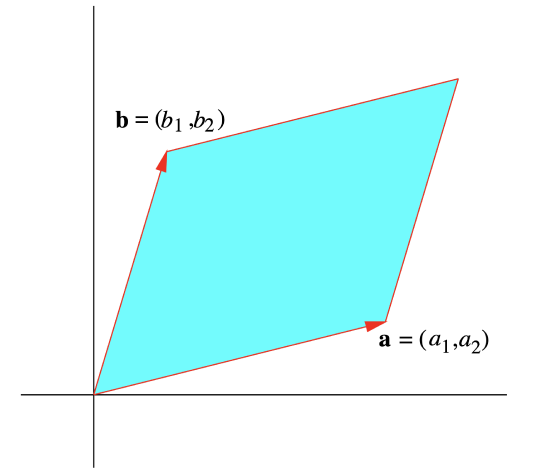
Figure : A parallelogram in with adjacent sides and
and let and . If is the parallelogram which has and for adjacent sides and is the area of (see Figure 1.6.1), then we saw in Section 1.3 that
This motivates the following definition.
Definition
Given a matrix
the determinant of , denoted det(), is
Hence we have . In words, for a matrix , the absolute value of the determinant of equals the area of the parallelogram which has the rows of for adjacent sides.
Example
We have
Now consider a matrix
and let , , and . If is the volume of the parallelepiped with adjacent edges , , and , then, again from Section 1.3,
Definition
Given a matrix
the determinant of , denoted det(), is
Similar to the case, we have .
Example
We have
Given an matrix , let be the matrix obtained by deleting the th row and th column of . If for we first define (that is, the determinant of a matrix is just the value of its single entry), then we could express, for , the definition of a the determinant of a matrix given in () in the form
Similarly, with , we could express the definition of the determinant of given in () in the form
Following this pattern, we may form a recursive definition for the determinant of an matrix.
Definition
Suppose is an matrix and let be the matrix obtained by deleting the th row and th column of , and . For , we define the determinant of , denoted , by
For , we define the determinant of , denoted , by
We call the definition recursive because we have defined the determinant of an matrix in terms of the determinants of matrices, which in turn are defined in terms of the determinants of matrices, and so on, until we have reduced the problem to computing the determinants of matrices.
Example
For an example of the determinant of a matrix, we have
The next theorem states that there is nothing special about using the first row of the matrix in the expansion of the determinant specified in (), nor is there anything special about expanding along a row instead of a column. The practical effect is that we may compute the determinant of a given matrix expanding along whichever row or column is most convenient. The proof of this theorem would take us too far afield at this point, so we will omit it (but you will be asked to verify the theorem for the special cases and in Exercise 10).
Theorem
Let be an matrix and let be the matrix obtained by deleting the th row and th column of . Then for any ,
and for any ,
Example
The simplest way to compute the determinant of the matrix
is to expand along the second column. Namely,
You should verify that expanding along the first row, as we did in the definition of the determinant, gives the same result.
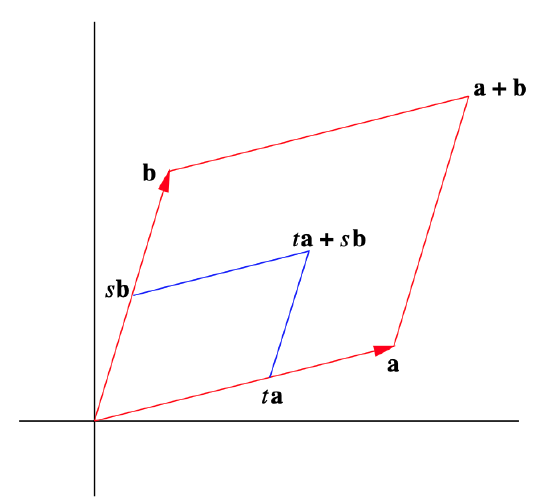
In order to return to the problem of computing volumes, we need to define a parallelepiped in . First note that if is a parallelogram in with adjacent sides given by the vectors and , then
That is, for , is a point between and , and for , is a point between and ; hence is a point in the parallelogram . Moreover, every point in may be expressed in this form. See Figure 1.6.2. The following definition generalizes this characterization of parallelograms.
Figure : A parallelogram in with adjacent sides and
Definition
Let be linearly independent vectors in . We call
an n-dimensional parallelepiped with adjacent edges .
Definition
Let be an n-dimensional parallelepiped with adjacent edges and let be the matrix which has for its rows. Then the volume of is defined to be .
It may be shown, using () and induction, that if is the matrix obtained by interchanging the rows and columns of an matrix , then (see Exercise 12). Thus we could have defined in the previous definition using for columns rather than rows.
Now suppose is linear and let be the matrix such that for all in . Let be the -dimensional parallelepiped with adjacent edges , the standard basis vectors for . Then is a square when and a cube when . In general, we may think of as an -dimensional unit cube. Note that the volume of is, by definition,
Suppose are linearly independent and let be the -dimensional parallelepiped with adjacent edges . Note that if
where for , is a point in , then
is a point in . In fact, maps the n-dimensional unit cube exactly onto the -dimensional parallelepiped . Since are the columns of , it follows that the volume of equals . In other words, measures how much stretches or shrinks the volume of a unit cube.
Theorem
Suppose is linear and is the matrix such that . If are linear independent and is the -dimensional parallelepiped with adjacent edges , then the volume of is equal to .